一种基于深度强化学习的医学图像分割方法
本发明属于计算机视觉、图像处理,具体涉及一种医学图像分割方法。
背景技术:
1、深度强化学习是一种基于动态规划求解框架的马尔可夫决策过程处理方法,目前己经广泛应用于智能控制、策略分析、图像处理等领域。
2、医学图像分割是癌症肿瘤等疾病自动化诊断、治疗和预后的重要步骤之一。通过分割病灶区域,辅助医学医生判断样本中是否存在病灶。
3、近年来,基于深度学习的医学图像分割方法逐渐成为研究热点。其中基于深度强化学习的方法结合了深度学习和强化学习的优点,可以自动学习病灶特征、决策规则,从而提高医学图像分割的准确性和鲁棒性。
技术实现思路
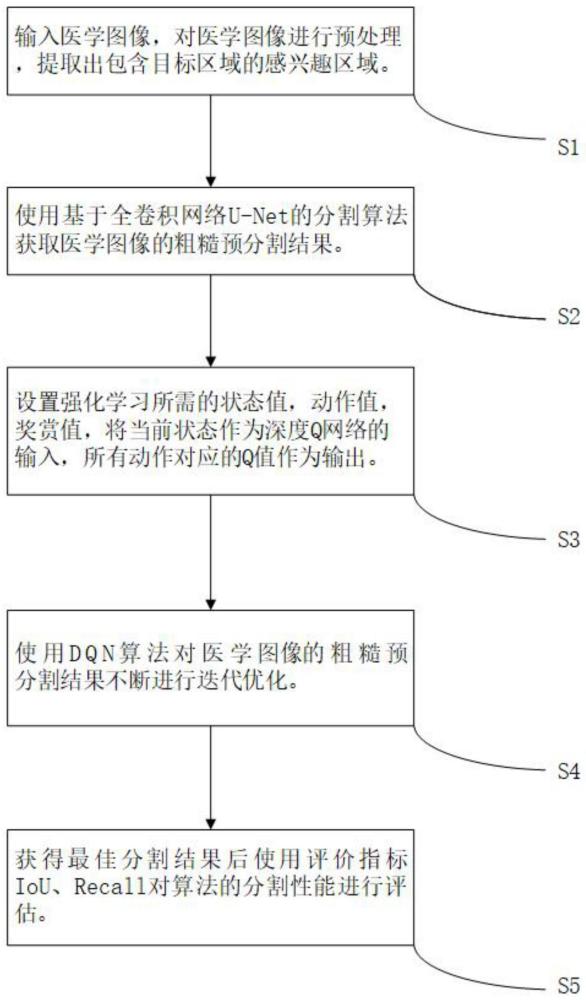
1、针对现有技术中的不足,本发明提供一种基于深度强化学习的医学图像分割方法,能够使用深度学习算法,获得医学图像的病灶区域粗糙预分割结果;使用强化学习算法,对医学图像的病灶区域分割结果不断进行迭代优化,提高模型训练效率,获得较为精确的分割结果。
2、根据本发明提供的一种基于深度强化学习的医学图像分割方法,所述方案如下:
3、深度学习阶段:使用基于卷积神经网络u-net的分割算法获取医学图像的病灶区域粗糙预分割结果;
4、强化学习阶段:使用dqn算法对粗糙预分割结果进行迭代微调,获取医学图像的分割结果。
5、所述深度学习算法步骤包括:
6、步骤1:对已标注的医学图像进行预处理,针对同一数据集中的图像使用统一的均值和标准差进行颜色标准化,使数据集中所有图像转化为相同的rgb颜色空间分布;
7、步骤2:使用u-net分割算法对图像进行训练,然后使用训练好的网络模型获取医学图像的病灶区域粗糙预分割结果。
8、优选的,本发明使用余弦退火方法优化网络的学习率,此学习率调整方法通过在训练周期内逐渐降低学习率,从而在训练早期使用较大的学习率以更快地接近全局最小值,然后在后期使用较小的学习率进行微调,以提高模型的稳定性和泛化能力。该算法中的优化步长可由以下公式获得:
9、
10、在上式中,r为优化步长,和分别为整个训练过程中设置的学习率的最小值和最大值,预设两者的值分别为0.00001和0.001,其中i为当前执行的次数,ti表示当前己经执行的迭代次数,tc为总的迭代次数。
11、所述强化学习算法步骤包括:
12、步骤1:设置强化学习所需的状态值,动作值,奖赏值;
13、状态值:选取图像每一列某一像素的领域灰度级特征向量和记忆向量组成状态值,记忆向量指智能体在过去采取的历史动作信息;
14、动作值:定义动作为改变分割阈值,即当前阈值减少或增加动作集合ai代表的灰度级,a=[-40,-20,-10,-1,0,1,10,20,40],例如a1动作代表当前阈值减少40,a9动作代表阈值增加40,其中这个-40数值代表像素灰度级,以此类推,分割阈值随着动作的变化不断改变;
15、奖赏值:定义奖赏为当前分割出的目标区域与图像实际最优分割的符合程度。
16、步骤2:当前状态作为深度q网络的输入,深度q网络由两个全连接层组成,每层后都跟有一个relu函数和一个dropout层,最后输出层预测出当前分割阈值对应的q值。
17、步骤3:根据目标q值和深度q网络输出的q值之间的误差计算损失函数;对深度q网络中的权重参数使用截断正态分布随机初始化,隐层通过relu激活函数激活,使用adam优化器进行梯度更新,直到进行1000次迭代为止获得最佳分割结果阈值ta,使用分割算法的评价指标iou、reca11对算法的分割性能进行评估。
