一种面向领域增量任务的大语言模型持续学习方法
本发明涉及自然语言处理中的领域增量任务,具体来说,涉及一种面向领域增量任务的大语言模型持续学习方法。
背景技术:
1、持续学习(continual learning)致力于获取新知识,同时解决普遍存在的灾难性遗忘问题,是自然语言处理中广泛探讨的一个主题。随着模型规模和训练数据的不断增长,从头开始重新训练模型通常非常昂贵且耗时,如何确保模型在学习新任务的过程中维持在旧任务上性能变得尤为重要。领域增量任务是其中一种持续学习任务类型,模型需要学习一系列领域数据集,同一时刻只能访问当前领域的数据集,在测试阶段无法访问测试数据的领域来源。
2、当前研究可大致分为三种方法:基于录制回放的方法、基于正则化的方法和基于架构的方法:基于录制回放的方法通过保留历史信息或利用伪数据生成器来进行回放录制,从而在持续学习过程中维持对先前任务的记忆;基于正则化的方法通过在损失函数中融入额外项来加固模型对旧任务的记忆,这通常通过知识蒸馏或计算参数重要性等技术来实现;基于架构的方法为每个任务分配独立的参数集,并将它们与冻结的基础模型动态集成,以此实现任务间的有效知识隔离与整合。
3、然而,这些研究主要集中在缓解基于预训练的语言模型(例如bert)的灾难性遗忘问题,这些模型的参数远小于大语言模型。同时,这些方法也存在着以下问题:1)领域增量任务往往需要使用丰富的领域不变知识来推断,现有方法往往容易忽视不同领域之间的共性;2)不同领域之间的领域特定知识不一致,现有方法大多只考虑不同领域特定知识之间的约束,缺少对不同领域特定知识与领域不变知识之间的约束。而实际上,可以通过对领域特定知识和领域不变知识进行解耦建模,在这个基础上进行的大语言模型持续学习将更具针对性。
技术实现思路
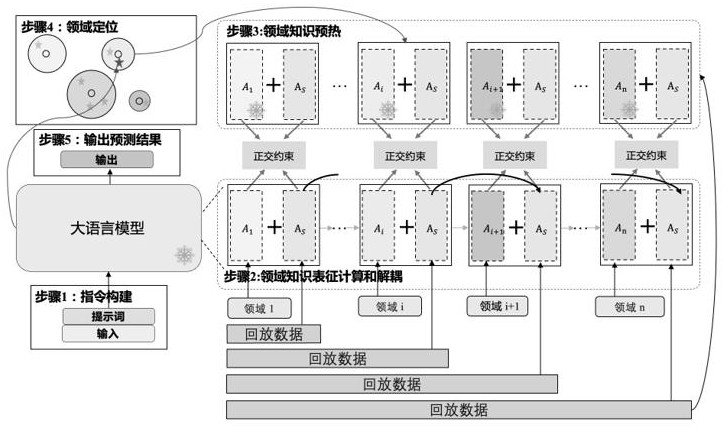
1、本发明的目的是针对大语言模型在领域增量任务的持续学习过程中存在的灾难性遗忘问题,提供了一种面向领域增量任务的大语言模型持续学习方法,领域知识表征计算和解耦通过正交约束分离领域不变适配器和领域特定适配器,并学习到对应的知识。领域知识预热对齐领域不变适配器和领域特定适配器之间的参数分布。领域定位通过计算测试样本与不同领域训练数据表征的相似性,来查找对应的领域知识特定适配器,与领域不变适配器拼接,从而给出最终预测结果。
2、实现本发明目的具体技术方案是:
3、一种面向领域增量任务的大语言模型持续学习方法,该方法包括以下具体步骤:
4、步骤1:指令构建
5、设计任务提示词prompt,在prompt中给出任务定义和输出格式;将prompt与输入句子xi,j进行拼接,与输出yi,j一起得到统一格式的指令其中xi,j和yi,j表示第i个领域数据集中的第j条输入句子和输出,表示将prompt和xi,j进行拼接;
6、步骤2:领域知识表征计算和解耦,具体包括:
7、(1)领域表征分布计算
8、对于第i个领域数据集di,将送入大语言模型llm得到最后一个transformer块的隐层输出计算每一个领域中的平均值μi和方差∑i来表示领域表征分布,计算公式如下式(1)-(2):
9、
10、
11、(2)领域知识解耦
