一种基于最大熵的多智能体协同方法和装置与流程
本发明涉及强化学习领域,特别是涉及一种基于最大熵的多智能体协同方法和装置。
背景技术:
1、强化学习(reinforcement learning,简写为rl)作为机器学习的第三范式,克服了监督学习需要大量标注数据集的约束,在建模难、建模不准确的问题上取得了良好的表现。自q学习(q-learning)等基于动作价值函数的强化学习技术出现以来,强化学习快速从单智能体算法发展到了多智能体算法。至今,多智能体强化学习已经成功应用于在游戏、围棋、机器人和无人机等领域。
2、然而,在多智能体环境中,维数灾难(curse of dimensionality)使得探索困难急剧增加,在有限时间内智能体不可能实现对环境的完全探索,导致关键状态难以选择和协同探索,造成了算法的探索效率急剧下降,阻碍着多智能体强化学习在现实世界的广泛应用。
3、鉴于此,如何克服现有技术所存在的缺陷,解决多智能体环境中维数灾难导致的探索效率下降的现象,是本技术领域待解决的问题。
技术实现思路
1、针对现有技术的以上缺陷或改进需求,本发明解决了多智能体环境中维数灾难导致的探索效率下降的问题。
2、本发明实施例采用如下技术方案:
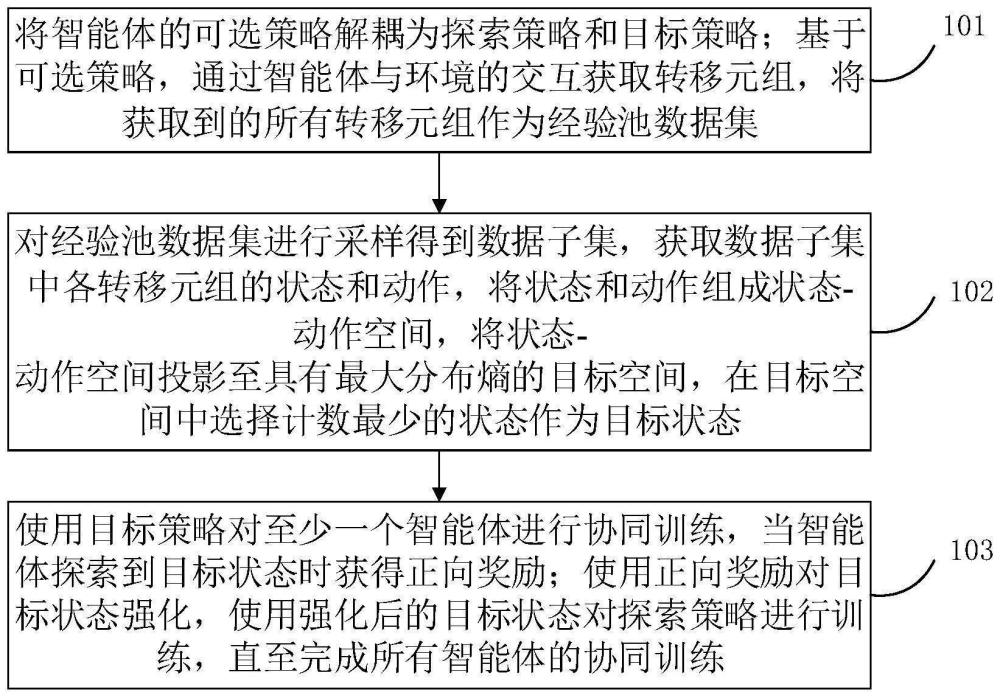
3、第一方面,本发明提供了一种基于最大熵的多智能体协同方法,具体为:将智能体的可选策略解耦为探索策略和目标策略;基于可选策略,通过智能体与环境的交互获取转移元组,将获取到的所有转移元组作为经验池数据集;对经验池数据集进行采样得到数据子集,获取数据子集中各转移元组的状态和动作,将状态和动作组成状态-动作空间,将状态-动作空间投影至具有最大分布熵的目标空间,在目标空间中选择计数最少的状态作为目标状态;使用目标策略对至少一个智能体进行协同训练,当智能体探索到目标状态时获得正向奖励;使用正向奖励对目标状态强化,使用强化后的目标状态对探索策略进行训练,直至完成所有智能体的协同训练。
4、优选的,所述将智能体的可选策略解耦为探索策略和目标策略,具体包括:当一个可选策略用于训练智能体对目标状态的访问,和/或,用于收集数据时,将该可选策略作为探索策略;当一个可选策略用于获取最大化环境奖励时,将该可选策略作为目标策略。
5、优选的,所述基于可选策略,通过智能体与环境的交互获取转移元组,具体包括:在每一个回合,重置环境状态为第一状态,并获得至少一个智能体的第一联合观测;其中,每个回合包括至少一个时间步;在每一个时间步,每个智能体按照探索策略或目标策略,根据全局状态选择自身的动作,将所有智能体选择的动作组成联合动作;在每一个时间步执行联合动作后,全局状态转变为第二状态,且智能体得到环境奖励和第二联合观测;将每一个时间步的第一状态、第一联合观测、联合动作、第二状态、第二联合观测和环境奖励组成当前时间步的转移元组。
6、优选的,所述获得至少一个智能体的第一联合观测,具体包括:每个智能体对第一状态进行观测获得该智能体的局部观测,将所有智能体的局部观测组成第一联合观测。
7、优选的,所述将状态和动作组成状态-动作空间,将状态-动作空间投影至具有最大分布熵的目标空间,在目标空间中选择计数最少的状态作为目标状态,具体包括:将每一个转移元组里同一时刻的状态和动作拼接为列向量,将所有的列向量组成状态-动作空间;利用梯度下降算法将状态-动作空间投影到分布熵最大的目标空间,使用基于计数的方法在目标空间中筛选计数最少的状态,将筛选出的状态作为目标状态。
8、优选的,所述将每一个转移元组里同一时刻的状态和动作拼接为列向量,具体包括:对于数据子集中的每一个转移元组,获取其中的第一状态和联合动作,将第一状态和联合动作拼接为列向量。
9、优选的,所述利用梯度下降算法将状态-动作空间投影到分布熵最大的目标空间,使用基于计数的方法在目标空间中筛选计数最少的状态,将筛选出的状态作为目标状态,具体包括:利用梯度下降法,将状态-动作空间投影至具有最大分布熵的最佳投影矩阵中,将投影结果作为目标空间;统计目标空间中各列向量的计数,选择具有最小计数的列向量中的第一状态作为目标状态。
