一种精准识别风功率异常值的清洗方法
本发明涉及风力发电数据分析与处理,特别是涉及一种精准识别风功率异常值的清洗方法。
背景技术:
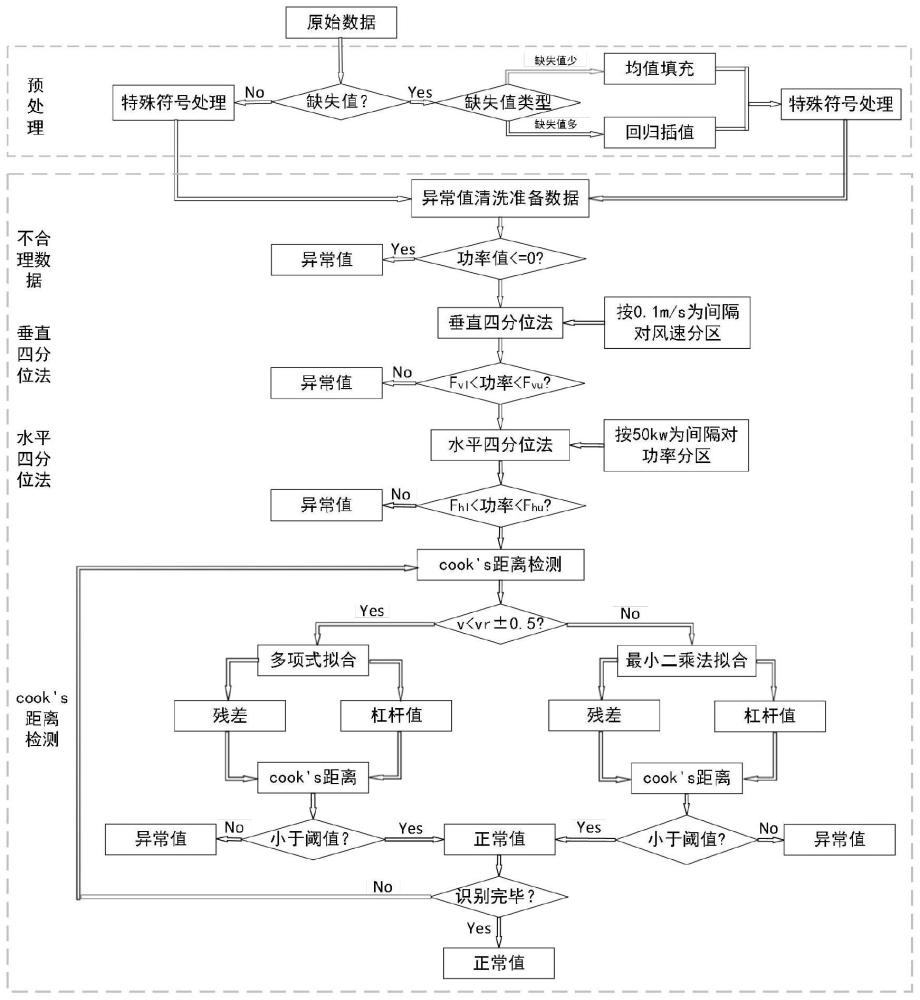
1、随着数据驱动技术在风力机行业的广泛应用,风功率数据的准确性对系统性能监控和预测至关重要。然而,风力机风功率数据往往受到风速变化、设备故障或环境干扰等多种复杂因素的影响,导致数据中存在着异常值。在实际风力机运行中会出现:①垂直堆叠异常数据、②远离功率曲线离散分布的异常数据、③跟随功率曲线分布的稀疏异常数据、④中部水平堆积异常数据、⑤底部水平堆积异常值五种异常值。这些异常值会严重影响风力机性能评估、状态检测和预测精度。
2、为了清洗这些异常值,现有方法一:一种基于粒子群参数优化得空间密度聚类方法,但是该方法只对稀疏异常值识别效果明显,对风功率分布带边缘高密度异常值不能有效识别;方法二:一种基于组内方差和概率密度的清洗方法,该方法对于风功率分布带边缘异常数据识别效果不明显,存在明显的异常值附着现象;方法三:一种基于概率密度的分区间异常值判断方法,该方法虽然实现简单,但是对于识别效果并不好,识别后的数据中存在很多如③所示的异常值;方法四:一种处理弃风异常数据的方法,但是该方法还是保留了很多如④所示的异常值。综上所述,现有的基于聚类、基于方差和概率密度异常值清洗方法风功率异常值识别效果不高,对部分和正常值性质相似但不合理的异常数据不能完全识别,而且导致异常值清洗之后的风功率分布带边缘不光滑,数据趋势一致性不高。因此,亟需一种精准识别风功率异常值的清洗方法。
技术实现思路
1、本发明的目的是针对现有风功率异常值清洗方法对部分类型的异常值识别精度不高,鲁棒性低、清洗之后数据趋势一致性差的问题,提供一种精准识别风功率异常值的清洗方法,融合四分位法和根据风功率数据的分布特征对拟合方式改进之后的cook's距离检测方法对风功率异常值数据进行识别,达到对风功率数据中各种类型的异常值数据精确识别、提高数据趋势一致性、清洗之后的数据边缘光滑的目的。
2、为实现上述目的,本发明提供了如下方案:
3、一种精准识别风功率异常值的清洗方法,包括:
4、获取待清洗风功率数据,并对所述待清洗风功率数据进行预处理;
5、对预处理后的所述待清洗风功率数据利用垂直四分位法进行第一次异常值剔除,获取第一正常数据;
6、对所述第一正常数据利用水平四分位法进行第二次异常值剔除,获取第二正常数据;
7、对所述第二正常数据利用cook's距离检测法进行第三次异常值剔除,获取第三正常数据,完成对所述待清洗风功率数据的异常值清洗。
8、可选地,对所述待清洗风功率数据进行预处理包括:
9、对所述待清洗风功率数据进行缺失值和特殊符号处理,并剔除功率值小于和等于0的数据。
10、可选地,对预处理后的所述待清洗风功率数据利用垂直四分位法进行第一次异常值剔除包括:
