一种基于熵权法的综合排序自适应特征选择方法及系统
本发明涉及工业生产检测领域,更具体的说是涉及一种基于熵权法的综合排序自适应特征选择方法及系统。
背景技术:
1、特征选择也称为特征子集选择或属性选择,是通过特定的指标标准和性能评价对原始特征集进行特征降维的一种技术。特征选择工程起源于上个世纪60年代,最初用于解决与统计学相关的问题或用于信号处理。而后随着许多机器学习和深度学习算法的出现,特征选择领域相关研究不断的发展完善,并在数据挖掘、模式识别、故障诊断等诸多领域都得到了广泛的应用。
2、特征选择算法是从原始纷繁复杂的数据集中,按照某种特定的特征评价标准来评价每一个特征的重要性,然后从特征空间中选择或提取出相关特征得出最优特征子集用于研究和处理问题,从而量化各个特征的有效性,进一步提升模型的性能。在实际工业领域的应用中,高维的时序数据输入不同特征会对故障预测任务有很大影响,也不利于对预测目标数据进行更多的高级分析。
3、在特征选择算法中,过滤式特征选择方法由于用时较少,且经过多年的不断研究和改进,性能准确率有了很大的提高,因此,在工业生产领域针对时序数据的预测问题,一般选择过滤式特征选择方法。其中,基于相关性分析度量指标进行特征选择是过滤方法中最常用的方法。对于不同的预测目标参数,不同相关性方法的过滤筛选有效性并不一致,且需人为设定阈值来筛选特征子集。因此,如何解决上述问题是本领域技术人员亟需研究的。
技术实现思路
1、为了从不同角度进行特征优化、结合不同的相关性分析算法优势,自适应设定筛选阈值,本发明提出了一种基于熵权法赋权的综合排序自适应特征选择方法及系统,依据各相关性分析算法的系数的信息熵来设置各算法所得系数的权值,然后根据几何平均法给出阈值,自适应的选择预测参数的特征子集。而比较于人为设置权重的方法强烈的主观性和较大的误差波动,本发明的方法依据指标的信息含量,对不同方法赋权重,具有更好的普适性和通用性。
2、为了实现上述目的,本发明采用如下技术方案:
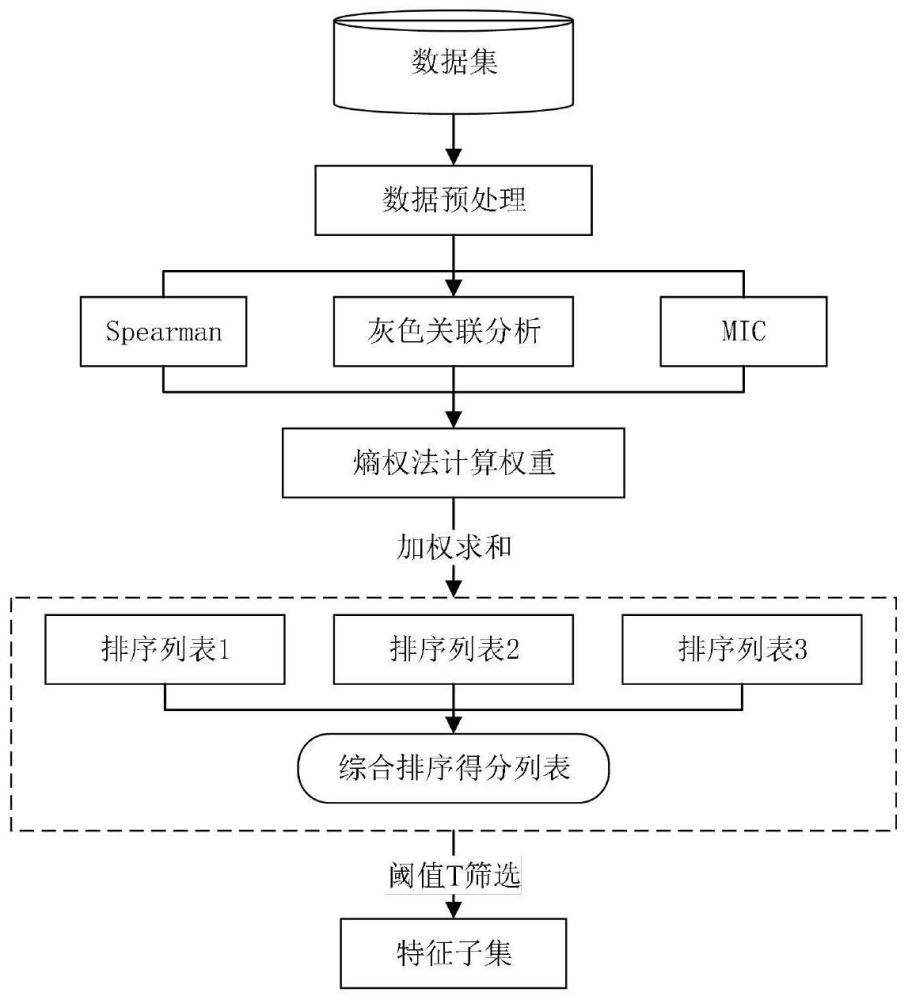
3、一种基于熵权法的综合排序自适应特征选择方法,包括以下步骤:
4、步骤1、获取工业生产检测特征参数的数据集,计算预测目标参数与各特征参数之间的秩相关系数、灰色关联分析系数和最大信息系数;
5、步骤2、应用熵权法为秩相关系数、灰色关联分析系数和最大信息系数赋权;
6、步骤3、基于赋权结果计算预测目标参数与所有特征参数的综合排序列表;
7、步骤4、根据几何平均函数方法求得预测目标的特征动态阈值,选取综合排序列表中预测目标小于特征动态阈值的所有特征作为预测目标的最终优化特征子集。
8、可选的,首先分别对秩相关系数、灰色关联分析系数和最大信息系数进行标准化,并根据标准化后的数据分别求各数据对应的信息熵;根据各数据的信息熵计算该方法在综合排序得分计算中的所占的权重。
9、可选的,在步骤3中具体包括以下步骤:
10、步骤3.1、对步骤1中的秩相关系数中的元素[s1,s2,…,si,…,sn],按照数值降序排序,得到新向量则秩相关系数的元素si在向量中的排序的序号设为预测目标参数as与特征集合中ai的秩相关系数排序得分osi,osi∈[1,n];
11、步骤3.2、对灰色关联分析系数,最大信息系数按照步骤3.1中的过程进行相同的操作,得到使用灰色关联方法以及最大信息系数方法下,预测目标参数as与特征参数ai排序得分分别为ogi,omi,并计算最终特征参数ai的得分ci;
12、对于预测目标参数as,与所有特征参数a1,a2…,ai…,an的综合排序列表记为c_score=[c1,c2,…ci…,cn]。
13、可选的,在步骤4中,特征动态阈值为:
14、
