一种面向多神经网络推理场景的边缘端智算芯片共享缓存分配算法
本发明涉及边缘端智能计算系统领域,具体涉及一种面向多神经网络模型推理场景的边缘端智算芯片共享缓存分配算法。
背景技术:
1、基于深度神经网络的复杂人工智能应用往往依赖于多个神经网络模型的推理计算,其中每个模型处理不同类别的数据并解决不同的子问题,各模型之间的计算和访存需求差异显著。因此面向复杂人工智能应用的智算芯片往往采用多加速器架构,即将cpu核心和多个神经网络加速器核心集成为一个片上系统,不同加速器核心执行不同模型推理进程,cpu核心执行多模型推理调度进程以及其他应用进程,从而实现多模型推理的高效并发执行。
2、边缘端智算芯片由于使用场景多样、部署环境灵活多变等原因,其功耗、成本等受到严苛限制,导致芯片各类资源受限。共享高速缓冲存储器(共享缓存)是被所有cpu和神经网络加速器核心所共有的存储资源,共享缓存的容量大小对芯片计算效率、功耗、成本等具有显著影响。在边缘端智算芯片上,共享缓存的容量严重受限,在多神经网络模型推理场景下,各模型推理任务相互竞争缓存资源,共享缓存成为性能瓶颈。
3、缓存划分技术是将缓存空间划分成多个独立的大小不一的子空间,并分配给不同的进程使用,从而避免各个进程之间相互发生缓存竞争。现有的面向多神经网络模型推理的资源分配和任务调度方法没有充分利用缓存划分技术,不能根据不同模型的推理时长和资源需求差异对共享缓存进行合理分配,无法解决边缘端智算芯片的共享缓存成为性能瓶颈的问题。因此,如何合理分配共享缓存是边缘端多神经网络推理场景中亟须解决的问题。
技术实现思路
1、本发明针对多神经网络模型推理场景中,由于边缘端智算芯片的共享缓存容量有限,导致共享缓存成为性能瓶颈的问题,提出一种面向多神经网络推理场景的边缘端智算芯片共享缓存分配算法。本算法根据各模型推理时长和资源需求差异,将不同容量的共享缓存空间分配给不同的模型推理进程,同时根据各模型资源需求在推理过程中的变化动态调整共享缓存划分方案。本算法能够最大化共享缓存利用率,减少共享缓存资源竞争,有效缓解共享缓存的性能瓶颈问题,提升系统整体性能。
2、本发明所提出的共享缓存分配算法是多模型推理调度进程中执行的核心算法,主要解决在多模型推理过程中,何时以及如何分配缓存容量的问题。具体而言,本算法能够决定每个轮次中,各模型需要执行的层数,以及各模型所分配的缓存容量;在不同轮次中,本算法能够重新计算推理层数和缓存容量,从而动态适应推理过程中发生的资源需求变动。
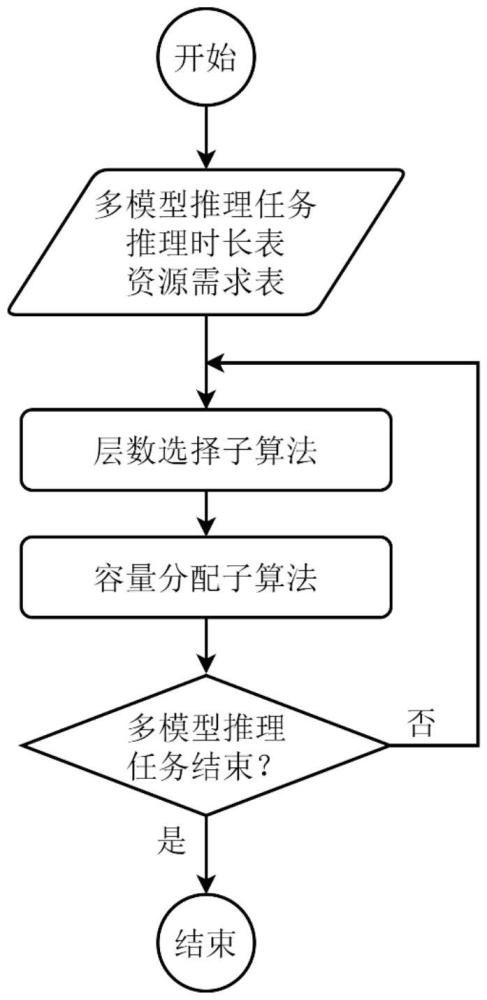
3、本发明所提出的共享缓存分配算法分为两个子算法:(1)层数选择子算法,用于计算本轮次中各模型需要推理的层数;(2)容量分配子算法,用于计算本轮次中各模型所分配的共享缓存容量。
4、所述的两个子算法的执行流程是循环交替执行。具体而言,首先,通过层数选择子算法计算出本轮次中各模型需要推理的层数;其次,通过容量分配子算法计算出本轮次中各模型所分配的共享缓存容量;然后,调度进程等待各模型推理进程在上一轮次的计算任务结束以后,对共享缓存进行重新划分,并且将本轮次各模型需要推理的层数发送给各模型推理进程;最后,调度进程通知各模型推理进程继续执行。调度进程在各模型推理进程执行本轮次推理时,会并行地计算下一轮次的缓存分配方案,因此共享缓存分配算法的执行几乎不会引入额外的时间开销。
