一种文字信息碎片整合方法与流程
本发明涉及信息整合处理,特别涉及一种文字信息碎片整合方法。
背景技术:
1、随着互联网技术的发展与普及,越来越多的技术文献开始增加并被有效保存,因此也带来了一定的查阅难度,而目前相关技术往往只能够进行一定的文件搜索并下载,缺少相应的信息提取能力,进而导致无法及时有效的针对关键信息进行识别,从而不方便文件获取与管理。
技术实现思路
1、本发明的目的是提供一种文字信息碎片整合方法,解决了现有技术中文件识别精度较差、不方便信息整合管理的技术问题,实现了提高文件识别精度、方便信息整合管理的技术效果。
2、为了达到上述发明目的,本发明采用的技术方案为:
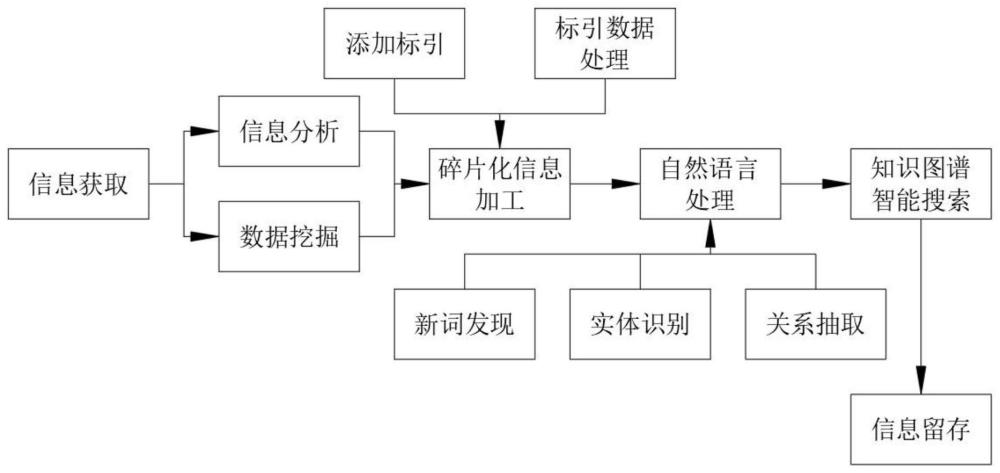
3、一种文字信息碎片整合方法,包括以下步骤:步骤1、获取相应信息数据后分别进行信息分析与数据挖掘,把结构化的文献按照知识体系定义的颗粒度,提取出有意义的知识单元,并归入知识体系的架构中,完成初步处理;
4、步骤2、将步骤1中提取出的知识单元进行结构化加工,形成用xml表示的内容资源包,随后使用标引工具对内容进行标引数据处理;
5、步骤3、将步骤2中xml资源包进行自然语言处理,所述自然语言处理包括新词发现、实体识别和关系抽取,所述新词发现将处理后的数据与资料库中已有语料结合进行挖掘,从而识别出新词;所述实体识别会抽取文本中的信息元素,所述信息元素包括人名、组织或机构名、地理位置、时间或日期、字符值和相关领域专有名词等;所述关系抽取在识别出关键实体后会抽取实体之间的语义关系,并识别相应文本的主要含义;
6、步骤4、将步骤3中完成处理的文件结合知识图谱进行智能搜索,所述智能搜索会提取出相应的关键词以及表单信息等,随后通过匹配处理后进行结果展示。
7、作为改进,所述步骤1中信息分析包括句法分析、语义分析和文本分类,所述数据挖掘还包括机器学习,所述输入信息数据后文本结构形式分析破碎成主谓宾结构,并根据前后语义进一步限制相应词语的应用范围,随后进行文本分类供机器学习与数据挖掘。
8、作为改进,所述数据挖掘包括语义计算、机器翻译、知识挖掘、新词发现、图片比对等,能够自动从文献资源中抽取相应表述概念、图片、知识点、数值、表格等各类知识单元。
9、作为改进,所述步骤2中标引数据处理包括知识元智能标引、关联关系标引、标签标引和知识元抽取和标引,所述知识元智能标引调用基于句法分析、语义分析,数据挖掘等技术的接口自动提取出知识元,同时自动归入知识体系的架构中,并给出置信度,然后确定是否需要人工检查或进一步标引。
10、作为改进,步骤3中新词发现包括基于规则的新词识别和基于统计的新词识别,所述基于规则的新词识别,基于规则的方法一般通过语言专家根据构词学原理、配合语义信息或词性信息来构造模板,然后匹配新词;所述基于统计的新词识别包括监督方法和无监督方法,所述监督方法利用标注语料,将新词识别问题看作分类或者序列标注问题,所述无监督方法利用候选字符串的统计信息,设定阈值进行判别。
11、作为改进,所述步骤4中智能搜索会结合存储的语义模型进一步细化搜索内容,所述匹配处理包括ir-style匹配和排序、db-style精确匹配和kb-style匹配和推理。