18、优选的,根据ε-greedy策略选取相应的动作,对粗糙预分割结果进行选代优化,所述ε-greedy策略包括:
19、ε-greedy是随机探索的一种常用策略,它以ε的概率在所有可能的动作中随机选择,1-ε的概率按照策略π选择价值最高的动作,则选择动作的概率为
20、
21、其中,ε参数(0≤ε≤1)用来控制探索和利用的比例;ε的值越大,代表更多的探索;ε的值越小,代表更多的利用;k为所有可能的动作数(k=9),s表示当前的状态,a表示在当前状态下采取的动作,q(s,a)代表状态-动作值函数。
22、优选的,dqn算法将通过深度q网络计算得到的q值作为预测q值,使用smooth l1函数来计算损失函数,其中y代表目标q值,f(x)为模型的预测值,表示如下:
23、
24、与现有技术相比,本发明具有如下的有益效果:
25、本发明将医学图像的分割任务分为两个阶段。第一阶段使用深度学习算法,获得医学图像的病灶区域粗糙预分割结果;第二阶段使用强化学习算法,对医学图像的病灶区域分割结果不断进行迭代优化,提高模型训练效率,获得较为精确的最终分割结果,达到了提升医学医生诊断癌症效率和准确率的目的。
技术特征:
1.一种基于深度强化学习的医学图像分割方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述深度学习步骤包括:
3.根据权利要求2所述的方法,其特征在于,本发明使用余弦退火方法优化网络的学习率,此学习率调整方法通过在训练周期内逐渐降低学习率,从而在训练早期使用较大的学习率以更快地接近全局最小值,然后在后期使用较小的学习率进行微调,以提高模型的稳定性和泛化能力。该算法中的优化步长可由以下公式获得:
4.根据权利要求1所述的方法,其特征在于,所述强化学习步骤包括:
5.根据权利要求4所述的方法,其特征在于,根据ε-greedy策略选取相应的动作,对粗糙预分割结果进行选代优化,所述ε-greedy策略包括:
6.根据权利要求1,4所述的一种基于深度强化学习的医学图像分割方法,其特征在于,强化学习阶段dqn算法将通过深度q网络计算得到的q值作为预测q值,使用smooth l1函数来计算损失函数,其中y代表目标q值,f(x)为模型的预测q值,表示如下:
技术总结
本发明公开了一种基于深度强化学习的医学图像分割方法,该方法包括:1)输入医学图像,对医学图像进行预处理,使用基于卷积神经网络U‑Net的分割算法获取医学图像的病灶区域粗糙预分割结果;2)设置强化学习所需的状态值,动作值,奖赏值,将当前状态作为深度Q网络的输入,所有动作对应的Q值作为输出,使用DQN算法对医学图像的病灶区域粗糙预分割结果不断进行迭代优化;3)获得最佳分割结果后使用评价指标对算法的分割性能进行评估。本发明利用深度学习算法,获得医学图像的病灶区域粗糙预分割结果,使用强化学习算法,对医学图像的病灶区域分割结果不断进行迭代优化,提高模型训练效率,获得较为精确的分割结果。
技术研发人员:陈金令,陈宇,唐卓葳,何玮,柯琦,季语祝,高子清,魏继鸿
受保护的技术使用者:西南石油大学
技术研发日:
技术公布日:2024/6/26
- 还没有人留言评论。精彩留言会获得点赞!