5、所述的两个子算法需要基于各模型在部署阶段预先生成的性能预测信息,包括模型各层的推理时长、内存访问量、缓存访问量等信息。为方便后续描述,现将各模型的性能预测信息按照以下方式表示:假设共享缓存的最小可分配子空间数目为c,模型数量为n,模型最大层数为l,则有推理时长表t[1…n][1…l]和资源需求表m[1…c][1…n][1…l]。推理时长表记录了各模型每层的预测推理时长,即t[n][l]表示模型n的第l层的预测推理时长。资源需求表记录了不同缓存容量分配情况下,各模型每层执行过程中的资源需求量,资源需求量是由内存访问量、缓存访问量、执行时长等信息按一定权重综合计算得到的,具体计算方式取决于计算芯片的内存带宽、片上网络带宽、共享缓存总容量等芯片性能信息。
6、所述的层数选择子算法是用于计算本轮次中各模型需要推理的层数。由于对共享缓存容量的重新分配需要同步暂停各个模型推理进程,因此层数选择子算法需要尽可能地匹配各模型在同一轮次中的执行时间长度,从而避免某些模型推理进程因过早完成本轮次的推理任务而导致的大量计算资源空闲。具体而言,假设在本轮次中,模型n需要推理层数是ln,则其推理时长为则该轮次最长推理时长基于以上定义,最小化计算资源空闲问题可以抽象为下述最优化问题形式:
7、
8、s.t.1≤ln≤l,n=1…n
9、所述的层数选择子算法采用动态规划方法解决上述最优化问题。为方便说明,定义ln,t用于表示当本轮次最长推理时长为t时模型n能够执行的最大层数,定义t′[1…n][1…l]为累计推理时长表,即t′[n][l]表示模型n前l层累计推理时长,定义t″[1…k]为顺序时间节点表,其中k=n×l,t″是将t′中的所有时间节点重新排列的结果。基于上述定义,现定义动态规划状态表si[1…k],状态si[k]表示当本轮次最长推理时长不超过t″[k]时所能够达到的最小计算资源空闲量,则状态转移方程定义如下:
10、
11、所述的容量分配子算法是用于计算出在本轮次中各模型能够使用的共享缓存容量。神经网络模型推理任务在不同的缓存容量下的内存访问量、缓存访问量等信息存在差异,具体而言,在一定范围内,随着缓存容量的增加,模型推理任务的内存访问量和缓存访问量会有不同程度地下降,而超过该范围后,内存访问量和缓存访问量不会再进一步下降。因此,面向多模型推理任务的最优缓存容量分配方案应当保证最小的总资源需求量,从而尽可能减少资源竞争现象的出现。具体而言,假设层数选择算法计算得到的本轮次中模型n的最优执行层数为ln,模型n所分配的缓存容量为cn,则其资源需求量为基于以上定义,最小化资源需求问题可以抽象为下述最优化问题形式:
12、
13、所述的容量分配子算法采用动态规划算法解决上述最优化问题。为方便描述,定义m′[1…c][1..n]为累计的资源需求量,即m′[c][n]表示模型n在缓存容量c下连续推理ln层的累计的资源需求量。基于上述定义,现定义动态规划状态表sr[1…c][1…n],状态sr[c][n]表示当缓存最大容量为c时,模型1…n的最优容量分配策略能够达到的最小资源需求量,则状态转移方程定义如下:
14、
技术特征:
1.一种面向多神经网络模型推理场景的边缘端智算芯片共享缓存分配算法,其特征在于,根据各模型在模型部署阶段生成的性能预测信息,将共享缓存划分成容量不同的多个缓存空间并分配给不同模型推理进程使用,并且根据各模型在推理过程中的资源需求变化动态调整共享缓存容量分配方案。
2.根据权利要求1所述的共享缓存容量分配算法,其特征在于,所述的性能预测信息包括各模型各层的预测推理时长,以及各模型各层在不同的缓存容量配置下的资源需求量。所述的资源需求量是由内存访问量、缓存访问量、执行时长等信息按一定权重综合计算得到的,具体计算方式取决于计算芯片的内存带宽、片上网络带宽、共享缓存总容量等芯片性能属性。
3.根据权利要求1所述的共享缓存容量分配算法,其特征在于,该算法可以分为层数选择子算法和容量分配子算法:层数选择子算法用于计算本轮次中各模型需要推理的层数;容量分配子算法用于计算本轮次中各模型所分配的共享缓存容量。
4.根据权利要求3所述的层数选择子算法和容量分配子算法,其特征在于,所述的两个子算法的执行流程是循环交替执行的;具体而言,首先,通过层数选择子算法计算出本轮次中各模型需要推理的层数;其次,通过容量分配子算法计算出本轮次中各模型所分配的共享缓存容量;然后,调度进程等待各模型推理进程在上一轮次的计算任务结束以后,对共享缓存进行重新划分,并且将本轮次各模型需要推理的层数发送给各模型推理进程;最后,调度进程通知各模型推理进程继续执行;调度进程在各模型推理进程执行本轮次推理时,会并行地计算下一轮次的缓存分配方案,因此共享缓存分配算法的执行几乎不会引入额外的时间开销。
5.根据权利要求3所述的层数选择子算法,其特征在于,该算法用于求解一个最优化问题,该问题是计算出在本轮次中各模型所需推理的层数,目标是最小化因某些模型推理进程提前结束而造成的计算资源空闲时间。
6.根据权利要求3所述的层数选择子算法,其特征在于,该算法采用了动态规划方法,从而提高了最优化问题的求解速度。
7.根据权利要求3所述的容量分配子算法,其特征在于,该算法用于求解一个最优化问题,该问题是计算出在本轮次中各模型所分配的共享缓存容量,目标是最小化所有模型推理产生的资源需求总量。
8.根据权利要求3所述的容量分配子算法,其特征在于,该算法采用了动态规划方法,从而提高了最优化问题的求解速度。
技术总结
本发明提供了一种面向多神经网络模型推理场景的边缘端智算芯片共享缓存分配算法。本算法分为层数选择子算法和容量分配子算法。首先,层数选择子算法根据各模型各层的预测推理时长,计算出本轮次中各模型应当推理的层数,以最小化计算资源空闲;其次,容量分配子算法根据不同缓存容量下各模型的预测资源需求量,计算出各模型所分配的缓存容量,以最小化资源需求总量。层数选择子算法和容量分配子算法均采用动态规划方法,以降低算法时间复杂度。本发明提供的算法能有效改善多模型推理场景下,边缘端智算芯片缓存资源竞争问题,从而提高系统整体性能。
技术研发人员:肖利民,蔡天昊,韩萌,王良,徐向荣,谢喜龙,郑帅
受保护的技术使用者:北京航空航天大学
技术研发日:
技术公布日:2024/9/29
- 还没有人留言评论。精彩留言会获得点赞!