基于生成对抗网络的车内视频人脸图像脱敏方法及设备
本发明涉及汽车数据安全,具体涉及一种基于生成对抗网络的车内视频人脸图像脱敏方法及设备。
背景技术:
1、随着网联化程度加深,人、车、路、云交互场景和频次增多,智能网联汽车产生的数据增长迅速、体量庞大,数据安全问题已成为智能网联汽车安全保障的核心挑战。全球数据安全威胁不断升级,智能网联汽车数据安全面临日益严峻的形势。数字图像的发展使得人脸识别技术日益精进,现在已经被广泛用于日常生活的很多方面,比如人脸解锁、人脸支付、权限验证等,这使得一些恶意用户可以通过共享数据获得人脸的生物特征,利用人脸识别技术窃取用户的隐私。
2、为了防御黑客恶意使用车主的车内视频,对人脸图像脱敏是不可缺少的技术处理操作。人脸图像脱敏作为一种主动的数据安全防护措施,主要通过人脸编辑、人脸匿名化和基于深度学习的人脸脱敏方法来实现保护个人身份信息,保障车载端的数据安全。车内摄像头录制视频的能力不断提高和人脸角度的复杂导致车载数据安全威胁和图像防护处理难度不断增加,现有的安全防护技术不适用于车内视频中人脸图像保护和车内复杂场景中。
3、生成对抗网络作为一种深度学习结构,由生成器和判别器组成,通过对抗性学习生成高度逼真的图像。在图像脱敏任务中,gan通过生成器网络实现对真实图像分布的模拟,生成具有逼真感的替代图像。这一方法不仅保留了原始图像的信息,还通过细粒度的控制机制使得脱敏效果可调。针对传统的脱敏方法信息丢失和图像失真的问题,本发明提出一种基于生成对抗网络的车内视频人脸图像脱敏方法。
技术实现思路
1、本发明提出的一种基于生成对抗网络的车内视频人脸图像脱敏方法、设备及存储介质,可至少解决背景技术中的技术问题之一。
2、为实现上述目的,本发明采用了以下技术方案:
3、一种基于生成对抗网络的车内视频人脸图像脱敏方法,具体通过以下步骤实现:
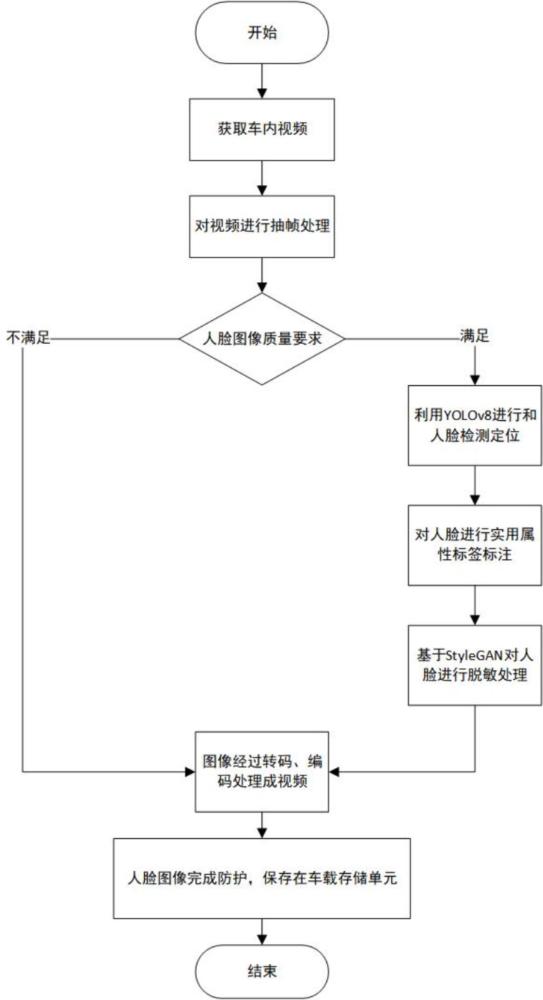
4、步骤1:为构建可信精准的车内视频人脸图像脱敏模型,保证汽车面部识别系统对车内人脸行为的精准检测,本发明利用yolo v8对车内摄像头获取视频中的人脸进行检测。首先对视频进行抽帧处理,按照固定的时间间隔抽取视频帧。然后将cspdarknet53作为骨干网络,提取输入图像的高级特征表示。引入多尺度预测,利用不同层次的特征图对目标进行多尺度检测,以提高对前排驾驶员和副驾驶员人脸图像大目标、后排乘客人脸图像小目标的敏感性。模型通过回归框的中心坐标、宽高以及目标类别,实现对人脸目标的精确定位和分类。
5、步骤2:利用deepglint深度学习模型,实现对人脸图像的准确定位和多属性标注。通过构建包含多种属性标签的人脸图像数据集,并进行多轮迭代的模型训练。deepglint模型对人脸图像进行多属性的分类,如性别、年龄、表情、是否佩戴眼镜、山羊胡、络腮胡等。输出结果为每张人脸生成相应的实用属性标签。最终构建出一个按人脸属性分类的数据集。
6、步骤3:针对车内视频可能被窃取泄露、他人恶意利用的问题,本专利提出一种基于生成对抗网络的车内人脸图像脱敏方法,将完成属性标注的真实人脸图像数据集作为训练数据集输入到生成对抗网络中。本发明基于残差网络构造了一个感知编码器,将原始的ai人脸图像映射到特征空间,获得初始的隐向量。为从直观视觉上改变原始图像身份,生成对抗网络的生成器中利用完全由ai生成的人脸数据集对真实人脸图像在表情、性别、年龄等属性上进行改变。在判别器中设置一个判别值,将生成的图像与原始图像对比,然后更新迭代生成的图像,结果越接近原始图像越真实。最终将生成的人脸图像通过解码生成视频,完成车内视频人脸图像的脱敏。
7、又一方面,本发明还公开一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行如上述方法的步骤。
8、再一方面,本发明还公开一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行如上方法的步骤。
9、由上述技术方案可知,本发明的基于生成对抗网络的车内视频人脸图像脱敏方法及系统,首先通过yolo v8目标检测算法实现对车内视频图像的实时人脸检测,并标注检测到的人脸区域,同时通过人脸属性识别技术为这些人脸区域添加属性标签。然后对标注完成的人脸区域进行图像预处理,确保提取到高质量的人脸属性。通过深度学习模型提取原始人脸图像的属性因子,包括面部特征和表情等。最后,利用生成对抗网络生成替代的人脸图像,并将生成图像的属性因子与原始人脸图像的属性因子进行替换,从而实现车内视频人脸图像的脱敏处理。
