一种基于血管内超声影像的管腔轮廓及外弹力膜识别方法
本发明涉及图像处理,尤其是涉及一种基于血管内超声影像的管腔轮廓及外弹力膜识别方法。
背景技术:
1、血管内超声影像(intravascular ultrasound,ivus),是一种医学影像的成像方法,近年来主要用于诊断冠心病,并在临床应用领域取得了较为良好的效果。ivus是基于超声回声检测的影像技术,利用血管内壁、壁内动脉粥样病变组织以及覆盖在血管表面的结缔组织具有回声作用的特性,使得输出声波能够返回到超声检测显示器上并可见。另一方面,由于血液本身和血管壁的健康肌肉组织具有透声性,在图像上只留有黑色的圆形图样。如若血管内的钙化沉积物会产生强烈的非常规回声,也可以通过图像上的阴影部分加以区分。医生在进行诊断时,将微型化的超声探头通过长约200cm的柔软导管送入心血管组织中,进行横断层扫描,获得血管的断层图样信息。同时,在导丝保持静止时,超声导管尖端在医生或者机动控制下,沿轴向匀速拉回,可以得到血管的三维信息,提高了医生做出判断的精度,便于给出更为准确的治疗方案。
2、对ivus的管腔轮廓(lumen)及外弹力膜(eem)的识别,可得到斑块负荷指数,又称“面积狭窄百分数”,即定量狭窄程度的相对值,计算公式为:斑块面积/外弹力膜横截面积×100%。目前,斑块负荷指数对临床医学有着重要的意义,其一,常作为观察冠状动脉狭窄严重程度的指标;其二,医生可根据斑块负荷指数,判断斑块的大小;其三,斑块负荷指数结合斑块性质,可用于指导优化手术策略。所以,精准的识别影像的管腔轮廓及外弹力膜,获得血管内径及狭窄程度的精确信息极为重要,否则稍微的信息不准确就会影响临床医生的判断。
3、目前,ivus作为临床上最常用的血管腔内成像技术,存在着图像分辨率较低,管腔轮廓及外弹力膜成像模糊的缺点,并且运用已有的深度学习框架难以得到精准的轮廓识别结果,已有的深度学习方法通常存在识别的轮廓不完整问题;并且现有的技术均不能同时识别eem和lumen,技术水平要求较高,无法实现临床普及。
4、运用传统机器学习法识别出来的管腔轮廓,其鲁棒性、稳定性、精确度都比较低;
5、而运用深度学习框架来识别管腔轮廓,由于ivus图像分辨率低、管腔轮廓及外弹力膜成像模糊的特点,再加上管腔轮廓形状多变,若直接将深度学习法应用到识别其框架上,虽然可以得到轮廓的分割结果,但是通常无法得到完整的轮廓识别结果,导致轮廓识别的部分缺失或形状扭曲,和实际边缘有一定的差异,识别的边缘信息不够准确等问题,从而导致计算出的斑块负荷指数无法用于精准pci诊断和治疗。
技术实现思路
1、本发明的目的就是为了克服上述现有技术存在运用深度学习框架来识别管腔轮廓,由于ivus图像分辨率低、管腔轮廓及外弹力膜成像模糊的特点,再加上管腔轮廓形状多变,通常无法得到完整的轮廓识别结果,导致轮廓识别的部分缺失或形状扭曲,和实际边缘有一定的差异的缺陷而提供一种基于血管内超声影像的管腔轮廓及外弹力膜识别方法。
2、本发明的目的可以通过以下技术方案来实现:
3、一种基于血管内超声影像的管腔轮廓及外弹力膜识别方法,包括以下步骤:
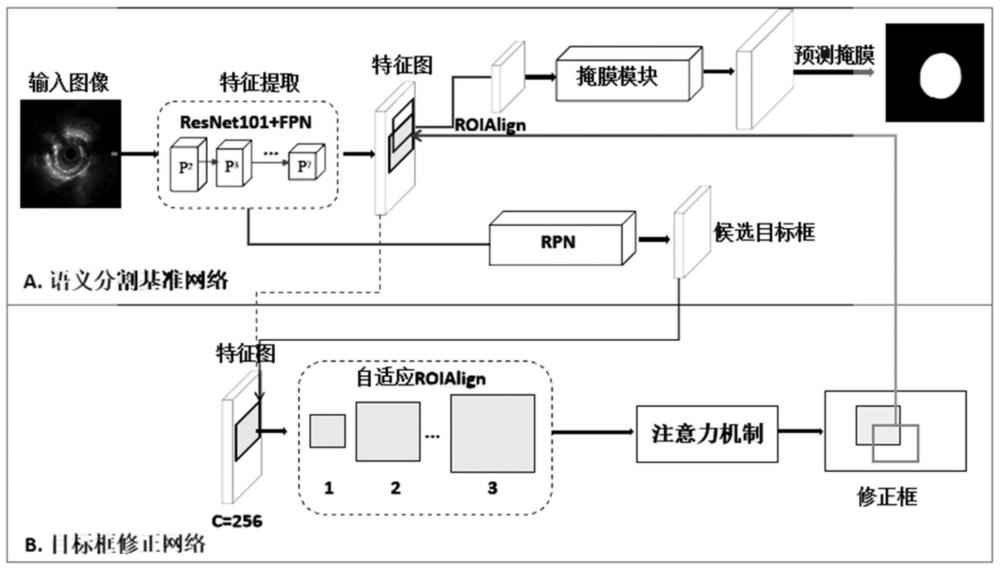
4、获取血管内超声影像并进行预处理;对预处理后的图像进行特征提取,对提取的特征生成目标框;对生成的目标框中属于前景的目标框进行修正,然后输入到掩膜模板进行语义分割,获取管腔轮廓及外弹力膜识别结果;
5、所述目标框的修正过程包括以下步骤:获取目标框和对应的特征图,对目标框和特征图进行扩充,得到扩充后的目标框集合和特征图;采用扩充后的目标框,对特征图进行特征提取,得到新的特征图;对原始获取的特征图和新的特征图,采用注意力机制捕获像素之间的关系,从而修正目标框的坐标,输出修正后的的目标框位置。
6、进一步地,采用adaptive roialign对目标框进行扩充,扩充的倍数为k,对于目标框bi=(x1,y1,x2,y2),扩充后得到的目标框集合的表达式为:
7、
8、
9、
10、
11、
12、式中,为目标框bi扩充后的目标框集合,为中第j个目标框,为扩充后的目标框bi的左上角坐标,为扩充后的目标框bi的右下角坐标,α表示修正框的调整系数,w和h表示原始获取的特征图的尺寸。
13、进一步地,对于扩充后得到的各个目标框,采用roialign对特征图进行特征提取,最终组合得到所述新的特征图,采用roialign提取的特征的表达式为:
14、
15、式中,为采用对特征图进行特征提取后的特征,f为原始获取的特征图特征图。
16、进一步地,所述注意力机制采用q和k-v机制,其中,q为原始获取的特征图roiori,k-v为对目标框进行扩充后提取的新的特征图所述q和k-v机制首先通过卷积将特征图roisnew分解为k和v,通过卷积对特征图roiori进行特征提取,得到获取输出roiatt:
17、
18、最后使用卷积和全连接层,得到修正后的目标框bnew。
19、进一步地,所述方法的网络训练过程中,对获取的血管内超声影像构建数据集,并进行管腔和外弹力膜的标注。
20、进一步地,对数据集的预处理过程中,对数据集的样本进行翻转或添加噪声的方式,以增加样本数量。
21、进一步地,所述样本的翻转方式包括仿射变换和镜像变换。
22、进一步地,采用resnet101和fpn网络共同对预处理后的图像进行特征提取。
23、进一步地,采用rpn网络对提取的特征生成目标框。
24、进一步地,所述方法还包括根据获取的管腔轮廓及外弹力膜识别结果,结合图像的像素分辨率,计算出管腔面积以及外弹力膜面积,从而实现斑块负荷的计算。
25、与现有技术相比,本发明具有以下优点:
26、(1)本发明针对目前主流的深度语义分割网络存在的目标分割不完整问题,提出目标框修正网络框架,对目标框的位置进行扩充和优化,使得目标框可以包含完整的目标,便于后续的像素级分割;
27、并对扩充后的目标框提取的特征图与原始的特征图,通过注意力机制,利用目标的空间领域信息,对扩充后的目标框进行进一步的修正,可以更好的框中完整的目标,提高对目标的识别精度,从而提升最终的语义分割结果。
28、(2)本发明基于修正后的目标框,能够进行准确的像素级的语义分割,并经过试验验证,本发明对外弹力膜的识别更完整、更准确。
技术特征:
1.一种基于血管内超声影像的管腔轮廓及外弹力膜识别方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于血管内超声影像的管腔轮廓及外弹力膜识别方法,其特征在于,采用adaptive roialign对目标框进行扩充,扩充的倍数为k,对于目标框bi=(x1,y1,x2,y2),扩充后得到的目标框集合的表达式为:
3.根据权利要求2所述的一种基于血管内超声影像的管腔轮廓及外弹力膜识别方法,其特征在于,对于扩充后得到的各个目标框,采用roialign对特征图进行特征提取,最终组合得到所述新的特征图,采用roialign提取的特征的表达式为:
4.根据权利要求3所述的一种基于血管内超声影像的管腔轮廓及外弹力膜识别方法,其特征在于,所述注意力机制采用q和k-v机制,其中,q为原始获取的特征图roiori,k-v为对目标框进行扩充后提取的新的特征图所述q和k-v机制首先通过卷积将特征图分解为k和v,通过卷积对特征图roiori进行特征提取,得到获取输出roiatt:
5.根据权利要求1所述的一种基于血管内超声影像的管腔轮廓及外弹力膜识别方法,其特征在于,所述方法的网络训练过程中,对获取的血管内超声影像构建数据集,并进行管腔和外弹力膜的标注。
6.根据权利要求1所述的一种基于血管内超声影像的管腔轮廓及外弹力膜识别方法,其特征在于,对数据集的预处理过程中,对数据集的样本进行翻转或添加噪声的方式,以增加样本数量。
7.根据权利要求6所述的一种基于血管内超声影像的管腔轮廓及外弹力膜识别方法,其特征在于,所述样本的翻转方式包括仿射变换和镜像变换。
8.根据权利要求1所述的一种基于血管内超声影像的管腔轮廓及外弹力膜识别方法,其特征在于,采用resnet101和fpn网络共同对预处理后的图像进行特征提取。
9.根据权利要求1所述的一种基于血管内超声影像的管腔轮廓及外弹力膜识别方法,其特征在于,采用rpn网络对提取的特征生成目标框。
10.根据权利要求1所述的一种基于血管内超声影像的管腔轮廓及外弹力膜识别方法,其特征在于,所述方法还包括根据获取的管腔轮廓及外弹力膜识别结果,结合图像的像素分辨率,计算出管腔面积以及外弹力膜面积,从而实现斑块负荷的计算。
技术总结
本发明涉及一种基于血管内超声影像的管腔轮廓及外弹力膜识别方法,包括:获取血管内超声影像并进行预处理,从而进行特征提取,对提取的特征生成目标框;对目标框中属于前景的目标框进行修正,然后输入到掩膜模板进行语义分割,获取管腔轮廓及外弹力膜识别结果;目标框的修正过程包括:获取目标框和对应的特征图,对目标框和特征图进行扩充;采用扩充后的目标框,对特征图进行特征提取,得到新的特征图;对新的特征图,采用注意力机制捕获像素之间的关系,从而修正目标框的坐标,输出修正后的的目标框位置。与现有技术相比,本发明实现目标框的位置扩充和优化,可以更好的框中完整的目标,并利用目标的空间领域信息,提高了对目标的识别精度。
技术研发人员:李晨光,吴轶喆,沈雳,徐仁德,钱菊英,葛均波
受保护的技术使用者:复旦大学附属中山医院
技术研发日:
技术公布日:2024/6/30
- 还没有人留言评论。精彩留言会获得点赞!