一种基于语义引导图像融合的自适应目标检测方法
本发明涉及图像检测,尤其涉及一种基于语义引导图像融合的自适应目标检测方法。
背景技术:
1、在信息爆炸的时代,传感器技术迅速发展导致传感器种类不断增加,从而捕获的信息也呈现多元化趋势。不同类型的传感器由于其成像原理的差异,导致捕捉到的图像存在显著差异,因此,单一传感器光电成像系统所获取的图像往往无法全面准确地描述整个场景,对所获取图像进行目标检测的结果准确率也受到影响。为了解决单一传感器成像系统存在的时间、空间和光谱信息不完整的问题,图像融合技术应运而生。图像融合技术旨在将来自同一场景但不同模态、不同位置或不同时间的多幅图像信息整合在一起,生成一幅信息丰富、可靠性高、针对性强的融合图像。通过图像融合技术,可以综合利用多个传感器的特点,弥补各自的局限性,以提供更全面、准确的图像信息,进而提高目标检测准确率。
2、目前,多模态融合的现有算法主要分为两类:传统的图像融合方法和基于深度学习的图像融合方法。传统的融合方法通过在不同的特征域测量图像的活动水平以获得源图像的分解特征系数,之后对这些特征系数执行特定的融合规则以生成融合图像;基于深度学习的红外与可见光图像融合方法主要分类四类:基于卷积神经网络(convolutionalneural network,cnn)的方法、基于自编码器(auto-encoder,ae)的方法、基于生成对抗网络(generative adversarial networks,gan)的方法和基于transformer的方法。然而,图像融合过程中主要约束于生成结果与源图像之间的关系,缺乏对图像中目标与背景的定义,对于下游任务而言,如目标检测任务,在准确度上具有一定影响。
技术实现思路
1、为了解决上述技术问题,本发明提出一种基于语义引导图像融合的自适应目标检测方法,在所述方法中,通过目标检测任务为图像融合网络提供目标的语义信息,构建了一个目标检测特征嵌入的红外与可见光图像融合框架。然而,在目标检测特征中除了包含目标的语义信息外,还可能包含一些与目标检测任务相关的信息,这些信息可能对图像融合任务产生积极作用。为了解决这一问题,还设计了共享模块,提取检测过程中的语义特征,通过调整融合特征的目标权重来突出目标信息。通过获得具有目标的语义信息的融合图像来进行目标检测,能够有效提高目标检测准确率。
2、为了达到上述目的,本发明的技术方案如下:
3、一种基于语义引导图像融合的自适应目标检测方法,包括如下步骤:
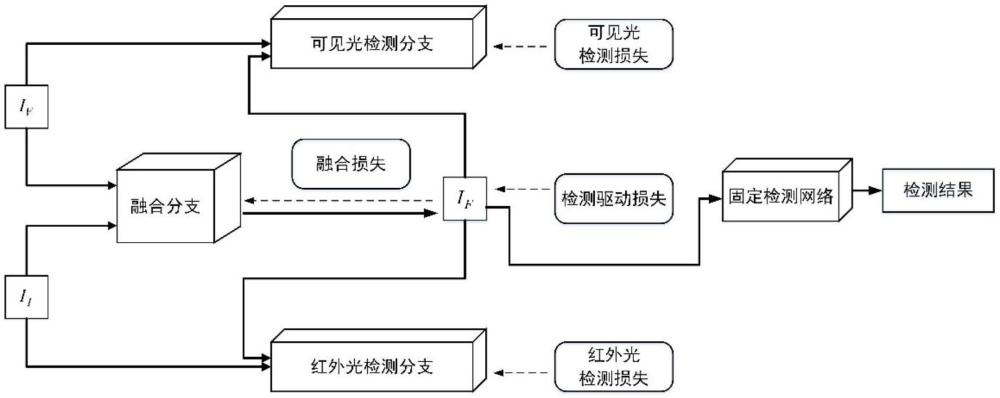
4、将行人可见光图像iv输入可见光检测分支,得到可见光检测特征fv和可见光检测损失lvdet,并根据可见光检测损失lvdet对可见光检测分支进行优化,获得优化后的可见光检测分支;行人红外图像ii输入红外光检测分支,得到红外光检测特征fi和红外光检测损失lidet,并根据红外光检测损失lidet对红外光检测分支进行优化,获得优化后的红外光检测分支;
5、将行人可见光图像iv和行人红外光图像ii输入融合分支,得到融合后图像if和融合损失lfusion;将融合后图像if分别输入可见光检测分支和红外光检测分支得到检测驱动损失ldet,并根据融合损失和检测驱动损失对融合分支进行优化,获得优化后的融合分支;
6、将待检测行人可见光图像和待检测行人可见光图像分别对应输入优化后的红外光检测分支和优化后的红外光检测分支中,获得检测结果;将检测结果输入优化后的融合分支获得融合后图像;将融合后图像输入固定检测网络中进行识别,获得目标位置和目标类别。
7、优选地,所述可见光检测分支和红外光检测分支的结构相同但参数不共享。
8、优选地,所述可见光检测分支的主干网络采用resnet-fpn、检测头采用fasterr-cnn;所述红外光检测分支的主干网络采用resnet-fpn、检测头采用fasterr-cnn。
9、优选地,所述融合分支包括两个编码器、一个共享模块和一个解码器,其中,行人可见光图像iv和行人红外光图像ii分别输入两个编码器,获得检测特征fv和fi,并将检测特征fv和fi进行元素相加,获得融合特征ff;
10、将特征fv、fi和ff一同输入共享模块,得到加权后的融合特征f′f;通过解码器对加权后的融合特征进行解码,获得融合后图像if。
11、优选地,所述检测驱动损失ldet,定义如下:
12、ldet=lvdet+lidet
13、其中,可见光检测损失lvdet和红外光检测损失lidet均包含分类损失和回归损失,
