模型的训练方法、装置、存储介质、电子装置及计算机程序产品与流程
本发明实施例涉及金融领域,具体而言,涉及一种模型的训练方法、装置、存储介质、电子装置及计算机程序产品。
背景技术:
1、随着人工智能技术的发展,对文本数据的人为审核逐渐被淘汰,借助科技的力量优化财务风险识别自动化流程越来越完善。在相关技术中,可以利用深度学习模型对文本数据进行识别,以确定企业是否存在风险。
2、然而,在相关技术中存在深度学习模型识别企业风险不准确的问题。
3、针对相关技术中存在的上述问题,目前尚未提出有效的解决方案。
技术实现思路
1、本发明实施例提供了一种模型的训练方法、装置、存储介质、电子装置及计算机程序产品,以至少解决相关技术中存在的深度学习模型识别企业风险不准确的问题。
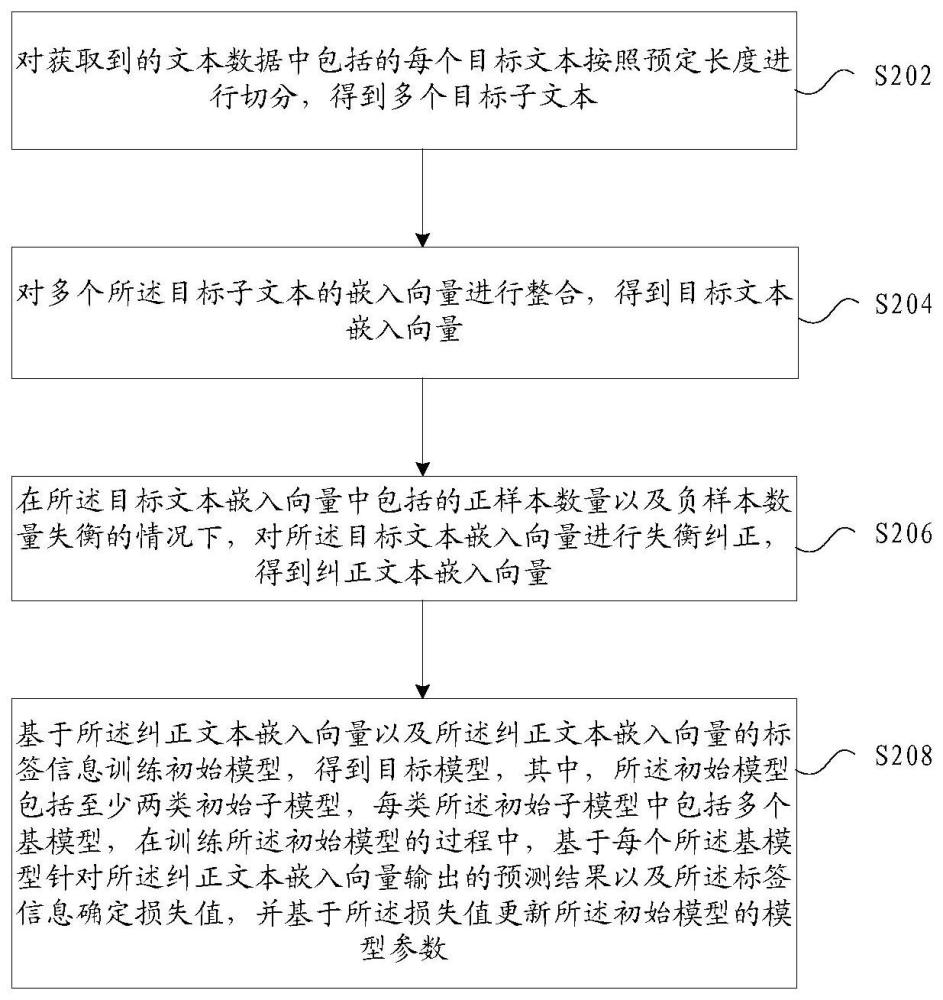
2、根据本发明的一个实施例,提供了一种模型的训练方法,包括:对获取到的文本数据中包括的每个目标文本按照预定长度进行切分,得到多个目标子文本;对多个所述目标子文本的嵌入向量进行整合,得到目标文本嵌入向量;在所述目标文本嵌入向量中包括的正样本数量以及负样本数量失衡的情况下,对所述目标文本嵌入向量进行失衡纠正,得到纠正文本嵌入向量;基于所述纠正文本嵌入向量以及所述纠正文本嵌入向量的标签信息训练初始模型,得到目标模型,其中,所述初始模型包括至少两类初始子模型,每类所述初始子模型中包括多个基模型,在训练所述初始模型的过程中,基于每个所述基模型针对所述纠正文本嵌入向量输出的预测结果以及所述标签信息确定损失值,并基于所述损失值更新所述初始模型的模型参数。
3、根据本发明的另一个实施例,提供了一种模型的训练装置,包括:切分模块,用于对获取到的文本数据中包括的每个目标文本按照预定长度进行切分,得到多个目标子文本;整合模块,用于对多个所述目标子文本的嵌入向量进行整合,得到目标文本嵌入向量;纠正模块,用于在所述目标文本嵌入向量中包括的正样本数量以及负样本数量失衡的情况下,对所述目标文本嵌入向量进行失衡纠正,得到纠正文本嵌入向量;训练模块,用于基于所述纠正文本嵌入向量以及所述纠正文本嵌入向量的标签信息训练初始模型,得到目标模型,其中,所述初始模型包括至少两类初始子模型,每类所述初始子模型中包括多个基模型,在训练所述初始模型的过程中,基于每个所述基模型针对所述纠正文本嵌入向量输出的预测结果以及所述标签信息确定损失值,并基于所述损失值更新所述初始模型的模型参数。
4、根据本发明的又一个实施例,还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行上述任一项方法实施例中的步骤。
5、根据本发明的又一个实施例,还提供了一种电子装置,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行上述任一项方法实施例中的步骤。
6、根据本发明的又一个实施例,还提供了一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现本申请各个实施例中所述方法的步骤。