12、本发明的有益效果为:通过对信息进行碎片化加工可以快速提取相应关键信息,同时也可以对其进行标引数据处理,方便查询相关文件保证文件处理的准确性,通过自然语言处理可以进一步的处理文本内容,进而提高识别准确性。
技术特征:
1.一种文字信息碎片整合方法,其特征在于,包括以下步骤:步骤1、获取相应信息数据后分别进行信息分析与数据挖掘,把结构化的文献按照知识体系定义的颗粒度,提取出有意义的知识单元,并归入知识体系的架构中,完成初步处理;
2.根据权利要求1所述的一种文字信息碎片整合方法,其特征在于,所述步骤1中信息分析包括句法分析、语义分析和文本分类,所述数据挖掘还包括机器学习,所述输入信息数据后文本结构形式分析破碎成主谓宾结构,并根据前后语义进一步限制相应词语的应用范围,随后进行文本分类供机器学习与数据挖掘。
3.根据权利要求2所述的一种文字信息碎片整合方法,其特征在于,所述数据挖掘包括语义计算、机器翻译、知识挖掘、新词发现、图片比对等,能够自动从文献资源中抽取相应表述概念、图片、知识点、数值、表格等各类知识单元。
4.根据权利要求1所述的一种文字信息碎片整合方法,其特征在于,所述步骤2中标引数据处理包括知识元智能标引、关联关系标引、标签标引和知识元抽取和标引,所述知识元智能标引调用基于句法分析、语义分析,数据挖掘等技术的接口自动提取出知识元,同时自动归入知识体系的架构中,并给出置信度,然后确定是否需要人工检查或进一步标引。
5.根据权利要求1所述的一种文字信息碎片整合方法,其特征在于,步骤3中新词发现包括基于规则的新词识别和基于统计的新词识别,所述基于规则的新词识别,基于规则的方法一般通过语言专家根据构词学原理、配合语义信息或词性信息来构造模板,然后匹配新词;所述基于统计的新词识别包括监督方法和无监督方法,所述监督方法利用标注语料,将新词识别问题看作分类或者序列标注问题,所述无监督方法利用候选字符串的统计信息,设定阈值进行判别。
6.根据权利要求1所述的一种文字信息碎片整合方法,其特征在于,所述步骤4中智能搜索会结合存储的语义模型进一步细化搜索内容,所述匹配处理包括ir-style匹配和排序、db-style精确匹配和kb-style匹配和推理。
技术总结
本发明提供的一种文字信息碎片整合方法,涉及信息整合处理技术领域,其特征在于,包括以下步骤:步骤1、获取相应信息数据后分别进行信息分析与数据挖掘;步骤2、将步骤1中提取出的知识单元进行结构化加工,形成用XML表示的内容资源包,随后使用标引工具对内容进行标引数据处理;步骤3、将步骤2中XML资源包进行自然语言处理,所述自然语言处理包括新词发现、实体识别和关系抽取;步骤4、将步骤3中完成处理的文件结合知识图谱进行智能搜索,所述智能搜索会提取出相应的关键词以及表单信息等,随后通过匹配处理后进行结果展示。本发明的优点:文字信息识别精度高,方便整合管理。
技术研发人员:张金营,王天堃,么长英,孙鹏
受保护的技术使用者:国电电力发展股份有限公司北京分公司
技术研发日:
技术公布日:2024/9/12
- 还没有人留言评论。精彩留言会获得点赞!