11、将预处理后的所述待清洗风功率数据按照风速区间进行分组,并确定每个风速区间内的功率阈值;
12、基于所述功率阈值对预处理后的所述待清洗风功率数据进行第一次异常值剔除,获取所述第一正常数据。
13、可选地,确定每个风速区间内的功率阈值的方法为:
14、[fvl,fvu]=[q1-threshold1*iqr,q3-threshold1*iqr]
15、其中,fvl为最小功率阈值,fvu为最大功率阈值,q1为风速区间对应功率数据的一分位数,q3为风速区间对应功率数据的三分位数,iqr为风速区间对应功率数据的分位矩,threshold1为根据预处理后的待清洗风功率数据的分布特征设置的阈值。
16、可选地,对所述第一正常数据利用水平四分位法进行第二次异常值剔除包括:
17、将所述第一正常数据按照功率区间进行分组,并确定每个功率区间内的风速阈值;
18、基于所述风速阈值对所述第一正常数据进行第二次异常值剔除,获取所述第二正常数据。
19、可选地,确定每个功率区间内的风速阈值的方法为:
20、[fhl,fhu]=[q1'-threshold2*iqr',q3'-threshold2*iqr']
21、其中,fhl为最小风速阈值,fhu为最大风速阈值,q1'为功率区间对应功率数据的一分位数,q3'为功率区间对应功率数据的三分位数,iqr'为功率区间对应功率数据的分位矩,threshold2为根据第一正常数据的分布特征设置的阈值值。
22、可选地,对所述第二正常数据利用cook's距离检测法进行第三次异常值剔除包括:
23、确定划分点,根据所述划分点将所述第二正常数据划分为非线性分布段和线性分布段;
24、分别对所述非线性分布段和线性分布段进行回归拟合,获取所述非线性分布段和线性分布段内每个风速点对应的功率预测值;
25、基于所述功率预测值分别计算所述非线性分布段和线性分布段内每个风速点对应的功率真实值的cook's距离;
26、经过将所述cook's距离与预设的cook's距离阈值进行比较进行第三次异常值剔除,获取所述第三正常数据。
27、可选地,分别对所述非线性分布段和线性分布段进行回归拟合包括:
28、对所述非线性分布段进行多项式拟合,获取功率多项式拟合预测值;
29、对所述线性分布段进行最小二乘拟合,获取功率线性拟合预测值。
30、可选地,基于所述功率预测值分别计算所述非线性分布段和线性分布段内每个风速点对应的功率真实值的cook's距离的方法为:
31、
32、其中,di为第i个风速点对应的功率真实值的cook's距离,ei为第i个风点对应的功率预测值的残差,hii为关于输入矩阵x的帽子矩阵,s为残差的标准差,为第i个风速点对应的功率预测值。
33、可选地,所述cook's距离阈值根据cook's距离值的百分点函数进行设置,所述百分点函数为:
34、threshold=percentile(distances,1-α)
