基于大模型的多任务数据筛选方法、装置、设备及介质与流程
本发明涉及数据处理,具体涉及基于大模型的多任务数据筛选方法、装置、设备及介质。
背景技术:
1、随着大模型技术的快速发展,大模型在对话系统中的多种任务上都有着非常好的表现,如意图识别、无效对话识别、情感识别、多轮对话改写等。当大模型应用于多任务时,由于不同任务数据获取难度和获取成本的差异,导致不同任务的可用数据质量、数量非常不平衡,影响大模型在不同任务上的均衡表现,尤其在数据迭代过程中这个问题会越来越严重。
技术实现思路
1、有鉴于此,本发明提供了一种基于大模型的多任务数据筛选方法、装置、设备及介质,以解决大模型不同任务的可用数据不平衡,影响大模型在不同任务上的均衡表现的问题。
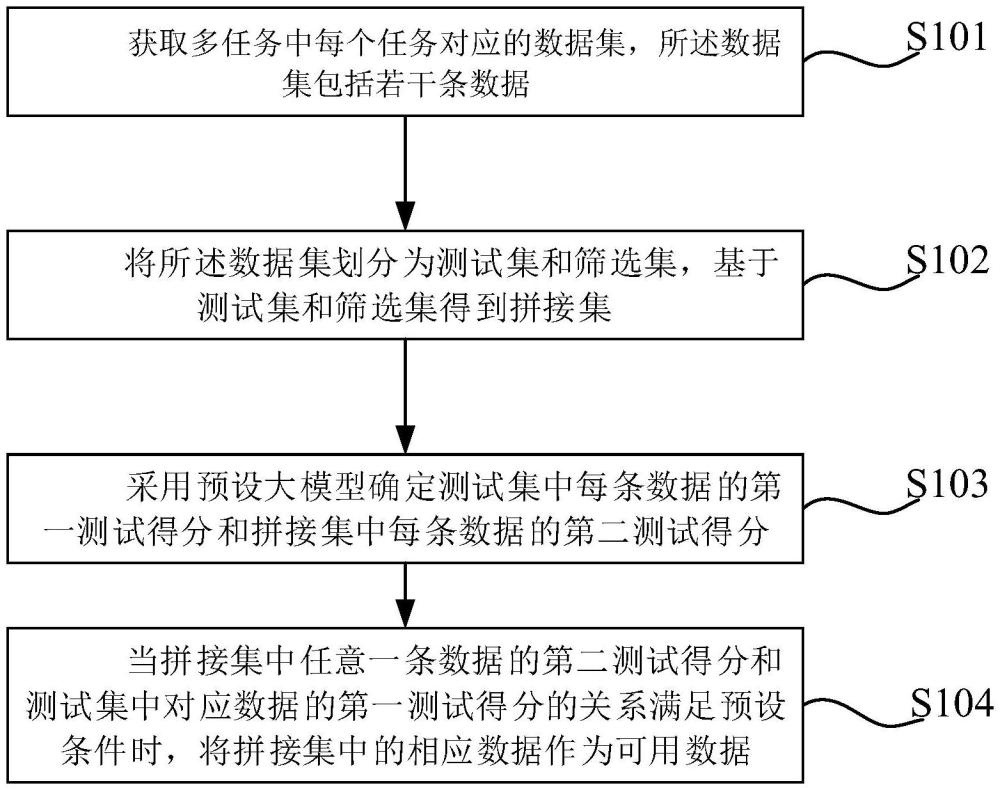
2、第一方面,本发明提供了一种基于大模型的多任务数据筛选方法,获取多任务中每个任务对应的数据集,数据集包括若干条数据;将数据集划分为测试集和筛选集,基于测试集和筛选集得到拼接集;采用预设大模型确定测试集中每条数据的第一测试得分和拼接集中每条数据的第二测试得分;当拼接集中任意一条数据的第二测试得分和测试集中对应数据的第一测试得分的关系满足预设条件时,将拼接集中的相应数据作为可用数据。
3、本实施例提供的基于大模型的多任务数据筛选方法,通过构建测试集、筛选集、拼接集,并计算拼接集数据的第二测试得分和筛选集对应的测试集的数据的第一测试得分,通过比较第二测试得分和第一测试得分,筛选出优良的训练数据,过滤垃圾数据,解决了不同任务的数据有的多有的少,数量差异过大,数据不平衡严重影响数量少的任务的表现的问题。
4、在一种可选的实施方式中,若干条数据包括若干条对话数据,每条对话数据包括提问词和答案,提问词和答案均包括若干词料,采用预设大模型确定测试集中每条数据的第一测试得分,包括:将测试集的每条对话数据输入预设大模型,得到每条对话数据的答案包括的每个词料的输出向量;将答案包括的每个词料的输出向量的负对数概率进行求和并除以答案包括的词料的个数,得到该条对话数据的第一测试得分。
5、本实施例提供的基于大模型的多任务数据筛选方法,计算测试集的对话数据的第一测试得分,为后续判断可用数据提供数据基础。
6、在一种可选的实施方式中,采用如下公式计算每个词料的输出向量的负对数概率:
7、logp_t=-log(softmax(logits_t));
8、其中,logits_t为第t个词料的输出向量,logp_t为第t个词料的负对数概率,softmax为softmax函数,用于计算输出向量的概率。
9、本实施例提供的基于大模型的多任务数据筛选方法,通过计算输出向量的负对数概率,为计算第一测试得分和第二测试得分提供方法算式。
10、在一种可选的实施方式中,若干条数据包括若干条对话数据,基于测试集和筛选集得到拼接集,包括:将测试集的任意一条对话数据与筛选集任意一条对话数据一对一拼接得到拼接对话数据,拼接对话数据包括拼接提问词和答案,拼接提问词包括筛选集中任意一条对话数据和测试集的对话数据的提问词,拼接对话数据的答案为测试集的对话数据的答案;根据拼接对话数据确定拼接集。
11、本实施例提供的基于大模型的多任务数据筛选方法,通过将测试集数据与筛选集作拼接得到拼接集,为后续筛选可用数据提供数据基础。
12、在一种可选的实施方式中,采用预设大模型确定拼接集中每条数据的第二测试得分,包括:将拼接集的任意一条拼接对话数据输入预设大模型,得到拼接对话数据的答案包括的每个词料的输出向量;将答案包括的每个词料的输出向量的负对数概率进行求和并除以答案包括的词料的个数,得到该条拼接对话数据的第二测试得分。
13、本实施例提供的基于大模型的多任务数据筛选方法,计算测试集对话数据的第一测试得分和测试集对话数据对应的拼接集的拼接对话数据的第二测试得分,通过比较第一测试得分和第二测试得分,判断拼接对话数据对应的筛选集数据是否可作为可用数据,提供了判断数据是否为优良训练数据的判断方法,提高了筛选可用数据效率和准确率。
