一种大型矩阵多片GPU并行加速运算方法
本发明涉及数据处理领域,尤其是一种大型矩阵多片gpu并行加速运算方法。
背景技术:
1、大型矩阵运算是科学研究、工程领域和商业应用中的重要组成部分,为处理大规模数据和复杂问题提供了有效的数学基础。例如在重力场反演中,大型线性方程组的解算是重要步骤之一,目前,行星重力场模型经历了一个从低阶次到高阶次,从低分辨率到高分辨率的发展过程,对于高阶次行星重力场模型解算的需求日益增多,因此,为了提高重力场反演计算效率,缩短大规模矩阵求逆计算所需的时间很有必要。
2、目前,研究者大多采用基于mpi和openmp的方法进行大型矩阵的加速运算,但仍存在改进的空间。得益于gpu多核心、高集成的特点,密集运算能够实现高度并行化,单片gpu乃至多片gpu并行的计算速度可以使矩阵运算速度提升进一步提高。本发明运用了多片gpu并行运算的方法,实现了矩阵乘法和矩阵求逆运算的高度并行化,运算速度较cpu有了极大的提升,且运算精度较高,适用于高阶次重力场反演中的矩阵运算。
技术实现思路
1、发明目的在于:提供一种大型矩阵多片gpu并行加速运算方法,能够有效加速大型线性方程的求解。
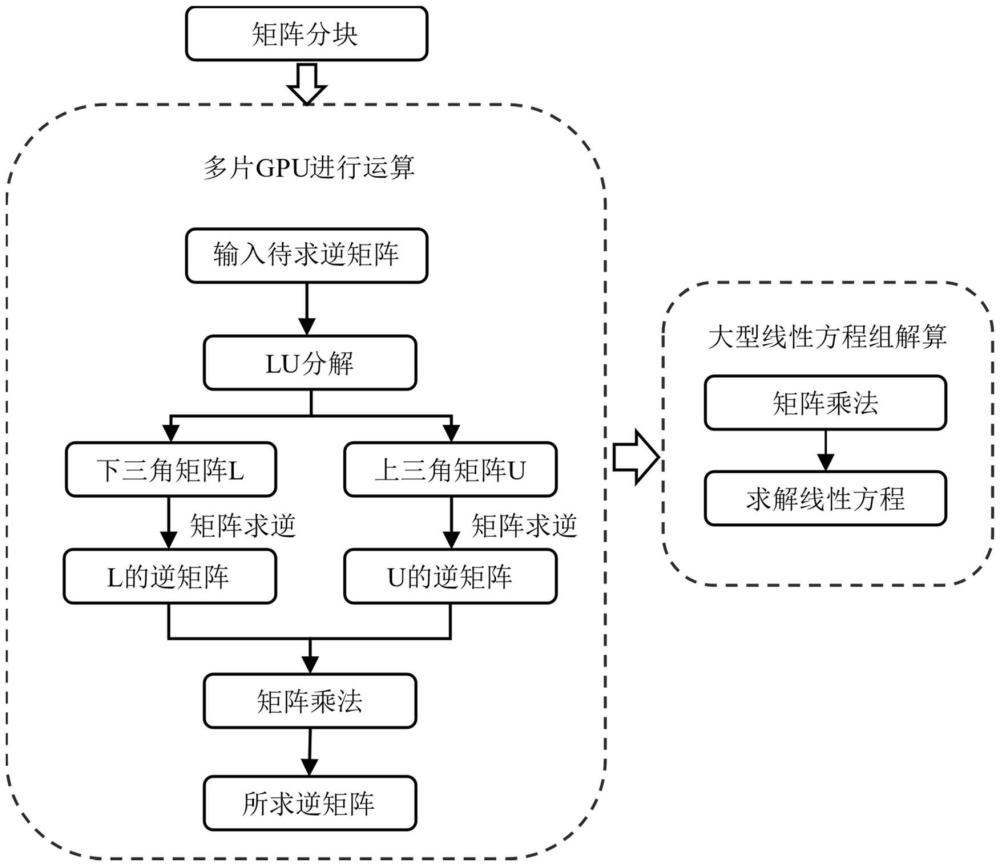
2、技术方案:本发明所述的大型矩阵多片gpu并行加速运算方法,包括如下步骤:
3、步骤1,对cpu上的待运算大型矩阵进行分块获得各个分块矩阵;
4、步骤2,对各个分块矩阵均进行lu分解,利用多片gpu并行的方式对lu分解过程中的矩阵乘法进行加速运算,获得下三角矩阵l和上三角矩阵u;
5、步骤3,对获得的下三角矩阵l和上三角矩阵u进行矩阵求逆运算,得到下三角矩阵l的逆矩阵以及上三角矩阵u的逆矩阵;
6、步骤4,将下三角矩阵l的逆矩阵以及上三角矩阵u的逆矩阵进行合并,获得对应分块矩阵的逆矩阵;
7、步骤5,利用分块矩阵的逆矩阵采用矩阵加速运算方法对大型线性方程组进行求解。
8、进一步的,步骤2中,利用多片gpu并行的方式对lu分解过程中的矩阵乘法进行加速运算的具体步骤为:
9、步骤2.1,选定用于加速运算的各片gpu,并在各片gpu上均分配一个数据空间,采用一维列块循环分布方式将cpu上的各个分块矩阵分别复制到各片gpu的数据空间上;
10、步骤2.2,将gpu上的分块矩阵进行分块获得各个矩阵块,分配矩阵块的矩阵列到各片gpu,并使各片gpu上处理的列数均匀分配且符合内存对齐的要求;
11、步骤2.3,每个gpu对其分配到的矩阵块利用gauss消去法进行局部lu分解,获得局部的下三角矩阵l以及上三角矩阵u;
12、步骤2.4,更新gpu上的矩阵块,合并各gpu上的局部矩阵结果得到整体的下三角矩阵l和上三角矩阵u。
13、进一步的,步骤2中,多片gpu并行的方式是通过为每片gpu创建一个用于控制运算时序的计算队列,各个计算队列用于对gpu中的各个运算按照运算时序进行同步控制,确保所有gpu都按照计算队列同步完成各个计算任务。
14、进一步的,步骤2.3中,利用gauss消去法进行局部lu分解的具体步骤为:
15、对矩阵块利用dtrsm函数求解获得下三角矩阵y;
16、再对下三角矩阵y进行行变换求解局部的下三角矩阵l;
17、再采用矩阵加速运算方法将dtrsm函数所得的下三角矩阵y与矩阵块相乘获得局部的上三角矩阵u。