15、ci表示特征参数ai的得分;对于预测目标参数as,与所有特征参数a1,a2…,ai…,an的综合排序列表记为c_s core=[c1,c2,…ci…,cn]。
16、可选的,最终特征参数ai的得分如下:
17、
18、其中,秩相关系数、灰色关联分析系数和最大信息系数在综合排序得分计算中的所占的权重为η、θ、在向量中的排序的序号设为预测目标参数as与特征集合中ai的秩相关系数排序得分为osi,灰色关联分析系数和最大信息系数分别对应的排序得分为ogi,omi。
19、一种基于熵权法的综合排序自适应特征选择系统,包括:
20、数据获取与计算模块:用于获取工业生产检测特征参数的数据集,计算预测目标参数与各特征参数之间的秩相关系数、灰色关联分析系数和最大信息系数;
21、数据赋权模块:用于应用熵权法为秩相关系数、灰色关联分析系数和最大信息系数赋权;
22、综合排序列表模块:用于基于赋权结果计算预测目标参数与所有特征参数的综合排序列表;
23、优化特征子集输出模块:用于根据几何平均函数方法求得预测目标的特征动态阈值,选取综合排序列表中预测目标小于特征动态阈值的所有特征作为预测目标的最终优化特征子集。
24、经由上述的技术方案可知,与现有技术相比,本发明提供了一种基于熵权法的综合排序自适应特征选择方法及系统,针对时序数据的趋势跟踪预测研究,基于对高维输入数据进行特征优化的需求,剔除对预测无效的特征参数,利用相关性分析的方法对输入参数进行过滤筛选,寻求建立最优特征子集的研究方法,并通过lstm预测模型进行预测精度验证。此方法的优势在于:针对时序数据预测中存在与预测目标无关的无效参数、造成网络复杂度高的问题,提出3种不同相关性分析方法进行特征优化,采取相关性系数降序排序方式剔除无关特征,并根据阈值自适应筛选出最优特征子集,减少由于人为主观设置权重带来的较大的误差波动,同时也降低了预测网络的复杂度,提高了预测参数的精度。
技术特征:
1.一种基于熵权法的综合排序自适应特征选择方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于熵权法的综合排序自适应特征选择方法,其特征在于,首先分别对秩相关系数、灰色关联分析系数和最大信息系数进行标准化,并根据标准化后的数据分别求各数据对应的信息熵;根据各数据的信息熵计算该方法在综合排序得分计算中的所占的权重。
3.根据权利要求1所述的一种基于熵权法的综合排序自适应特征选择方法,其特征在于,在步骤3中具体包括以下步骤:
4.根据权利要求1所述的一种基于熵权法的综合排序自适应特征选择方法,其特征在于,在步骤4中,特征动态阈值为:
5.根据权利要求3所述的一种基于熵权法的综合排序自适应特征选择方法,其特征在于,最终特征参数ai的得分如下:
6.一种基于熵权法的综合排序自适应特征选择系统,其特征在于,包括:
技术总结
本发明公开了一种基于熵权法的综合排序自适应特征选择方法及系统,涉及工业生产检测领域。步骤1、获取工业生产检测特征参数的数据集,计算预测目标参数与各特征参数之间的秩相关系数、灰色关联分析系数和最大信息系数;步骤2、应用熵权法为秩相关系数、灰色关联分析系数和最大信息系数赋权;步骤3、基于赋权结果计算预测目标参数与所有特征参数的综合排序列表;步骤4、根据几何平均函数方法求得预测目标的特征动态阈值,选取综合排序列表中预测目标小于特征动态阈值的所有特征作为预测目标的最终优化特征子集。本发明依据各相关性分析算法的系数的信息熵设置各算法所得系数的权值,根据几何平均法给出阈值,自适应的选择预测参数的特征子集。
技术研发人员:戴运桃,刘利强,王宇晴,沈继红
受保护的技术使用者:浙江科技大学
技术研发日:
技术公布日:2024/7/18
- 还没有人留言评论。精彩留言会获得点赞!