14、在一种可选的实施方式中,将拼接集中的相应数据作为可用数据包括:将拼接集中相应拼接对话数据对应筛选集中的相应对话数据作为可用数据;当拼接集中任意一条数据的第二测试得分和测试集中对应数据的第一测试得分的关系满足预设条件时,将拼接集中的相应数据作为可用数据之后,方法还包括:循环判断拼接集的拼接对话数据是否可以作为可用数据的过程,直到拼接集的每条拼接对话数据均被判断完成,则筛选结束;重复筛选每个任务的拼接集的过程,分别得到每个任务的可用数据。
15、本实施例提供的基于大模型的多任务数据筛选方法,提高了筛选可用数据的效率,减少不同任务数据获取难度和获取成本的差异,平衡不同任务的可用数据,使得大模型在不同任务上均衡表现。
16、第二方面,本发明提供了一种数据筛选装置,装置包括:
17、数据处理模块,用于获取多任务中每个任务对应的数据集,数据集包括若干条数据;将数据集划分为测试集和筛选集,基于测试集和筛选集得到拼接集;
18、计算得分模块,采用预设大模型确定测试集中每条数据的第一测试得分和拼接集中每条数据的第二测试得分;
19、判断模块,用于当拼接集中任意一条数据的第二测试得分和测试集中对应数据的第一测试得分的关系满足预设条件时,将拼接集中的相应数据作为可用数据。
20、第三方面,本发明提供了一种计算机设备,包括:存储器和处理器,存储器和处理器之间互相通信连接,存储器中存储有计算机指令,处理器通过执行计算机指令,从而执行上述第一方面或其对应的任一实施方式的基于大模型的多任务数据筛选方法。
21、第四方面,本发明提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机指令,计算机指令用于使计算机执行上述第一方面或其对应的任一实施方式的基于大模型的多任务数据筛选方法。
22、第五方面,本发明提供了一种计算机程序产品,包括计算机指令,计算机指令用于使计算机执行上述第一方面或其对应的任一实施方式的基于大模型的多任务数据筛选方法。
技术特征:
1.一种基于大模型的多任务数据筛选方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述若干条数据包括若干条对话数据,每条对话数据包括提问词和答案,所述提问词和答案均包括若干词料,采用预设大模型确定测试集中每条数据的第一测试得分,包括:
3.根据权利要求2所述的方法,其特征在于,采用如下公式计算每个词料的输出向量的负对数概率:
4.根据权利要求1所述的方法,其特征在于,所述若干条数据包括若干条对话数据,基于测试集和筛选集得到拼接集,包括:
5.根据权利要求4所述的方法,其特征在于,采用预设大模型确定拼接集中每条数据的第二测试得分,包括:
6.根据权利要求4所述的方法,其特征在于,将拼接集中的相应数据作为可用数据包括:
7.一种数据筛选装置,其特征在于,所述装置包括:
8.一种计算机设备,其特征在于,包括:
9.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机指令,所述计算机指令用于使计算机执行权利要求1至6中任一项所述的基于大模型的多任务数据筛选方法。
10.一种计算机程序产品,其特征在于,包括计算机指令,所述计算机指令用于使计算机执行权利要求1至6中任一项所述的基于大模型的多任务数据筛选方法。
技术总结
本发明涉及数据处理技术领域,公开了一种基于大模型的多任务数据筛选方法、装置、设备及介质,获取多任务中每个任务对应的数据集,所述数据集包括若干条数据;将所述数据集划分为测试集和筛选集,基于测试集和筛选集得到拼接集;采用预设大模型确定测试集中每条数据的第一测试得分和拼接集中每条数据的第二测试得分;当拼接集中任意一条数据的第二测试得分和测试集中对应数据的第一测试得分的关系满足预设条件时,将拼接集中的相应数据作为可用数据。本方法通过对不同任务数据的过滤筛选,对不同任务的数据之间进行平衡,能够大幅降低训练所需的数据量,节省训练大模型的成本。
技术研发人员:李蒙
受保护的技术使用者:镁佳(北京)科技有限公司
技术研发日:
技术公布日:2024/9/19
- 还没有人留言评论。精彩留言会获得点赞!