一种用于时序数据的无监督领域适应方法与流程
本发明涉及机器学习,具体涉及一种用于时序数据的无监督领域适应方法。
背景技术:
1、对时序数据进行无监督领域适应(unsupervised domain adaptation,uda)一直面临挑战,主要原因在于目标域中缺乏标注数据。传统的uda方法大多依赖辅助目标域结构,如伪标签或类比例,但实际情况下这些辅助信息往往难以获取。
2、以往方法主要关注源目标特征分布的直接对齐,但这可能会混淆不同类的特征,无法充分利用时序数据在领域变化下的内在一致性。在现有技术中,如文献[1]“variational recurrent adversarial deep domain adaptation[c]//internationalconference on learning representations.,2017”提出的vrada方法利用变分循环神经网络提取特征,再通过对抗训练来对齐源目标域特征分布。但直接匹配变量层次的分布存在拧混源域类条件分布的风险,从而妨碍有效传输。另外文献[2]“cross-domainmissingness-aware time-series adaptation with similarity distillation inmedical applications[j]//ieee transactions on cybernetics,2020,52(5):3394–3407”采用递回网络对时序数据进行特征提取,再使用标准流形学习或对抗训练进行特征分布对齐,但其忽略了时序数据内在一致性,可能导致特征失去任务特异性。而基于度量学习的方法。如运用最小二乘法或者mmd进行分布对齐,这类方法难以捕获内在一致性,且mmd在两个分布支持不相交时梯度消失问题严重。
技术实现思路
1、针对现有技术的不足,本发明提供了一种用于时序数据的无监督领域适应方法,克服了现有技术的不足,以解决现有方法直接匹配源目标特征分布可能会混淆不同类特征的问题。
2、为实现以上目的,本发明通过以下技术方案予以实现:
3、一种用于时序数据的无监督领域适应方法,包括:
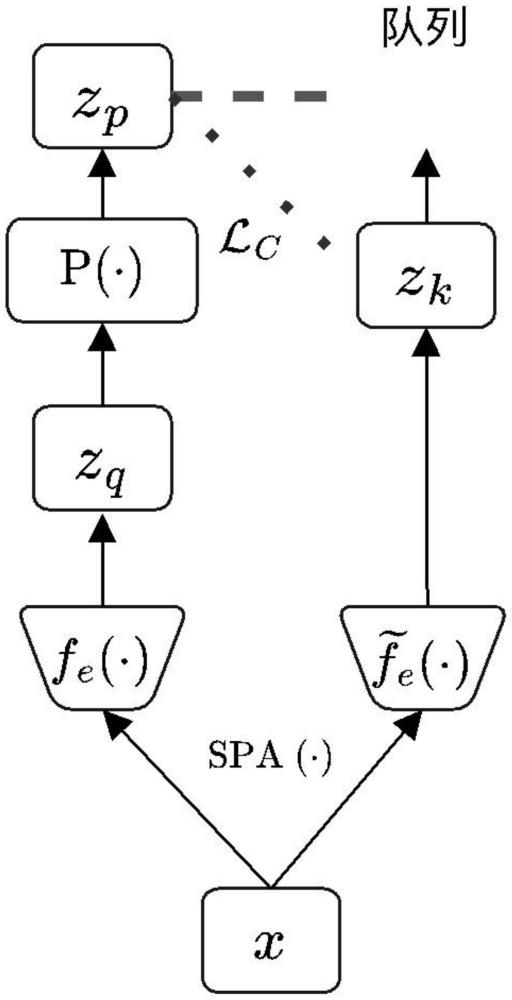
4、步骤(1):对比学习模块;利用对比学习获取源目标样本的语义上下文表示,为此对输入时序数据进行数据增强生成查询视图和键视图,再分别输入编码器得到嵌入向量;
5、步骤(2):重建一致性模块;采用序列重建和表示重构两个机制重建源目标样本;
6、步骤(3):特征对齐模块;采用sinkhorn距离公式,通过输入源目标特征对其进行匹配,实现源目标特征空间的稳定对齐;
7、步骤(4):预测分析模块;使用预测损失联合训练编码器和分类器,实现分类预测。
8、优选地,所述对比学习模块利用动量对比方法来获取语义上下文表示,具体包括以下步骤:
9、步骤(11):数据增强;对输入时序数据x采用数据增强函数生成查询视图q和键视图k:
10、
11、步骤(12):特征提取;分别采用编码器fe(·)和动量编码器提取q和k的表征:
12、zq=fe(q)
13、
14、步骤(13):对比学习;计算查询表征zq与正对表征zk和负对表征zp之间的对比损失:
15、
16、其中sim(·,·)表示相似性度量函数,如内积;τ代表温度参数。
17、步骤(14):动量更新:采用momenum更新规则优化动量编码器参数θ':
18、
19、优选地,所述重建一致性模块采用序列重建和表示重构两个机制,强化任务间的一致性表达,具体包括以下步骤:
20、步骤(21):序列重建;采用双重编码器架构进行序列重建,包括编码器:fe(x)提取序列表示z,重构解码器1:重建源序列以及重构解码器2:重建目标序列通过下式计算序列重建损失:
21、
22、步骤(22):表示重构;采用交叉编码器架构重建表达,包括编码器:z=f1(x),以及交叉重构解码器:通过下式计算表示重构损失:
23、
