一种扩展布隆过滤器的数据库索引结构及其构建方法与流程
本发明涉及计算机,尤其涉及一种扩展布隆过滤器的数据库索引结构及其构建方法。
背景技术:
1、布隆过滤器是1970年由布隆提出的,它的核心实现是一个超大的位数组和一系列随机映射函数,布隆过滤器可以用于检索一个元素是否在一个集合中,是一种能够过滤掉不属于集合的元素并表示集合、支持集合查询的简洁数据结构,它的原理是,当一个元素被加入集合时,通过k个散列函数将这个元素映射成一个位数组中的k个点,把这些点都置为1,在检索时,再次通过k个散列函数将这个元素映射成一个位数组中的k个点,查看这k个点是否全为1:如果这些点有任何一个点为0,则被检索的元素一定不存在;若这些点均为1,则变检索的元素可能存在。
2、相比与其他的数据结构,布隆过滤器在空间和时间方面都有巨大的优势,布隆过滤器存储空间复杂度和插入/查询的时间复杂度都是常数级(o(k)),除此之外,散列函数相互之间没有任何关系,方便由硬件并行实现,因此,布隆过滤器自提出以来,被广泛应用到各种计算机系统中,以提高数据集的查找效率,其主要应用场景包括:网页url去重、垃圾邮件判别、集合重复元素判别和查询加速。
3、现有的布隆过滤器大都忽略了布隆过滤器的可扩展性问题,随着存入的元素数量增加,误算率也随之增加,现有的发明大多是将过滤器的位向量转换为由多个位向量组成的矩阵来解决可扩展性问题,这样的做法虽能在一定程度上缓解布隆过滤器在实际使用时随着元素个数增加,误判率也将随之飙升的问题,但此类方法的查询时间复杂度较高,仍有一定的改进空间。
4、因此,有必要提供一种扩展布隆过滤器的数据库索引结构及其构建方法解决上述技术问题。
技术实现思路
1、本发明提供一种扩展布隆过滤器的数据库索引结构,解决了布隆过滤器随着存入的元素数量增加,误算率也随之增加的问题。
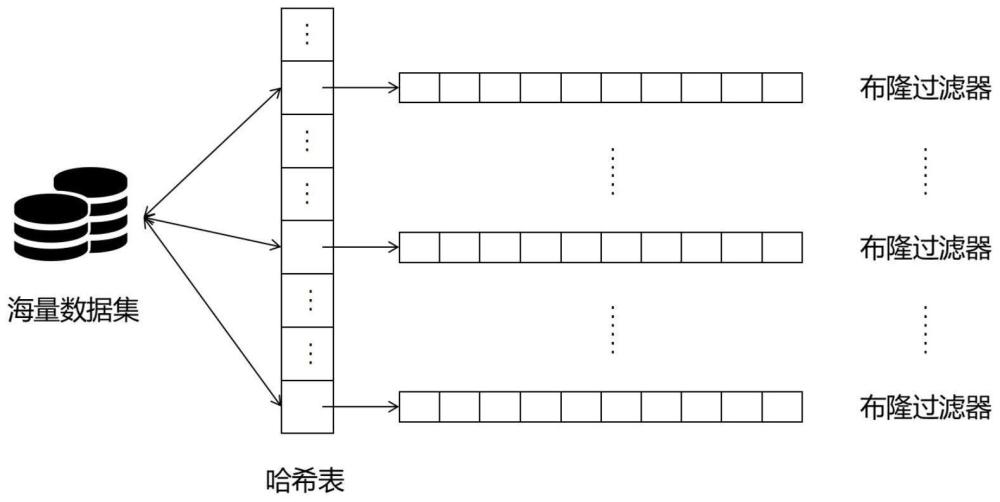
2、为解决上述技术问题,本发明提供的扩展布隆过滤器的数据库索引结构包括:海量数据集、哈希表和布隆过滤器,所述海量数据集是一个不断膨胀的数据集合,该数据集合包含了大量的元素:
3、(海量数据集);
4、其中,哈希表与海量数据集中元素存在映射关系,依据特定的哈希算法,海量数据集中的元素指向哈希表的不同键:
5、
6、优选的,所述哈希表的键与值呈一一映射关系:
7、
8、优选的,所述哈希表的每对键值与布隆过滤器呈一一映射关系:
9、
10、优选的,所述布隆过滤器的状态位根据插入数据的哈希序列及布隆过滤器的位数设定:
11、data∈datak
12、keyk=hash(datak)
13、valuek=mapping(keyk)
14、bloomfilterk=bfmapping(valuek)
15、
16、优选的,所述数据的哈希序列由系列哈希函数计算:
17、
18、一种扩展布隆过滤器的数据库索引结构的构建方法,包括以下步骤:
19、s1插入数据;
20、s2获取与插入数据相映射的哈希表;
21、s3获取哈希表键值对;
