一种基于机器学习的生物炭吸附率预测方法及系统
本发明属于生物炭吸附率预测,具体涉及一种基于机器学习的生物炭吸附率预测方法及系统。
背景技术:
1、生物炭是农林废弃物等生物质在缺氧条件下热裂解形成的一种富碳产物,具有较大的比表面积、较高的离子交换量以及丰富的化学官能团,可以通过物理化学行为负载特定的肥料养分。不同的制备材料制备得到的生物炭,其性质会对养分的固储与缓释特性产生影响。生物炭结构与性质,受到包括原料、热解温度、停留时间、升温速率等环境条件的共同影响。而不同的制备方法得到的生物炭的性能无法简单的通过实验来归纳总结。而机器学习是一种数据挖掘方法,可以通过有限的实验数据学习来挖掘系统特征,有效的预测系统的输出。
技术实现思路
1、本发明旨在提出一种基于机器学习的生物炭吸附率预测方法及系统,通过xgboost模型对各个影响参数进行排序,并采用lstm模型对其排序后的参数进行预测。
2、为实现上述目的,本发明提供了如下方案:一种基于机器学习的生物炭吸附率预测方法,包括以下步骤:
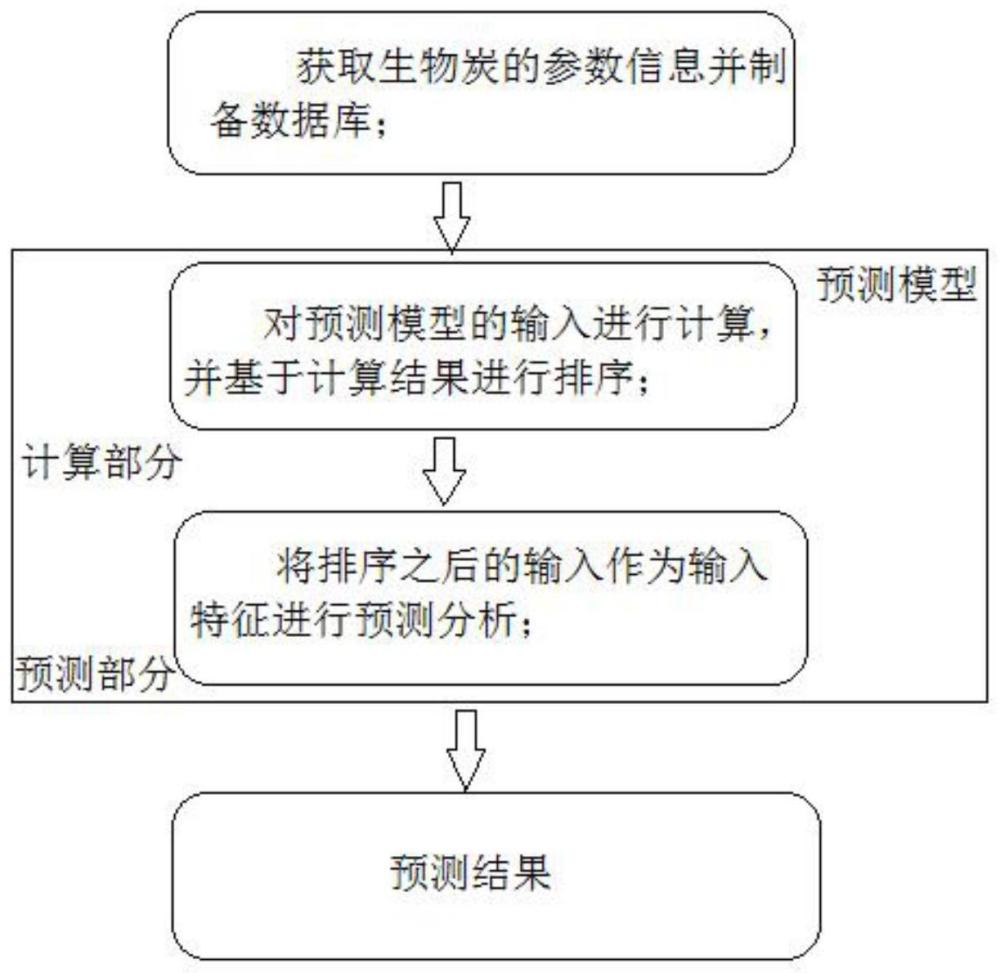
3、s1、获取生物炭的参数信息;
4、s2、构建预测模型,将所述参数信息作为输入,基于所述预测模型对生物炭吸附量进行预测,得到预测结果。
5、进一步优选地,所述参数信息包括:原料种类、原料比例、热解温度、压力、生物质分析信息以及生物炭分析信息。
6、进一步优选地,所述s1还包括:
7、s1.1、数据库制备;所述数据库用于存储训练数据,所述训练数据用于对所述预测模型进行训练优化;
8、所述数据库包括:原料参数数据库与吸附率结果数据库;
9、所述原料参数数据库用于存储所述参数信息、所述生物质分析信息以及所述生物炭分析信息。
10、进一步优选地,所述预测模型包括:计算部分以及预测部分;
11、所述计算部分用于对所述预测模型的输入进行计算,并基于计算结果进行排序;
12、所述预测部分将排序之后的所述输入作为输入特征进行预测分析,得到所述预测结果。
13、进一步优选地,所述计算部分采用xgboost模型计算所述参数信息的贡献程度;计算贡献程度的方法包括:找到与特征i相关的节点,计算所述节点在分裂前后的平方损失值;特征i在整个模型中的贡献程度通过对所有含有特征i的决策树的贡献程度求和并取平均值来衡量;对每个特征的贡献程度进行量化,完成排序。
14、本发明还提供一种基于机器学习的生物炭吸附率预测系统,包括:采集模块以及模型构建模块;
15、所述采集单元用于获取生物炭的参数信息以及制备数据库;
16、所述参数信息包括:原料种类、原料比例、热解温度、压力、生物质分析信息以及生物炭分析信息;
17、所述数据库用于存储训练数据,所述训练数据用于对所述预测模型进行训练优化;
18、所述模型构建模块用于构建预测模型,将所述参数信息作为输入,基于所述预测模型对生物炭吸附量进行预测,得到预测结果。
19、进一步优选地,所述数据库包括:原料参数数据库与吸附率结果数据库;
20、所述原料参数数据库用于存储所述参数信息、所述生物质分析信息以及所述生物炭分析信息。
21、进一步优选地,所述预测模型包括:计算部分以及预测部分;
22、所述计算部分用于对所述预测模型的输入进行计算,并基于计算结果进行排序;
23、所述预测部分将排序之后的所述输入作为输入特征进行预测分析,得到所述预测结果。
24、进一步优选地,所述计算部分采用xgboost模型计算所述参数信息的贡献程度;计算贡献程度的方法包括:找到与特征i相关的节点,计算所述节点在分裂前后的平方损失值;特征i在整个模型中的贡献程度通过对所有含有特征i的决策树的贡献程度求和并取平均值来衡量;对每个特征的贡献程度进行量化,完成排序。