12、对于第i个领域,训练数据包括领域数据集di和对应的回放数据集其中表示从第k个领域的数据集中随机抽取m个数据,作为回放数据集;r表示录制回放数据;冻结大语言模型llm的参数φ,并拼接上领域特定适配器ai和领域不变适配器as,对于每一个领域都有独立的ai和共享的as;在训练过程中,只用回放数据集dr,i,m更新as的参数,用领域数据集di更新ai的参数,损失函数计算公式如下式(3)-(4):
13、
14、
15、其中lml表示语言建模损失函数,大语言模型llm拼接领域特定适配器ai和领域不变适配器as得到表示语言模型的训练目标,计算公式如下式(5):
16、
17、对于领域特定适配器ai和领域不变适配器as,使用正交约束进行限制,损失函数计算公式如下式(6):
18、
19、最终的训练损失函数公式如下式(7),其中λ表示超参数:
20、
21、步骤3:领域知识预热
22、通过步骤2中领域知识解耦可以得到领域特定适配器集领域不变适配器as,以及第n个领域的回放数据dr,n,m,其中n=|d|,表示领域的数量;拼接每个领域特定适配器ai和领域不变适配器as,固定领域特定适配器ai的参数,使用回放数据dr,n,m进行训练,得到每个领域的领域特定适配器和领域不变适配器损失函数计算公式如下式(8):
23、
24、步骤4:领域定位
25、在测试阶段,对于测试样本x,将通过拼接prompt后的x*送入大语言模型llm得到最后一个transformer块的隐层输出h(x*),选择与h(x*)马氏距离最小的领域inearest,计算公式如下式(9):
26、
27、其中表示使(·)取最小值的i;
28、步骤5:输出预测结果
29、拼接和得到将x*输入得到预测输出y={yi},计算公式如下式(10):
30、
31、其中w表示词表,当yi的结果为此表中的结束符或达到约定的最大长度时,停止输出。
32、本发明的有益效果在于:
33、本发明具有可解释性,通过正交约束分离领域不变知识和领域变化知识,使用领域知识预热策略对齐领域不变适配器和领域特定适配器之间的参数分布,从而能够更好地理解不同领域知识的共性与差异性,使预测结果更为合理。在由hl5domains、liu3domains、ding9domains、semeval14数据集组成的具有19个领域的方面级情感词极性判断数据集上进行实验,实验结果表明,本发明与现有技术相比,平均性能更高,能有效缓解灾难性遗忘问题。
技术特征:
1.一种面向领域增量任务的大语言模型持续学习方法,其特征在于,该方法包括以下具体步骤:
技术总结
本发明公开了一种面向领域增量任务的大语言模型持续学习方法,该方法包括:领域知识表征计算和解耦、领域知识预热及领域定位。领域知识表征计算和解耦通过正交约束分离领域不变适配器和领域特定适配器,并学习到对应的知识。领域知识预热对齐领域不变适配器和领域特定适配器之间的参数分布。领域定位通过计算测试样本与不同领域训练数据表征的相似性,来查找对应的领域知识特定适配器,与领域不变适配器拼接,从而给出最终预测结果。在由HL5Domains、Liu3Domains、Ding9Domains、SemEval14数据集组成的具有19个领域的方面级情感词极性判断数据集上进行实验,实验结果表明,本发明与现有技术相比,平均性能更高,能有效缓解灾难性遗忘问题。
技术研发人员:丁炫文,周杰,窦亮,陈琴
受保护的技术使用者:华东师范大学
技术研发日:
技术公布日:2024/8/13
- 还没有人留言评论。精彩留言会获得点赞!