18、进一步的,步骤3中,对获得的下三角矩阵l和上三角矩阵u进行矩阵求逆运算的具体步骤为:
19、步骤3.1,对于下三角矩阵l,在每片gpu上均采用lapack库中的dtrtri函数对下三角矩阵l进行求逆,得到下三角矩阵l的逆矩阵;
20、步骤3.2,对于上三角矩阵u,在每片gpu上采用lapack库中的dtrtri函数对上三角矩阵u进行求逆,得到上三角矩阵u的逆矩阵。
21、进一步的,步骤4中,将下三角矩阵l的逆矩阵以及上三角矩阵u的逆矩阵进行合并时,采用矩阵加速运算方法将下三角矩阵l的逆矩阵以及上三角矩阵u的逆矩阵进行相乘,得到原矩阵的逆矩阵。
22、进一步的,矩阵加速运算方法采用循环平铺技术、循环展开技术以及多个线程块来计算矩阵乘法,并重复线程块的运算直至获得矩阵乘积结果。
23、本发明与现有技术相比,其有益效果是:(1)运用多片gpu并行运算的方法,大幅提高了大型矩阵乘法和求逆运算的速度,与采用cpu的运算方法相比,显著地缩短了运算时间;(2)本发明的多片gpu并行加速运算方法适用于高阶次重力场反演运算,且具有可靠性和准确性,在实际行星重力场反演中有很大应用价值。
技术特征:
1.一种大型矩阵多片gpu并行加速运算方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的大型矩阵多片gpu并行加速运算方法,其特征在于,步骤2中,利用多片gpu并行的方式对lu分解过程中的矩阵乘法进行加速运算的具体步骤为:
3.根据权利要求1所述的大型矩阵多片gpu并行加速运算方法,其特征在于,步骤2中,多片gpu并行的方式是通过为每片gpu创建一个用于控制运算时序的计算队列,各个计算队列用于对gpu中的各个运算按照运算时序进行同步控制,确保所有gpu都按照计算队列同步完成各个计算任务。
4.根据权利要求1所述的大型矩阵多片gpu并行加速运算方法,其特征在于,步骤2.3中,利用gauss消去法进行局部lu分解的具体步骤为:
5.根据权利要求1所述的大型矩阵多片gpu并行加速运算方法,其特征在于,步骤3中,对获得的下三角矩阵l和上三角矩阵u进行矩阵求逆运算的具体步骤为:
6.根据权利要求1所述的大型矩阵多片gpu并行加速运算方法,其特征在于,步骤4中,将下三角矩阵l的逆矩阵以及上三角矩阵u的逆矩阵进行合并时,采用矩阵加速运算方法将下三角矩阵l的逆矩阵以及上三角矩阵u的逆矩阵进行相乘,得到原矩阵的逆矩阵。
7.根据权利要求1或4所述的大型矩阵多片gpu并行加速运算方法,其特征在于,矩阵加速运算方法采用循环平铺技术、循环展开技术以及多个线程块来计算矩阵乘法,并重复线程块的运算直至获得矩阵乘积结果。
技术总结
本发明公开了一种大型矩阵多片GPU并行加速运算方法,步骤包括:对运算矩阵进行分块获得各个分块矩阵;对各个分块矩阵均进行LU分解获得下三角矩阵L和上三角矩阵U;对获得的下三角矩阵L和上三角矩阵U进行矩阵求逆运算;将下三角矩阵L的逆矩阵以及上三角矩阵U的逆矩阵进行合并获得分块矩阵的逆矩阵;利用分块矩阵的逆矩阵采用矩阵加速运算方法对大型线性方程组进行求解。该大型矩阵多片GPU并行加速运算方法对大型矩阵的乘法和求逆运算进行加速,实现了大型线性方程组的快速求解,提高了运算效率。
技术研发人员:陈从颜,周予涵,简念川
受保护的技术使用者:东南大学
技术研发日:
技术公布日:2024/8/27
- 还没有人留言评论。精彩留言会获得点赞!