7、通过本发明,可以对获取到的文本数据按照预定长度进行切分,得到多个目标子文本,对多个目标子文本的嵌入向量进行整合,得到目标文本嵌入向量,在目标文本嵌入向量中包括的正文本数量以及负样本数量失衡的情况下,对目标文本嵌入向量进行失衡纠正,得到纠正文本嵌入向量,根据纠正文本嵌入向量以及纠正文本嵌入向量的标签信息训练初始模型,得到目标模型。初始模型包括至少两类初始子模型,每类初始子模型中包括多个基模型,在训练初始模型的过程中,基于每个基模型针对纠正文本嵌入向量输出的预测结果以及标签信息确定损失值,并基于损失值更新初始模型的模型参数。由于可以对文本数据按照预定长度进行切分,规范了网络的输入长度,对多个目标子文本的嵌入向量进行整合,实现了利用整合了不同子句的嵌入向量的目标文本嵌入向量训练初始模型,有利于提高模型对风险的识别能力。通过对失衡文本进行纠正,极大地缓解了样本失衡对模型训练的影响,初始模型包括至少两类初始子模型,每类初始子模型中包括多个基模型,即引入多模对抗融合的思想,有机的组合同水平性能表现接近的不同模型,改善系统整体的性能表现。因此,可以解决相关技术中存在的深度学习模型识别企业风险不准确的问题,达到提高识别企业风险的准确率的效果。
技术特征:
1.一种模型的训练方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,对获取到的文本数据中包括的每个目标文本按照预定长度进行切分,得到多个目标子文本包括:
3.根据权利要求1所述的方法,其特征在于,对多个所述目标子文本的嵌入向量进行整合,得到目标文本嵌入向量包括:
4.根据权利要求1所述的方法,其特征在于,对所述目标文本嵌入向量进行失衡纠正,得到纠正文本嵌入向量包括:
5.根据权利要求4所述的方法,其特征在于,在所述第二子嵌入向量中添加扰动,得到第三子嵌入向量包括:
6.根据权利要求1所述的方法,其特征在于,基于所述纠正文本嵌入向量以及所述纠正文本嵌入向量的标签信息训练初始模型,得到目标模型包括:
7.根据权利要求1所述的方法,其特征在于,在基于所述纠正文本嵌入向量以及所述纠正文本嵌入向量的标签信息训练初始模型,得到目标模型之后,所述方法还包括:
8.根据权利要求1所述的方法,其特征在于,在对获取到的文本数据中包括的每个目标文本按照预定长度进行切分之前,所述方法还包括:
9.一种模型的训练装置,其特征在于,包括:
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行所述权利要求1至8任一项中所述的方法。
11.一种电子装置,包括存储器和处理器,其特征在于,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行所述权利要求1至8任一项中所述的方法。
12.一种计算机程序产品,包括计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1至8任一项中所述方法的步骤。
技术总结
本发明实施例提供了一种模型的训练方法、装置、存储介质、电子装置及计算机程序产品,其中,该方法包括:对获取到的文本数据中包括的每个目标文本按照预定长度进行切分,得到多个目标子文本;对多个目标子文本的嵌入向量进行整合,得到目标文本嵌入向量;在目标文本嵌入向量中包括的正样本数量以及负样本数量失衡的情况下,对目标文本嵌入向量进行失衡纠正,得到纠正文本嵌入向量;基于纠正文本嵌入向量以及纠正文本嵌入向量的标签信息训练初始模型,得到目标模型。通过本发明,解决了相关技术中存在的深度学习模型识别企业风险不准确的问题,达到提高识别企业风险的准确率的效果。
技术研发人员:田雨
受保护的技术使用者:中国建设银行股份有限公司
技术研发日:
技术公布日:2024/8/16
- 还没有人留言评论。精彩留言会获得点赞!