25、与现有技术相比,本发明的有益效果为:
26、本发明提出的一种基于机器学习的生物炭吸附率预测方法及系统,采用xgboost模型对各个影响参数进行排序,并采用lstm模型对其排序后的参数进行预测。xgboost模型通过对gbdt模型的基础上进行改进和扩展得到的,能够将弱分类器转化为强分类器。通过将多个准确率较低的决策树模型组合成一个准确率高的模型。与gbdt模型相比,改进了损失函数和正则化,并提出了一种并行化算法。xgboost模型对损失函数进行二级泰勒展开,同时利用一阶导数和二阶导数对模型进行优化;加入正则项,用于控制模型的复杂度,降低模型的方差,防止过拟合,增强泛化能力。并行训练将已经排序完成的特征存储到block结构中,使计算量降低。
技术特征:
1.一种基于机器学习的生物炭吸附率预测方法,其特征在于,包括以下步骤:
2.根据权利要求1所述一种基于机器学习的生物炭吸附率预测方法,其特征在于,所述参数信息包括:原料种类、原料比例、热解温度、压力、生物质分析信息以及生物炭分析信息。
3.根据权利要求1所述一种基于机器学习的生物炭吸附率预测方法,其特征在于,所述s1还包括:
4.根据权利要求1所述一种基于机器学习的生物炭吸附率预测方法,其特征在于,所述预测模型包括:计算部分以及预测部分;
5.根据权利要求4所述一种基于机器学习的生物炭吸附率预测方法,其特征在于,所述计算部分采用xgboost模型计算所述参数信息的贡献程度;计算贡献程度的方法包括:找到与特征i相关的节点,计算所述节点在分裂前后的平方损失值;特征i在整个模型中的贡献程度通过对所有含有特征i的决策树的贡献程度求和并取平均值来衡量;对每个特征的贡献程度进行量化,完成排序。
6.一种基于机器学习的生物炭吸附率预测系统,所述系统用于实现权利要求1-5任一项所述的方法,其特征在于,包括:采集模块以及模型构建模块;
7.根据权利要求6所述一种基于机器学习的生物炭吸附率预测系统,其特征在于,所述数据库包括:原料参数数据库与吸附率结果数据库;
8.根据权利要求7所述一种基于机器学习的生物炭吸附率预测系统,其特征在于,所述预测模型包括:计算部分以及预测部分;
9.根据权利要求8所述一种基于机器学习的生物炭吸附率预测系统,其特征在于,所述计算部分采用xgboost模型计算所述参数信息的贡献程度;计算贡献程度的方法包括:找到与特征i相关的节点,计算所述节点在分裂前后的平方损失值;特征i在整个模型中的贡献程度通过对所有含有特征i的决策树的贡献程度求和并取平均值来衡量;对每个特征的贡献程度进行量化,完成排序。
技术总结
本发明公开了一种基于机器学习的生物炭吸附率预测方法及系统,属于生物炭吸附率预测所技术领域。方法包括:S1、获取生物炭的参数信息以及制备数据库;所述参数信息包括:原料种类、原料比例、热解温度、压力、生物质分析信息以及生物炭分析信息;所述数据库用于存储训练数据,所述训练数据用于对所述预测模型进行训练优化;S2、构建预测模型,将所述参数信息作为输入,基于所述预测模型对生物炭吸附量进行预测,得到预测结果。本发明采用XGBoost模型对各个影响参数进行排序,降低了模型的方差,防止过拟合,增强泛化能力,且降低了计算量;并采用LSTM模型对其排序后的参数进行预测。
技术研发人员:兰维娟,金鑫,卫一航,王影娴,贺智涛,丁慧玲,尹冬雪
受保护的技术使用者:河南科技大学
技术研发日:
技术公布日:2024/8/27
- 还没有人留言评论。精彩留言会获得点赞!