一种基于自适应注意力特征融合网络的音乐流派分类方法
本发明属于音乐信息检索及深度学习领域。提出了一种基于自适应注意力特征融合网络的音乐流派分类方法。
背景技术:
1、音乐流派分类是音乐信息检索领域的一项重要任务,对音乐产业、音乐推荐、搜索引擎和组织机构都具有重要意义。随着音乐发展的多样化,流派融合已成为一种普遍现象。它在促进音乐交流与合作的同时,也深刻影响着音乐创作。然而,这也给类型分类工作带来了挑战。传统的分类方法缺乏足够的辨别力,难以有效区分融合音乐中的多种元素。
2、区别融合音乐需要重点考虑音乐性特征,如节奏和旋律,而区分其他音乐则需要均衡考虑音乐性特征与其他特征如,强度,谱密度。这增加了音乐分类的挑战,需要更细致的特征处理,考虑多种特征之间的协同作用。
3、因此,为了有效解决融合音乐的分类问题,必须更全面地捕捉并理解音乐特征,同时平衡在分类不同流派下两种特征的权重关系。当进行分类任务时,融合流派与非融合流派对音乐性特征和其他特征的权重需求存在一些差异。融合流派在处理音乐性特征时倾向于更细致、更多样化的权重分配。此外,融合音乐在不同流派中对各种音乐性特征(例如旋律特征、节奏特征等)的权重需求也不尽相同,因此需要对这些特征进行更为详细的处理。
技术实现思路
1、本发明提供了一种基于自适应注意力特征融合网络的音乐流派分类方法,它能够进行更细致的音乐特征处理并对融合音乐的流派精准分类。
2、本发明的基于自适应注意力特征融合网络的音乐流派分类方法,方法包括:
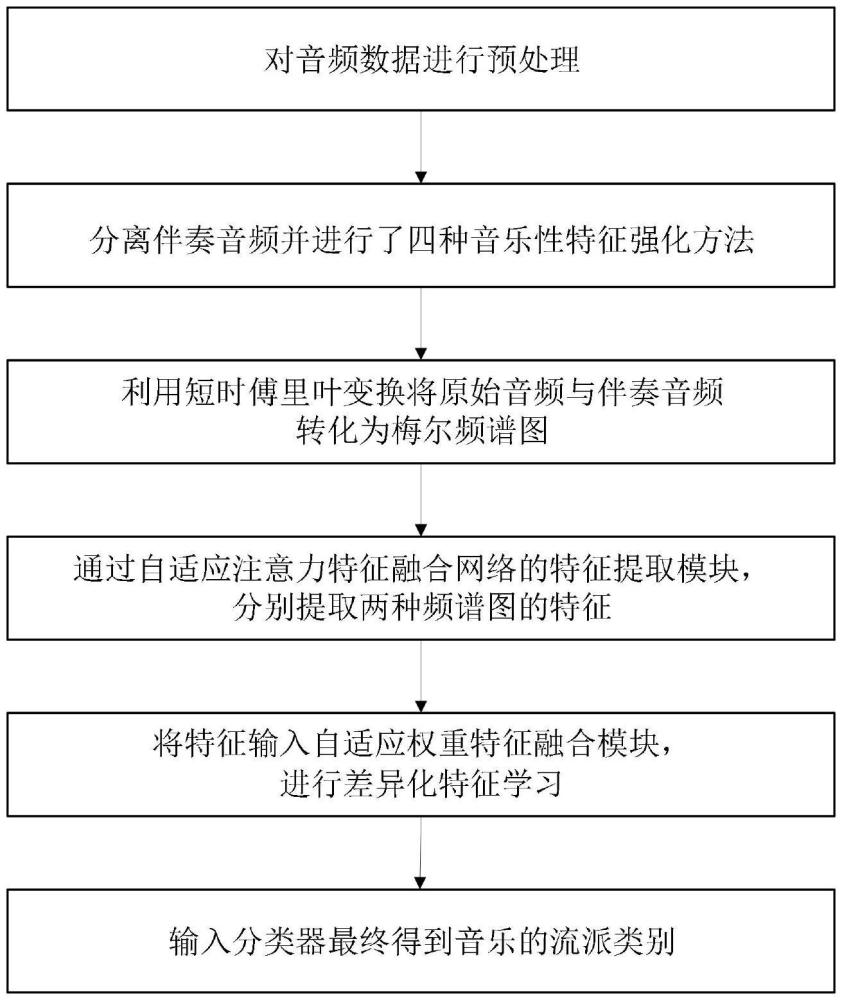
3、1)对音频数据进行预处理:将数据集中所有音频数据处理为30s的波形音频文件,具体为删除时长低于30s的音频数据,截取其余数据的中心30s音频;
4、2)分离伴奏音频并进行了四种音乐性特征强化方法:通过人声分离技术模块得到伴奏音频,并通过添加噪声、时间转移、时间拉伸、时频掩蔽四种方法进行音乐性特征强化。人声分离技术模块具体包括:
5、①采用音乐分离工具spleeter,从数据集的音频中分离人声(包含哼唱与歌词)和伴奏(包含旋律与节拍);
6、②使用预训练的2-source-model在音频数据集上进行调整。
7、音乐性特征强化方法具体包括:
8、①添加噪声方法通过生成随机数并将其转化为均匀噪声,产生新的音频信号加入数据集;
9、②时间转移方法通过将音频统一向左移动1.5s,余下28.5s有效音频和1.5s静音音频,并从头开始裁剪9份各为3s的有效音频数据加入数据集,改变音频的时序特性;
10、③时间拉伸方法通过使用音频处理库soundtouch的变时不变调技术,设置拉伸比例为1.1和0.9,对所有30s的音频进行拉伸处理,生成新的音频;
11、④时频掩蔽方法通过频谱图的频率维度上根据均匀分布随机选择一些连续的频带,并将这些频带的数值设为零,模拟了声音信号中的瞬时失真或中断。
12、3)利用短时傅里叶变换将音频数据转化为梅尔频谱图:提取带有128个梅尔滤波器的梅尔谱图,得到大小为2560×256像素的梅尔谱图。将每段音频的频谱图按256×256像素进行裁剪,得到10个256×256像素的包含了3秒音频信息的子谱图并输入特征提取模块;
13、4)通过自适应注意力特征融合网络的特征提取模块,分别提取原始音频和伴奏音频频谱图的特征,生成两组具有相同维数的特征。特征提取模块具体包括:
14、①采用卷积神经网络提取音频全局和局部特征,生成两组具有相同维数的特征传递给自适应权重特征融合模块;
15、②初始下采样模块由3×3卷积层和2×2最大池化层组成,提取局部特征;
16、③连接6个卷积层和3个最大池化层。其中最后一个卷积层为5×5核,其余卷积层为3×3核,最大池化层为2×2核;
17、④最后连接全局平均池化层,输出1×1×512的特征向量;
18、⑤采用指数线性单元激活函数,全局平均池化对特征进行整合,得到512维的特征输出。