22、s4通过键值对获取布隆过滤器;
23、s5计算数据的哈希序列;
24、s6设置布隆过滤器状态位;
25、s7布隆过滤器的误判率是否接近阈值;
26、s8数据是否全部插入。
27、优选的,其特征在于,所述s7步骤中,布隆过滤器的误判率若为是,则动态生成新的哈希表键值对及布隆过滤器。
28、优选的,其特征在于,所述s8步骤中数据是否全部插入若为否,则从海量数据集中获取新的数据。
29、与相关技术相比较,本发明提供的扩展布隆过滤器的数据库索引结构具有如下有益效果:
30、本发明提供一种扩展布隆过滤器的数据库索引结构,针对现有技术存在的缺陷,在集合元素增加时,布隆过滤器的误判率也随之迅速攀升,在面对海量数据时,布隆过滤器的误判率可能会超出可接受范围,甚至会达到1,本发明的扩展布隆过滤器的新型索引结构,当集合元素不断增多时,通过不断增多布隆过滤器的数量来降低布隆过滤器的误判率,并以此为基础,给出了扩展布隆过滤器的新型索引结构的构建方法。
技术特征:
1.一种扩展布隆过滤器的数据库索引结构,其特征在于,包括:
2.根据权利要求1所述的扩展布隆过滤器的数据库索引结构,其特征在于,所述哈希表的键与值呈一一映射关系:
3.根据权利要求1所述的扩展布隆过滤器的数据库索引结构,其特征在于,所述哈希表的每对键值与布隆过滤器呈一一映射关系:
4.根据权利要求1所述的扩展布隆过滤器的数据库索引结构,其特征在于,所述布隆过滤器的状态位根据插入数据的哈希序列及布隆过滤器的位数设定:
5.根据权利要求4所述的扩展布隆过滤器的数据库索引结构,其特征在于,所述数据的哈希序列由系列哈希函数计算:
6.一种扩展布隆过滤器的数据库索引结构的构建方法,其特征在于,包括以下步骤:
7.根据权利要求6所述的扩展布隆过滤器的数据库索引结构的构建方法,其特征在于,所述s7步骤中,布隆过滤器的误判率若为是,则动态生成新的哈希表键值对及布隆过滤器。
8.根据权利要求6所述的扩展布隆过滤器的数据库索引结构的构建方法,其特征在于,所述s8步骤中数据是否全部插入若为否,则从海量数据集中获取新的数据。
技术总结
本发明提供一种扩展布隆过滤器的数据库索引结构。所述扩展布隆过滤器的数据库索引结构包括:海量数据集、哈希表和布隆过滤器,所述海量数据集是一个不断膨胀的数据集合,该数据集合包含了大量的元素;其中,哈希表与海量数据集中元素存在映射关系。本发明提供的扩展布隆过滤器的数据库索引结构具有针对现有技术存在的缺陷,在集合元素增加时,布隆过滤器的误判率也随之迅速攀升,在面对海量数据时,布隆过滤器的误判率可能会超出可接受范围,甚至会达到1,本发明的扩展布隆过滤器的新型索引结构,当集合元素不断增多时,通过不断增多布隆过滤器的数量来降低布隆过滤器的误判率,并以此为基础,给出了扩展布隆过滤器的新型索引结构的构建方法。
技术研发人员:欧阳义林
受保护的技术使用者:智链未来(深圳)科技有限责任公司
技术研发日:
技术公布日:2024/6/23
- 还没有人留言评论。精彩留言会获得点赞!