10、具体的说,本发明的方法通过结合yolo v8目标检测算法和deepglint深度学习模型,实现了对车内摄像头采集的视频中的人脸图像的准确定位、多属性标注以及隐私保护的三步处理。首先,利用yolo v8目标检测算法对车内视频进行抽帧处理和多尺度预测,提高对不同目标的敏感性,以精准检测车主和乘客的人脸。其次,通过deepglint深度学习模型,实现了对人脸图像的多属性标注,包括性别、年龄、表情等,生成相应实用属性标签并构建分类数据集。最后,通过生成对抗网络对标注完成的真实人脸图像进行脱敏处理,替换属性因子生成模糊的人脸图像,以确保车内人脸图像的隐私保护。
11、本发明的有益效果在于:
12、(1)本发明提出了一种基于yolo v8的高效车内视频人脸检测方法,对车内摄像头获取的视频中的人脸进行精准的检测和分类。该模型引入了多尺度预测,可以利用不同层次的特征图对目标进行多尺度检测,从而提高了对前排驾驶员和副驾驶员人脸图像大目标、后排乘客人脸图像小目标的敏感性。这种技术可以提高模型的检测准确率和鲁棒性,从而为汽车行业提供更加安全和可靠的面部识别解决方案。
13、(2)本发明提出了一个基于deepglint深度学习模型的人脸图像定位和多属性标注方法,该方法能够对人脸图像进行精确的定位和多属性的标注,如性别、年龄、表情、是否佩戴眼镜、山羊胡、络腮胡等。通过构建包含多种属性标签的人脸图像数据集,并进行多轮迭代的模型训练,可以生成每张人脸相应的实用属性标签。最终,该方法能够构建出一个按人脸属性分类的数据集,为后续的人脸识别和分析提供准确的数据支持。
14、(3)本发明提出了一种基于生成对抗网络的车内视频人脸图像脱敏方法,可以有效地保护个人隐私,避免车内视频被窃取泄露和他人恶意利用。该方法利用完全由ai生成的人脸数据集对真实人脸图像在表情、性别、年龄等属性上进行改变,从而实现对车内视频人脸图像的脱敏。通过设置判别值,将生成的图像与原始图像对比,然后更新迭代生成的图像,结果越接近原始图像越真实。这种方法不仅可以保护个人隐私,还能提高车内视频的安全性和可靠性。
技术特征:
1.一种基于生成对抗网络的车内视频人脸图像脱敏方法,其特征在于,包括以下步骤,
2.根据权利要求1所述的基于生成对抗网络的车内视频人脸图像脱敏方法,其特征在于:步骤s1具体包括,
3.根据权利要求2所述的基于生成对抗网络的车内视频人脸图像脱敏方法,其特征在于:步骤s2还包括,为了提高对不同大小目标人脸的检测能力,引入了多尺度预测机制;利用不同层次的特征图对目标进行多尺度的检测;
4.根据权利要求1所述的基于生成对抗网络的车内视频人脸图像脱敏方法,其特征在于:步骤s3具体包括,
5.根据权利要求1所述的基于生成对抗网络的车内视频人脸图像脱敏方法,其特征在于:所述s4具体包括,
6.其中,表示输入噪声变量,表示生成器在数据上的分布,表示判别器在数据上的分布;将到数据空间的映射表示为,其中是参数的多层感知机表示的微分函数;表示来自真实样本数据的概率。
7.根据权利要求5所述的基于生成对抗网络的车内视频人脸图像脱敏方法,其特征在于:
8.一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行如权利要求1至6中任一项所述方法的步骤。
技术总结
本发明的一种基于生成对抗网络的车内视频人脸图像脱敏方法及设备,包括使用YOLO v8目标检测算法实现车内人脸的实时检测与定位,并采用CSPDarknet53作为骨干网络提取高级特征;通过多尺度预测机制适应不同大小目标人脸,以确保对所有可见人脸的准确检测;利用DeepGlint深度学习模型对人脸图像进行准确定位和多属性标注,为图像提供更全面的特征描述;面对视频滥用风险,提出了基于GAN的创新脱敏方法,使用残差网络感知编码器转换原始人脸图像至特征空间,并在生成器中通过学习虚拟人脸数据集,调整真实人脸图像的属性;引入判别器进行图像相似度评估,通过反馈调整生成图像,最终生成连续视频流完成脱敏处理。本发明可以提高模型的检测准确率和鲁棒性。
技术研发人员:冀浩杰,王璟炎,黄小龙,王立勇,陈宇鹏,贺鹏,金龙,胡特
受保护的技术使用者:北京信息科技大学
技术研发日:
技术公布日:2024/6/26
- 还没有人留言评论。精彩留言会获得点赞!