一种基于大语言模型的试题智能生成方法及系统
本发明涉及智能出题,尤其涉及一种基于大语言模型的试题智能生成方法及系统。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
2、传统的出题方式往往需要教师花费大量时间设计、编纂、筛选以及整理题目,不仅耗时、耗力、易出错,且更容易受到其个人主观性和偏见的影响更难以保证考卷的公正公平性。借助人工智能技术,可以自动分析知识点、题型、难度等要素条件,快速生成符合要求的试卷。这不仅大大减轻了教师的工作负担,也确保了出题过程的客观性和公正性。
3、基于规则自动生成问题,即通过设计启发式的规则,实现描述性文本到相关问题的转化。虽然基于规则的试题生成方法的研究证明了自动化试题生成的可能性,但是具有较大的限制。首先,由于语言的复杂性,难以归纳出符合所有问题的规则,而且不同领域的文本规则差异较大。因此,基于规则的试题生成算法移植性很差,且难以进行扩展。
4、基于神经网络模型的试题生成方法相较于基于规则的方法取得了较大的进步,但仍然有以下几个缺点。首先,神经网络模型通常需要大量的训练来达到较高的性能,长时间的训练不仅增加了计算成本,还可能限制模型在实际应用中的使用。其次,神经网络模型的性能高度依赖于训练数据的质量和多样性。如果训练数据存在偏差或不足,模型生成的问题可能会表现出相似的模式或问题,从而降低了问题的多样性和有效性。
技术实现思路
1、为了解决上述背景技术中存在的技术问题,本发明提供一种基于大语言模型的试题智能生成方法及系统,本发明可以生成高质量的试题和答案,同时具有较强的可移植性和多样性。
2、为了实现上述目的,本发明采用如下技术方案:
3、本发明的第一个方面提供一种基于大语言模型的试题智能生成方法。
4、一种基于大语言模型的试题智能生成方法,包括:
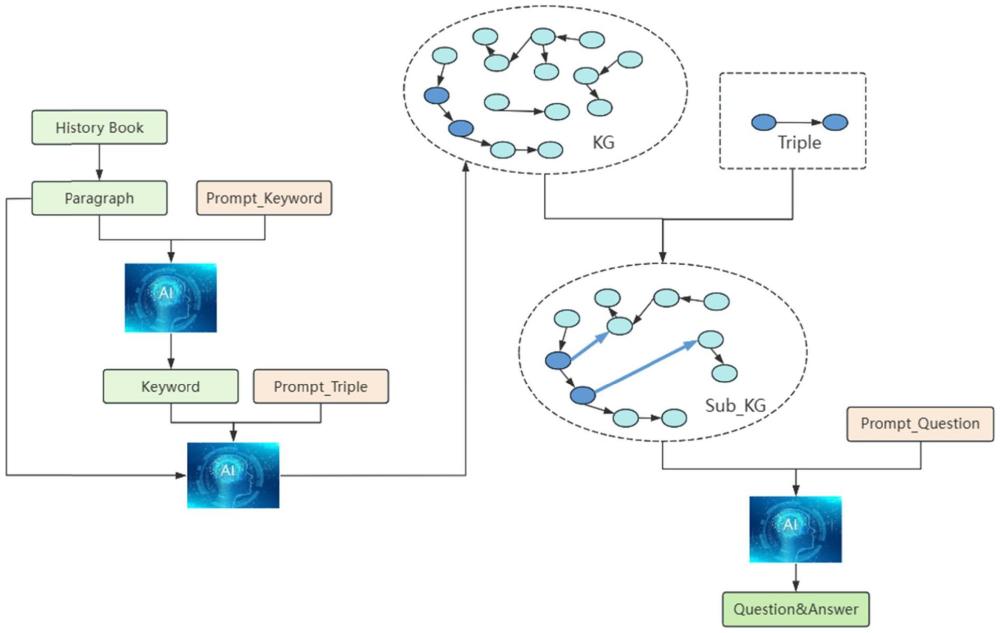
5、基于历史课本数据,提取关键词,包括时间、人物和思想;
6、基于所述关键词,提取关键词之间的关系,并以三元组的形式输出,构建知识图谱;
7、依据指定三元组中的实体部分,在知识图谱中进行广度搜索,查找所述实体部分出现的所有三元组,构建第一三元组集合,计算第一三元组集合中的每个三元组与指定三元组之间的相关度得分,若所述相关度得分大于设定阈值,则将该三元组加入到第二三元组集合中,并将相关度得分加入到分数集合中;广度搜索结束后,将分数集合中的分数按照降序排列得到其排序后的索引序列,若第二三元组集合的长度大于设定值,集合截取到设定值为最新索引集合,并从中随机挑选若干个索引;否则,直接截取最前面若干个索引;根据索引选取对应的三元组,组成相关子图;
8、基于所述相关子图、预设的题目类型以及试题提示,采用大语言模型,生成问题和对应的答案。
9、进一步地,所述相关度得分为字符相关得分和语义相关得分的平均值;所述字符相关得分为两个三元组头尾拼接文本之间的jaccard系数;所述语义相关得分为采用语言模型对每个三元组的头实体和尾实体进行编码,计算编码之间的余弦距离,并将余弦距离最大值作为语义相关得分。
10、进一步地,得到所述相关子图的过程采用以下公式:
11、
12、其中,ki表示其关键词,headi表示其头实体,taili表示其尾实体,reli表示其头实体和尾实体的关系,t表示指定三元组,b表示在知识图谱上进行广度搜索的层数,n表示相关子图中三元组的个数,θ表示相关度得分的阈值,kg表示知识图谱。
13、进一步地,所述基于所述相关子图、预设的题目类型以及试题提示,采用大语言模型,生成问题和对应的答案的过程采用以下公式:
14、(question,answer)=llm(l,d,pq,kg)
15、其中,llm表示大语言模型,l表示相关子图,d表示题目类型,pq表示试题提示,kg表示知识图谱。
16、进一步地,在广度搜索过程中,若第二三元组集合中某个三元组的实体部分未在已有的实体集合中出现,则将该三元组的实体部分加入到已有的实体集合中。
17、进一步地,在于构建知识图谱之前还包括:收集历史教材,将历史教材从pdf格式转换为txt格式,保留有效文本;基于有效文本,根据文本的段落关系进行文本切分,以此将有效文本转换成包含若干单词的段落。
18、进一步地,所述保留有效文本的过程包括:去除历史教材中的侧边栏、章节习题和插图。
19、本发明的第二个方面提供一种基于大语言模型的试题智能生成系统。
20、一种基于大语言模型的试题智能生成系统,包括:
21、关键词提取模块,其被配置为:基于历史课本数据,提取关键词,包括时间、人物和思想;
22、知识图谱构建模块,其被配置为:基于所述关键词,提取关键词之间的关系,并以三元组的形式输出,构建知识图谱;
