一种纠删码数据恢复方法、装置及存储介质与流程
本发明涉及数据存储,尤其是指一种纠删码数据恢复方法、装置、设备及计算机存储介质。
背景技术:
1、纠删码(ec)是分布式存储项目ceph的数据安全保障策略之一,相同的安全等级下,ec相比副本策略具有更高的有效容量,即在存储服务器成本不变的情况下,ec策略可存储更多数据。
2、当发生存储数据损坏,ec策略会通过计算完成数据修复,例如集群进行定期扫描和深度扫描过程中发现静默数据校验错误,或在读取数据过程中发现数据损坏等情况,均会触发ec策略数据恢复动作。但ec策略进行数据恢复的计算开销高于副本策略,且其数据恢复的速度与节点的cpu利用率、内存利用率、网络剩余带宽等因素有关。
3、目前,ceph开源社区针对ec策略数据恢复的情境,并没有提供特定的方案去选择计算节点。而是基于ceph peering的机制,即将待恢复数据对应的主osd节点作为数据恢复的计算节点;当数据损坏发生在主osd上时,按顺序选取下一个osd作为临时主osd,并确认临时主osd对应的节点为计算节点(注:计算节点选择策略的集群背景均为主机级别故障域)。
4、通过对传统技术描述可知,ec数据恢复过程依赖于计算节点的计算速度,而计算节点的cpu、内存和网络等资源会一定程度影响数据恢复计算过程,进而影响数据恢复速度,而传统方案中,计算节点按顺序选择,无法保证所选计算节点为所涉及的所有节点中的最优节点,即host1或host2在触发数据恢复计算时,不一定为最优的数据恢复计算节点,因此该方法会影响ec数据恢复效率,在集群处理业务情况下,传统方案对集群业务和读写速率的影响将更为明显。
5、综上所述,在ec存储策略下,ceph针对集群数据恢复的方案存在以下几点不足:
6、·ceph开源方案中计算节点默认为待恢复数据的主osd节点,没有考虑该节点的资源状态,无法保证顺序选择的计算节点为最优的计算节点,进而会影响数据恢复计算的效率,增加恢复开销,延长数据恢复时间;
7、·节点配置伴随硬件老化、故障等问题会发生变化,导致原始提供学习的数据集无法满足现有场景,预测模型会产生较大误差,进而影响数据恢复速度。
技术实现思路
1、为此,本发明所要解决的技术问题在于克服现有技术中数据恢复效率低、速度低的问题。
2、为解决上述技术问题,本发明提供了一种纠删码数据恢复方法,包括:
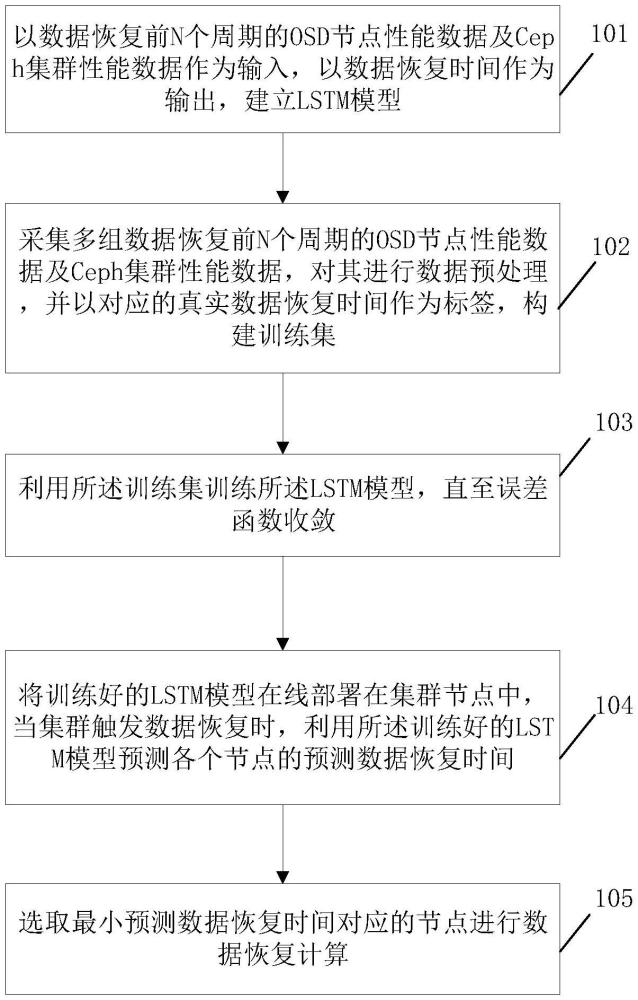
3、以数据恢复前n个周期的osd节点性能数据及ceph集群性能数据作为输入,以数据恢复时间作为输出,建立lstm模型;
4、采集多组数据恢复前n个周期的osd节点性能数据及ceph集群性能数据,对其进行数据预处理,并以对应的真实数据恢复时间作为标签,构建训练集;
5、利用所述训练集训练所述lstm模型,直至误差函数收敛;
6、将训练好的lstm模型在线部署在集群节点中,当集群触发数据恢复时,利用所述训练好的lstm模型预测各个节点的预测数据恢复时间;
7、选取最小预测数据恢复时间对应的节点进行数据恢复计算。
8、优选地,所述osd节点性能数据包括cpu使用率、内存使用率、网络消耗带宽和节点读写io数据量,所述ceph集群性能数据包括集群业务iops,集群恢复速率,缓存数据下刷速率。
9、优选地,所述真实数据恢复时间为:通过构造数据静默错误或数据丢失而建立的数据恢复场景下的数据恢复起始时间与恢复完成时间之间的差值。
10、优选地,所述对数据进行预处理包括:
11、将每组采集的数据按n个周期进行切割,并进行归一化处理。
12、优选地,所述利用所述训练集训练所述lstm模型,直至误差函数收敛包括:
13、利用训练集训练所述lstm模型,并根据误差反向传播算法和优化算法更新模型参数,直至训练的均方根误差小于预设阈值或训练次数达到上限。
14、优选地,所述将训练好的lstm模型在线部署在集群节点中,当集群触发数据恢复时,利用所述训练好的lstm模型预测各个节点的预测数据恢复时间包括:
15、将训练好的lstm模型在线部署在集群节点中;
16、当集群触发数据恢复时,采集恢复对象对应所有osd节点性能数据和ceph集群性能数据;
17、将采集到的前n个周期的性能数据作为模型输入,预测各个节点的数据恢复时间。
