基于原文复述机制的食品安全大模型上下文扩展微调方法与流程
本申请涉及计算机,特别涉及一种基于原文复述机制的食品安全大模型上下文扩展微调方法。
背景技术:
1、当前,许多开源llm(large language models)已经拥有了接近gpt-3.5的文本生成能力。然而,大部分开源模型的context window都不超过4k,上下文长度受到限制,也就限制了其应用,难以应对超长文档、超多轮数交互等问题。而食品安全大模型,需要外挂食品安全领域知识,常常需要给模型输入几千字以上的文档,导致超出现有模型能够处理的文本长度。
2、随着长文本模型的快速发展与迭代加强,例如gpt-4-128k与claude-2-200k等均具备了一定的长文本处理能力,但是均属于不开源的模型。同时由于训练成本高和训练数据极为保密的问题,导致难以应用于食品安全大模型。针对于开源的模型,例如llama-yarn和longalpaca等,虽然上下文窗口已经扩展至32k甚至更长,但其长文本chat的准确性还远不足以令人满意,导致当前对于技能扩展上下文窗口,同时保持模型性能的方法具备极大的需求。
3、由于食品安全领域细节知识很多,因此若期望与计算机能够实现准确回答问题,则计算机内的食品安全大模型需要结合大量的外部知识,例如标准文件、检测历史数据库等。基于此,在向计算机提问时,则需要通过向食品安全大模型输入很长的文本,才能够保证一定的准确性。
4、但是,由于现有大部分语言模型输入长度少于4k,难以满足食品安全领域外挂知识库的需要,且由于输入长度较短,从而影响到问答的准确性,有待改进。
技术实现思路
1、有鉴于此,本申请的目的在于提供一种基于原文复述机制的食品安全大模型上下文扩展微调方法,以实现在控制成本时有效提高长文本的问答准确率的目的。其具体方案如下:
2、一种基于原文复述机制的食品安全大模型上下文扩展微调方法,所述方法包括:
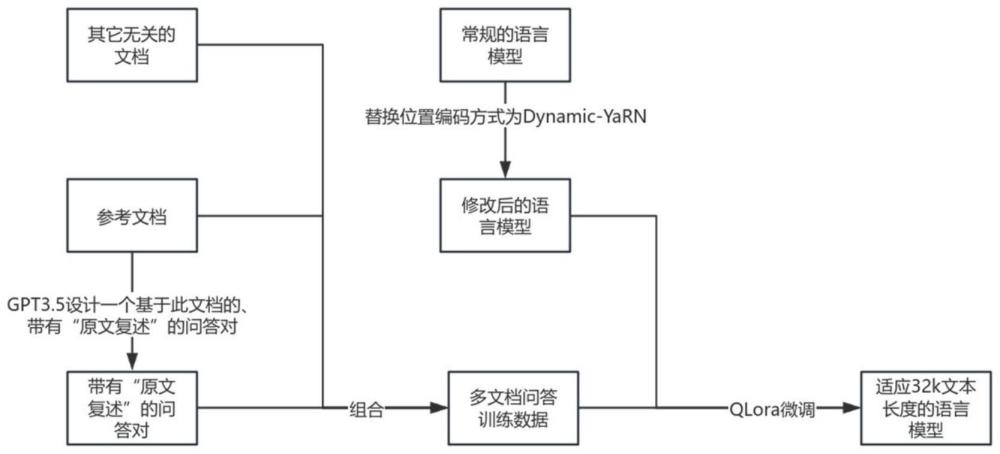
3、设立参考文档,以多个参考文档形成组,取第一个参考文档设计问答对,在问答对的回答中给出相关原文;
4、将组内参考文档顺序打乱,并形成参考文档列表以及指令微调数据;
5、设立语言模型,将指令微调数据导入语言模型,训练微调以获得长文本语言模型。
6、优选地:所述参考文档为悟道开源中文语料或commoncrawl数据集。
7、优选地:所述指令微调数据的数据长度大于8k且小于32k,并包括gpt-3.5设计问题与gpt-3.5设计回答。
8、优选地:所述语言模型为qwen-14b-chat模型。
9、优选地:所述qwen-14b-chat模型采用将位置编码方法替换为dynamic-yarn。
10、优选地:所述训练微调采用qlora训练,并将回答纳入loss计算,微调qwen的所有linear层。
11、优选地:在所述训练微调中,采用将指令微调数据的回答部分加入回答问题所需的相关原文。
12、优选地:所述相关原文为与回答弱相关或强相关的上下文。
13、通过以上方案可知,本申请提供了基于原文复述机制的食品安全大模型上下文扩展微调方法,该基于原文复述机制的食品安全大模型上下文扩展微调方法具有以下有益效果:
14、1、通过原文复述机制下原文复述的形式增强数据有效性;
15、2、通过解决现有语言模型在面对长文本时存在的问答准确率低、忽略上下文中间部分信息的问题的效果,有效提高长文本的问答准确率,且通过避免人工标注导致的成本显著增加的问题;
16、3、通过gpt-3.5自动化构建带有相关原文的多文档问答数据,从而实现简单、高效和高质量的数据构造的效果;
17、4、通过指令微调数据的搭建,基于qlora,训练获得的llm具有高长文本问答准确率,并在longbench的passage_retrival_zh数据集中达到0.94的高分。
技术特征:
1.一种基于原文复述机制的食品安全大模型上下文扩展微调方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于原文复述机制的食品安全大模型上下文扩展微调方法,其特征在于:所述参考文档为悟道开源中文语料或commoncrawl数据集。
3.根据权利要求1所述的基于原文复述机制的食品安全大模型上下文扩展微调方法,其特征在于:所述指令微调数据的数据长度大于8k且小于32k,并包括gpt-3.5设计问题与gpt-3.5设计回答。
4.根据权利要求1所述的基于原文复述机制的食品安全大模型上下文扩展微调方法,其特征在于:所述语言模型为qwen-14b-chat模型。
5.根据权利要求4所述的基于原文复述机制的食品安全大模型上下文扩展微调方法,其特征在于:所述qwen-14b-chat模型采用将位置编码方法替换为dynamic-yarn。
6.根据权利要求1所述的基于原文复述机制的食品安全大模型上下文扩展微调方法,其特征在于:所述训练微调采用qlora训练,并将回答纳入loss计算,微调qwen的所有linear层。
7.根据权利要求1所述的基于原文复述机制的食品安全大模型上下文扩展微调方法,其特征在于:在所述训练微调中,采用将指令微调数据的回答部分加入回答问题所需的相关原文。
8.根据权利要求7所述的基于原文复述机制的食品安全大模型上下文扩展微调方法,其特征在于:所述相关原文为与回答弱相关或强相关的上下文。
技术总结
本申请公开了一种基于原文复述机制的食品安全大模型上下文扩展微调方法,涉及计算机技术领域,该方法包括设立参考文档,以多个参考文档形成组,取第一个参考文档设计问答对,在问答对的回答中给出相关原文;将组内参考文档顺序打乱,并形成参考文档列表以及指令微调数据;设立语言模型,将指令微调数据导入语言模型,训练微调以获得长文本语言模型。本申请具有解决现有语言模型在面对长文本时存在的问答准确率低、忽略上下文中间部分信息的问题的效果,有效提高长文本的问答准确率,且通过避免人工标注导致的成本显著增加的问题。
技术研发人员:俞一炅,齐致潇,张秀宇,王菲,李文雅
受保护的技术使用者:北京信睿浩扬科技有限公司
技术研发日:
技术公布日:2024/8/16
- 还没有人留言评论。精彩留言会获得点赞!