10、优选的,所述当智能体探索到目标状态时获得正向奖励,具体包括:对于经验池数据集中的每一个转移元组,比较目标状态和该转移元组中的第一状态;如果目标状态和第一状态等同,将该转移元组中的奖励值设置为指定的正向奖励。
11、第二方面,本发明提供了一种基于最大熵的多智能体协同装置,具体为:包括至少一个处理器和存储器,至少一个处理器和存储器之间通过数据总线连接,存储器存储能被至少一个处理器执行的指令,指令在被处理器执行后,用于完成第一方面中的基于最大熵的多智能体协同方法。
12、第三方面,本发明还提供了一种非易失性计算机存储介质,所述计算机存储介质存储有计算机可执行指令,该计算机可执行指令被一个或多个处理器执行,用于完成第一方面所述的方法。
13、第四方面,提供了一种芯片,包括:处理器和接口,用于从存储器中调用并运行存储器中存储的计算机程序,执行如第一方面的方法。
14、第五方面,提供了一种包含指令的计算机程序产品,当该指令在计算机或处理器上运行时,使得计算机或处理器执行如第一方面的方法。
15、与现有技术相比,本发明的有益效果在于:通过状态空间投影的方法将直接获取到的状态-动作空间投影到具有最大状态-动作分布熵的目标空间,基于计数的方法筛选目标状态,并通过奖励重塑的方式达到协同训练的目的,从而解决多智能体强化学习中智能体面对维数灾难难以识别且协同探索有价值的关键状态的痛点,实现多智能体之间的协同探索和系统整体的优化。
技术特征:
1.一种基于最大熵的多智能体协同方法,其特征在于,包括:
2.根据权利要求1所述的基于最大熵的多智能体协同方法,其特征在于,所述将智能体的可选策略解耦为探索策略和目标策略,具体包括:
3.根据权利要求1所述的基于最大熵的多智能体协同方法,其特征在于,所述基于可选策略,通过智能体与环境的交互获取转移元组,具体包括:
4.根据权利要求3所述的基于最大熵的多智能体协同方法,其特征在于,所述获得至少一个智能体的第一联合观测,具体包括:
5.根据权利要求1所述的基于最大熵的多智能体协同方法,其特征在于,所述将状态和动作组成状态-动作空间,将状态-动作空间投影至具有最大分布熵的目标空间,在目标空间中选择计数最少的状态作为目标状态,具体包括:
6.根据权利要求5所述的基于最大熵的多智能体协同方法,其特征在于,所述将每一个转移元组里同一时刻的状态和动作拼接为列向量,具体包括:
7.根据权利要求5所述的基于最大熵的多智能体协同方法,其特征在于,所述利用梯度下降算法将状态-动作空间投影到分布熵最大的目标空间,使用基于计数的方法在目标空间中筛选计数最少的状态,将筛选出的状态作为目标状态,具体包括:
8.根据权利要求1所述的基于最大熵的多智能体协同方法,其特征在于,所述当智能体探索到目标状态时获得正向奖励,具体包括:
9.一种基于最大熵的多智能体协同装置,其特征在于:
10.一种非易失性计算机存储介质,其特征在于,所述计算机存储介质存储有计算机可执行指令,该计算机可执行指令被一个或多个处理器执行,用于完成如权利要求1-8任一项所述的基于最大熵的多智能体协同方法。
技术总结
本发明涉及强化学习领域,特别是涉及一种基于最大熵的多智能体协同方法和装置。包括:通过智能体与环境的交互获取转移元组,将获取到的所有转移元组作为经验池数据集;数据子集中各转移元组的状态和动作,将状态和动作组成状态‑动作空间,将状态‑动作空间投影至具有最大分布熵的目标空间,在目标空间中选择计数最少的状态作为目标状态;使用目标策略对至少一个智能体进行协同训练,当智能体探索到目标状态时获得正向奖励;使用正向奖励对目标状态强化,使用强化后的目标状态对探索策略进行训练。本发明可以解决多智能体强化学习中智能体面对维数灾难难以识别且协同探索有价值的关键状态的痛点,实现多智能体之间的协同探索和系统整体的优化。
技术研发人员:汤海南,刘俊涛,王振杰,高子文,饶子昀
受保护的技术使用者:中国船舶集团有限公司第七〇九研究所
技术研发日:
技术公布日:2024/8/20
- 还没有人留言评论。精彩留言会获得点赞!