18、优选地,所述选取最小预测数据恢复时间对应的节点进行数据恢复计算后还包括:
19、采集前n个周期的性能数据和对应的实际数据恢复时间,并将其添加至训练集,对所述lstm模型进行离线训练;
20、若离线训练完成后的修正lstm模型与在线部署的lstm模型之间的误差大于预设误差阈值,则利用所述修正lstm模型替换在线部署的lstm模型。
21、本发明还提供了一种纠删码数据恢复装置,包括:
22、模型构建模块,用于以数据恢复前n个周期的osd节点性能数据及ceph集群性能数据作为输入,以数据恢复时间作为输出,建立lstm模型;
23、训练集构建模块,用于采集多组数据恢复前n个周期的osd节点性能数据及ceph集群性能数据,对其进行数据预处理,并以对应的真实数据恢复时间作为标签,构建训练集;
24、训练模块,用于利用所述训练集训练所述lstm模型,直至误差函数收敛;
25、预测模块,用于将训练好的lstm模型在线部署在集群节点中,当集群触发数据恢复时,利用所述训练好的lstm模型预测各个节点的预测数据恢复时间;
26、数据恢复模块,用于选取最小预测数据恢复时间对应的节点进行数据恢复计算。
27、本发明还提供了一种纠删码数据恢复设备,包括:
28、存储器,用于存储计算机程序;
29、处理器,用于执行所述计算机程序时实现上述一种纠删码数据恢复方法步骤。
30、本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述一种纠删码数据恢复方法的步骤。
31、本发明的上述技术方案相比现有技术具有以下优点:
32、本发明所述的纠删码数据恢复方法,在数据恢复计算中,结合各个节点的性能信息和训练好的lstm模型进行各节点数据恢复计算时间预测,选取时间最短的节点作为计算节点。相比传统顺序选择无法保障选择最优的计算节点,本发明基于lstm模型可以保障在进行数据修复计算时,计算节点为最优节点,进而确保数据恢复时间最短,提高了数据恢复的效率和速度。
技术特征:
1.一种纠删码数据恢复方法,其特征在于,包括:
2.根据权利要求1所述的纠删码数据恢复方法,其特征在于,所述osd节点性能数据包括cpu使用率、内存使用率、网络消耗带宽和节点读写io数据量,所述ceph集群性能数据包括集群业务iops,集群恢复速率,缓存数据下刷速率。
3.根据权利要求1所述的纠删码数据恢复方法,其特征在于,所述真实数据恢复时间为:通过构造数据静默错误或数据丢失而建立的数据恢复场景下的数据恢复起始时间与恢复完成时间之间的差值。
4.根据权利要求1所述的纠删码数据恢复方法,其特征在于,所述对数据进行预处理包括:
5.根据权利要求1所述的纠删码数据恢复方法,其特征在于,所述利用所述训练集训练所述lstm模型,直至误差函数收敛包括:
6.根据权利要求1所述的纠删码数据恢复方法,其特征在于,所述将训练好的lstm模型在线部署在集群节点中,当集群触发数据恢复时,利用所述训练好的lstm模型预测各个节点的预测数据恢复时间包括:
7.根据权利要求1所述的纠删码数据恢复方法,其特征在于,所述选取最小预测数据恢复时间对应的节点进行数据恢复计算后还包括:
8.一种纠删码数据恢复装置,其特征在于,包括:
9.一种纠删码数据恢复设备,其特征在于,包括:
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至7任一项所述一种纠删码数据恢复方法的步骤。
技术总结
本发明涉及数据存储技术领域,尤其是指一种纠删码数据恢复方法、装置、设备及计算机存储介质。本发明所述的纠删码数据恢复方法,在数据恢复计算中,结合各个节点的性能信息和训练好的LSTM模型进行各节点数据恢复计算时间预测,选取时间最短的节点作为计算节点。相比传统顺序选择无法保障选择最优的计算节点,本发明基于LSTM模型可以保障在进行数据修复计算时,计算节点为最优节点,进而确保数据恢复时间最短,提高了数据恢复的效率和速度。
技术研发人员:熊琦,张攀翔,林纲,杨杰,杭星,朱达慧,倪泳智
受保护的技术使用者:中国移动通信集团广东有限公司
技术研发日:
技术公布日:2024/10/21
- 还没有人留言评论。精彩留言会获得点赞!