19、5)将特征输入自适应权重特征融合模块,通过计算查询矩阵、键矩阵和值矩阵的关联程度,学习关注权重值,确定每个特征源对分类任务的贡献,进行差异化特征学习。自适应权重特征融合模块具体为:
20、①采用自适应注意力机制自主学习,计算query和key之间的关联程度,并对value矩阵中对应的位置进行加权平均;
21、②权重的计算方式包括:
22、
23、6)输入单个隐藏层的mlp分类器,融合特征输入维度为512,dropout比率为0.3,采用elu激活函数,最终得到音乐的流派类别。分类结果采用投票策略得出分类结果,具体为:
24、①得出每个256×256像素的子谱图的流派类别概率分布;
25、②将每个子谱图的相同流派类别概率分布相加,得到一个总体的类别概率分布;
26、③选择具有最高概率的流派类别作为最终分类结果并输出。
27、进一步的,所述方法还包括:
28、1)使用adam优化器进行模型训练,利用图像的随机水平翻转作为一种数据增强技术;
29、2)模型配置为批量归一化大小为50,采用动态学习率调整策略;
30、3)学习率初始为1e-2,5个循环后,优化器的学习率乘以0.7。
31、本发明有益效果:
32、本发明提出的一种基于自适应注意力特征融合网络的音乐流派分类方法,能够更全面地捕捉并理解音乐特征,同时平衡在分类不同流派下两种特征的权重关系,实现了多特征的优势互补。具体来说,我们在原始音频谱图和伴奏谱图中分别提取特征,学习关注权重值并进行差异化特征学习,再将两种特征进行自适应注意力特征融合,使模型动态调整对不同流派分配的特征权重,充分考虑了非音乐性特征与音乐性特征之间的协同作用。
技术特征:
1.一种基于自适应注意力特征融合网络的音乐流派分类方法,其特征在于,包括:
2.根据权利要求1所述的基于自适应注意力特征融合网络的音乐流派分类方法,其特征在于:步骤2)中所述的人声分离技术模块,采用音乐分离工具spleeter,从数据集的音频中分离人声(包含哼唱与歌词)和伴奏(包含旋律与节拍),并使用预训练的2-source-model在音频数据集上进行调整;其中的人声包含哼唱与歌词,伴奏包含旋律与节拍。
3.根据权利要求1所述的基于自适应注意力特征融合网络的音乐流派分类方法,其特征在于:步骤2)中所述的音乐性特征强化方法,具体为:
4.根据权利要求1所述的基于自适应注意力特征融合网络的音乐流派分类方法,其特征在于:步骤4)所述的自适应注意力特征融合网络的特征提取模块,采用卷积神经网络提取音频全局和局部特征,生成两组具有相同维数的特征传递给自适应权重特征融合模块,具体为:
5.根据权利要求1所述的基于自适应注意力特征融合网络的音乐流派分类方法,其特征在于:步骤5)所述的自适应权重特征融合模块,采用自适应注意力机制自主学习,计算query和key之间的关联程度,并对value矩阵中对应的位置进行加权平均,权重的计算方式包括:
6.根据权利要求1所述的基于自适应注意力特征融合网络的音乐流派分类方法,其特征在于:步骤6)所述的单个隐藏层的mlp分类器,投票策略得出分类结果,具体为:
7.根据权利要求4所述的基于自适应注意力特征融合网络的音乐流派分类方法,其特征在于:自适应注意力特征融合网络的训练方法包括:
技术总结
本发明提供一种基于自适应注意力特征融合网络的音乐流派分类方法,属于音乐信息检索及深度学习领域。为了解决传统卷积网络没有充分考虑音乐特征之间的协同作用,难以区分融合音乐的问题。本发明通过对音频数据进行预处理;分离伴奏音频并进行四种音乐性特征强化方法;利用短时傅里叶变换将原始音频与伴奏音频转化为梅尔频谱图;通过自适应注意力特征融合网络的特征提取模块,分别提取两种频谱图的特征;将特征输入自适应权重特征融合模块,并进行差异化特征学习;输入分类器最终得到音乐的流派类别。本发明主要用于音乐流派的精准分类,避免了流派融合造成的分类偏差问题。
技术研发人员:肖迎元,孟诗婷,郑文广,程徐
受保护的技术使用者:天津理工大学
技术研发日:
技术公布日:2024/8/15
- 还没有人留言评论。精彩留言会获得点赞!