24、优选地,所述特征对齐模块具体包括以下步骤:
25、步骤(31):计算代价矩阵;根据源域特征zs和目标域特征zt,计算它们在某个距离空间下的代价矩阵c:
26、cij=|zs-zt|p
27、步骤(32):构建gibbs核;依据步骤(31)的代价矩阵c,通过指数运算构建gibbs核k;gibbs核的求解公式如下:
28、kgibbs=exp(-τc)/z
29、其中z是标准化因子;
30、步骤(33):sinkhorn迭代;从gibbs核出发,通过交替迭代的方式求解行矢量u和列向量v,从而得到bistochastic矩阵t,具体求解bistochastic矩阵t的公式如下:
31、t=diag(u)-1kgibbsdiag(v)-1
32、u←1/t1
33、
34、步骤(34):损失计算;将得到的t矩阵和原始的代价矩阵c内积,获得sinkhorn散度:
35、ls=s(zs,zt)=∑i,jtijcij。
36、优选地,所述预测模块基于对比学习模块、重建一致性模块和特征对齐模块得到的表达实现源域分类预测,具体包括以下步骤:
37、步骤(41):特征提取;采用对比学习模块提取得到的动量编码器fe(·),对源域样本xs进行编码,提取特征表示h:
38、zs=fe(xs)
39、步骤(42):分类判别;将编码后的特征zs输入分类器c(·)进行分类,输出预测分布
40、
41、步骤(43):损失计算;使用分类交叉熵损失函数lc量化预测准确度:
42、
43、步骤(43):反向传播;根据分类损失lp反向传播调整编码器参数θ,进行迁移学习:
44、θ←θ-α∨θlc
45、其中∨θ表示向量微分算子。
46、本发明提供了一种用于时序数据的无监督领域适应方法。具备以下有益效果:通过利用对比学习增强上下文表示,同时利用重建一致性机制来保留任务特异性,从而在保持预测能力的同时最大限度地减小源目标领域差异,与直接对齐源目标特征分布的现有技术不同,本方法着力于捕获类样本之间的内在一致性,避免了混淆不同类的问题。另外上述的对比学习模块、重建一致性模块、特征对齐模块和预测分析模块通过深度学习框架的迭代训练进行更新优化。从而在保留预测精度的同时实现了最大限度的领域泛化能力。并且本发明的每个模块分别完成特定任务,有助于性能分析。且无需目标域数据标签进行训练,完全无监督,易于实施。
技术特征:
1.一种用于时序数据的无监督领域适应方法,其特征在于:包括:
2.根据权利要求1所述的一种用于时序数据的无监督领域适应方法,其特征在于:所述对比学习模块利用动量对比方法来获取语义上下文表示,具体包括以下步骤:
3.根据权利要求1所述的一种用于时序数据的无监督领域适应方法,其特征在于:所述重建一致性模块采用序列重建和表示重构两个机制,强化任务间的一致性表达,具体包括以下步骤:
4.根据权利要求1所述的一种用于时序数据的无监督领域适应方法,其特征在于:所述特征对齐模块具体包括以下步骤:
5.根据权利要求1所述的一种用于时序数据的无监督领域适应方法,其特征在于:所述预测模块基于对比学习模块、重建一致性模块和特征对齐模块得到的表达实现源域分类预测,具体包括以下步骤:
技术总结
一种用于时序数据的无监督领域适应方法,包括:对比学习模块;利用对比学习获取源目标样本的语义上下文表示,为此对输入时序数据进行数据增强生成查询视图和键视图,再分别输入编码器得到嵌入向量;重建一致性模块;采用序列重建和表示重构两个机制重建源目标样本;特征对齐模块;采用Sinkhorn距离公式,通过输入源目标特征对其进行匹配,实现源目标特征空间的稳定对齐;预测分析模块;使用预测损失联合训练编码器和分类器,实现分类预测。本发明克服了现有技术的不足,以解决现有方法直接匹配源目标特征分布可能会混淆不同类特征的问题。
技术研发人员:吴涛,王兆臣,张立飞,孙伯依杭,邹韦,郭帅
受保护的技术使用者:上海模呈信息技术有限公司
技术研发日:
技术公布日:2024/6/20
- 还没有人留言评论。精彩留言会获得点赞!