23、相关子图生成模块,其被配置为:依据指定三元组中的实体部分,在知识图谱中进行广度搜索,查找所述实体部分出现的所有三元组,构建第一三元组集合,计算第一三元组集合中的每个三元组与指定三元组之间的相关度得分,若所述相关度得分大于设定阈值,则将该三元组加入到第二三元组集合中,并将相关度得分加入到分数集合中;广度搜索结束后,将分数集合中的分数按照降序排列得到其排序后的索引序列,若第二三元组集合的长度大于设定值,集合截取到设定值为最新索引集合,并从中随机挑选若干个索引;否则,直接截取最前面若干个索引;根据索引选取对应的三元组,组成相关子图;
24、智能生成模块,其被配置为:基于所述相关子图、预设的题目类型以及试题提示,采用大语言模型,生成问题和对应的答案。
25、本发明的第三个方面提供一种计算机可读存储介质。
26、一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述第一个方面所述的基于大语言模型的试题智能生成方法中的步骤。
27、本发明的第四个方面提供一种计算机设备。
28、一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述第一个方面所述的基于大语言模型的试题智能生成方法中的步骤。
29、与现有技术相比,本发明的有益效果是:
30、本发明通过以关键词为中心,提高了三元组数据的有效性和真实性,并构建历史知识图谱。
31、本发明通过增加三元组个数、添加学科关键词和采用上下文学习算法这些途径对提示中的三元组进行数据扩充,生成了高质量的试题和答案。
32、本发明提供一种基于大语言模型的试题智能生成系统,进行清晰的模块划分,同时具有较强的可移植性和多样性。
技术特征:
1.一种基于大语言模型的试题智能生成方法,其特征在于,包括:
2.根据权利要求1所述的基于大语言模型的试题智能生成方法,其特征在于,所述相关度得分为字符相关得分和语义相关得分的平均值;所述字符相关得分为两个三元组头尾拼接文本之间的jaccard系数;所述语义相关得分为采用语言模型对每个三元组的头实体和尾实体进行编码,计算编码之间的余弦距离,并将余弦距离最大值作为语义相关得分。
3.根据权利要求1所述的基于大语言模型的试题智能生成方法,其特征在于,得到所述相关子图的过程采用以下公式:
4.根据权利要求1所述的基于大语言模型的试题智能生成方法,其特征在于,所述基于所述相关子图、预设的题目类型以及试题提示,采用大语言模型,生成问题和对应的答案的过程采用以下公式:
5.根据权利要求1所述的基于大语言模型的试题智能生成方法,其特征在于,在广度搜索过程中,若第二三元组集合中某个三元组的实体部分未在已有的实体集合中出现,则将该三元组的实体部分加入到已有的实体集合中。
6.根据权利要求1所述的基于大语言模型的试题智能生成方法,其特征在于,在于构建知识图谱之前还包括:收集历史教材,将历史教材从pdf格式转换为txt格式,保留有效文本;基于有效文本,根据文本的段落关系进行文本切分,以此将有效文本转换成包含若干单词的段落。
7.根据权利要求6所述的基于大语言模型的试题智能生成方法,其特征在于,所述保留有效文本的过程包括:去除历史教材中的侧边栏、章节习题和插图。
8.一种基于大语言模型的试题智能生成系统,其特征在于,包括:
9.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现如权利要求1-7中任一项所述的基于大语言模型的试题智能生成方法中的步骤。
10.一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1-7中任一项所述的基于大语言模型的试题智能生成方法中的步骤。
技术总结
本发明涉及智能出题技术领域,提供了一种基于大语言模型的试题智能生成方法及系统。该方法包括,基于历史课本数据,提取关键词;基于所述关键词,提取关键词之间的关系,并以三元组的形式输出,构建知识图谱;依据指定三元组中的实体部分,在知识图谱中进行广度搜索,查找实体部分出现的所有三元组,构建第一三元组集合,计算第一三元组集合中的每个三元组与指定三元组之间的相关度得分,若相关度得分大于设定阈值,则将该三元组加入到第二三元组集合中,并将相关度得分加入到分数集合中;根据若干个分数选取所述分数对应的三元组,组成相关子图;基于所述相关子图、预设的题目类型以及试题提示,采用大语言模型,生成问题和对应的答案。
技术研发人员:李倩,赵子晴,崔立真
受保护的技术使用者:山东大学
技术研发日:
技术公布日:2024/10/17
- 还没有人留言评论。精彩留言会获得点赞!