35、其中,threshold为cook's距离阈值,percentile为百分位点,distances为cook's距离值,1-α为预期要得到的阈值点对应的百分位点,α为置信度水平。
36、本发明的有益效果为:
37、本发明融合四分位法和根据风功率数据的分布特征对拟合方式改进之后的cook's距离检测方法对风功率异常值数据进行识别,能够识别低密度区的异常值并完整保留正常值,减小正常数据带中低密度数据的误删率,在识别风功率数据异常值方面取得更高的精度;清洗后的数据趋势更合理,数据分布带更集中,数据边缘更光滑。
技术特征:
1.一种精准识别风功率异常值的清洗方法,其特征在于,包括:
2.根据权利要求1所述的精准识别风功率异常值的清洗方法,其特征在于,对所述待清洗风功率数据进行预处理包括:
3.根据权利要求1所述的精准识别风功率异常值的清洗方法,其特征在于,对预处理后的所述待清洗风功率数据利用垂直四分位法进行第一次异常值剔除包括:
4.根据权利要求3所述的精准识别风功率异常值的清洗方法,其特征在于,确定每个风速区间内的功率阈值的方法为:
5.根据权利要求1所述的精准识别风功率异常值的清洗方法,其特征在于,对所述第一正常数据利用水平四分位法进行第二次异常值剔除包括:
6.根据权利要求5所述的精准识别风功率异常值的清洗方法,其特征在于,确定每个功率区间内的风速阈值的方法为:
7.根据权利要求1所述的精准识别风功率异常值的清洗方法,其特征在于,对所述第二正常数据利用cook's距离检测法进行第三次异常值剔除包括:
8.根据权利要求7所述的精准识别风功率异常值的清洗方法,其特征在于,分别对所述非线性分布段和线性分布段进行回归拟合包括:
9.根据权利要求7所述的精准识别风功率异常值的清洗方法,其特征在于,基于所述功率预测值分别计算所述非线性分布段和线性分布段内每个风速点对应的功率真实值的cook's距离的方法为:
10.根据权利要求7所述的精准识别风功率异常值的清洗方法,其特征在于,所述cook's距离阈值根据cook's距离值的百分点函数进行设置,所述百分点函数为:
技术总结
本发明涉及风力发电数据分析与处理技术领域,特别是涉及一种精准识别风功率异常值的清洗方法,包括:获取待清洗风功率数据,并对待清洗风功率数据进行预处理;对预处理后的所述待清洗风功率数据利用垂直四分位法进行第一次异常值剔除,获取第一正常数据;对第一正常数据利用水平四分位法进行第二次异常值剔除,获取第二正常数据;对第二正常数据利用Cook's距离检测法进行第三次异常值剔除,获取第三正常数据,完成对待清洗风功率数据的异常值清洗。本发明在识别风功率数据异常值方面取得更高的精度,清洗后的数据趋势更合理,数据分布带更集中,数据边缘更光滑。
技术研发人员:李寿图,杨福爱,徐晟,代怡,李晔
受保护的技术使用者:兰州理工大学
技术研发日:
技术公布日:2024/6/30
- 还没有人留言评论。精彩留言会获得点赞!