14、以可见光检测分支为例,可见光检测损失lvdet包含分类损失和回归损失如下,
15、
16、其中p表示每个类别的预测概率,tu表示预测边界框结果,u表示真实类别,v表示真实边界框回归目标,为交叉熵损失函数伊佛森括号指示函数[u≥1]在u≥1时取值为1,否则为0,所有的背景类被标记为u=0,为smooth l1损失函数。
17、优选地,所述固定检测网络采用yolov8网络。
18、基于上述技术方案,本发明的有益效果是:本发明一种基于语义引导图像融合的自适应目标检测方法,将行人可见光图像iv输入可见光检测分支,得到可见光检测特征fv和可见光检测损失lvdet,并根据可见光检测损失lvdet对可见光检测分支进行优化,获得优化后的可见光检测分支;行人红外图像ii输入红外光检测分支,得到红外光检测特征fi和红外光检测损失lidet,并根据红外光检测损失lidet对红外光检测分支进行优化,获得优化后的红外光检测分支;将行人可见光图像iv和行人红外光图像ii输入融合分支,得到融合后图像if和融合损失lfusion;将融合后图像if分别输入可见光检测分支和红外光检测分支得到检测驱动损失ldet,并根据融合损失和检测驱动损失对融合分支进行优化,获得优化后的融合分支;将待检测行人可见光图像和待检测行人可见光图像分别对应输入优化后的红外光检测分支和优化后的红外光检测分支中,获得检测结果;将检测结果输入优化后的融合分支获得融合后图像;将融合后图像输入固定检测网络中进行识别,获得目标位置和目标类别。本发明通过目标检测任务为图像融合网络提供目标的语义信息,构建了一个目标检测特征嵌入的红外与可见光图像融合框架。然而,在目标检测特征中除了包含目标的语义信息外,还可能包含一些与目标检测任务相关的信息,这些信息可能对图像融合任务产生积极作用。为了解决这一问题,还设计了共享模块,提取检测过程中的语义特征,通过调整融合特征的目标权重来突出目标信息。通过获得具有目标的语义信息的融合图像来进行目标检测,能够有效提高目标检测准确率。
技术特征:
1.一种基于语义引导图像融合的自适应目标检测方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的一种基于语义引导图像融合的自适应目标检测方法,其特征在于,所述可见光检测分支和红外光检测分支的结构相同但参数不共享。
3.根据权利要求2所述的一种基于语义引导图像融合的自适应目标检测方法,其特征在于,所述可见光检测分支的主干网络采用resnet-fpn、检测头采用fasterr-cnn;所述红外光检测分支的主干网络采用resnet-fpn、检测头采用fasterr-cnn。
4.根据权利要求1所述的一种基于语义引导图像融合的自适应目标检测方法,其特征在于,所述融合分支包括两个编码器、一个共享模块和一个解码器,其中,行人可见光图像iv和行人红外光图像ii分别输入两个编码器,获得检测特征fv和fi,并将检测特征fv和fi进行元素相加,获得融合特征ff;将特征fv、fi和ff一同输入共享模块,得到加权后的融合特征f′f;通过解码器对加权后的融合特征进行解码,获得融合后图像if。
5.根据权利要求4所述的一种基于语义引导图像融合的自适应目标检测方法,其特征在于,所述检测驱动损失ldet,定义如下:
6.根据权利要求1所述的一种基于语义引导图像融合的自适应目标检测方法,其特征在于,所述固定检测网络采用yolov8网络。
技术总结
本发明公开一种基于语义引导图像融合的自适应目标检测方法,行人可见光图像I<subgt;V</subgt;输入可见光检测分支得到可见光检测损失,并优化可见光检测分支;行人红外图像I<subgt;I</subgt;输入红外光检测分支得到红外光检测损失,并优红外光检测分支;行人可见光图像I<subgt;V</subgt;和行人红外光图像I<subgt;I</subgt;输入融合分支后得到融合后图像I<subgt;F</subgt;和融合损失,融合后图像分别输入可见光检测分支和红外光检测分支得到检测驱动损失,上述训练过程中得到的融合损失和检测驱动损失共同优化融合分支;融合图像输入固定检测网络得到检测结果:基于语义特征引导的图像融合训练网络推理得到的融合后图像输入一个固定检测网络后得到最终的检测结果。本发明能够有效提高目标检测准确率。
技术研发人员:刘慧舟,杜星泽,谌博文,黄忠,黄梦醒
受保护的技术使用者:海南大学
技术研发日:
技术公布日:2024/7/29
- 还没有人留言评论。精彩留言会获得点赞!