一种基于大模型的文档指标审评方法
本发明属于数据处理领域,尤其涉及一种基于大模型的文档指标审评方法。
背景技术:
1、随着人工智能技术的迅猛发展,自然语言处理(nlp)技术在医疗领域的应用正在逐步深入,特别是在文档指标审评领域。自然语言模型的引入代表着审评效率将会得到明显提高,人们不再需要从事这项重复的工作,收集、查找相关资料后再进行审评。但是,如何有效地将这些模型和算法应用在指标文件的审评中,依旧是一个充满挑战的问题。
2、在传统的文档指标评审过程中,企业和个人作为提交主体,负责将相关的指标文档上传至官方指定的评审单位。评审单位在接收到这些文档资料后,首先进行初步的审核,评审单位会立案并进行正式的审查流程。在这个过程中,评审单位会根据评审任务的优先级和复杂程度,合理分配评审资源,确保评审工作的高效进行。评审人员接手案件后,会根据文档的内容和性质,将其分配给具有相关专业背景和经验的评审人员。这些专业人员会依据国家或行业标准、法律法规以及相关政策,对文档中的指标进行全面而细致的审查。最终,评审单位会综合所有评审人员的意见和建议,形成最终的评审报告。这份报告会详细记录文档指标的审查结果、存在的问题以及改进建议,为企业和个人提供宝贵的反馈。
3、尽管传统的文档指标评审流程在严谨性和可靠性方面已经建立了良好的标准,但在效率和资源利用方面存在显著的局限性。从效率的角度来看,传统的评审流程往往耗时较长,因为涉及到人工处理大量的文档资料,包括收集、整理、分析和评估。从资源的角度来看,培养一名合格的专业审评人员需要经过长期的教育和训练,这不仅消耗了大量的时间,也涉及到了高昂的经济成本。此外,审评人员的工作负担通常非常沉重,他们需要处理大量的文档,并经常进行重复性的工作,如数据的核对和标准化,这些工作本可以通过自动化技术来减轻。
技术实现思路
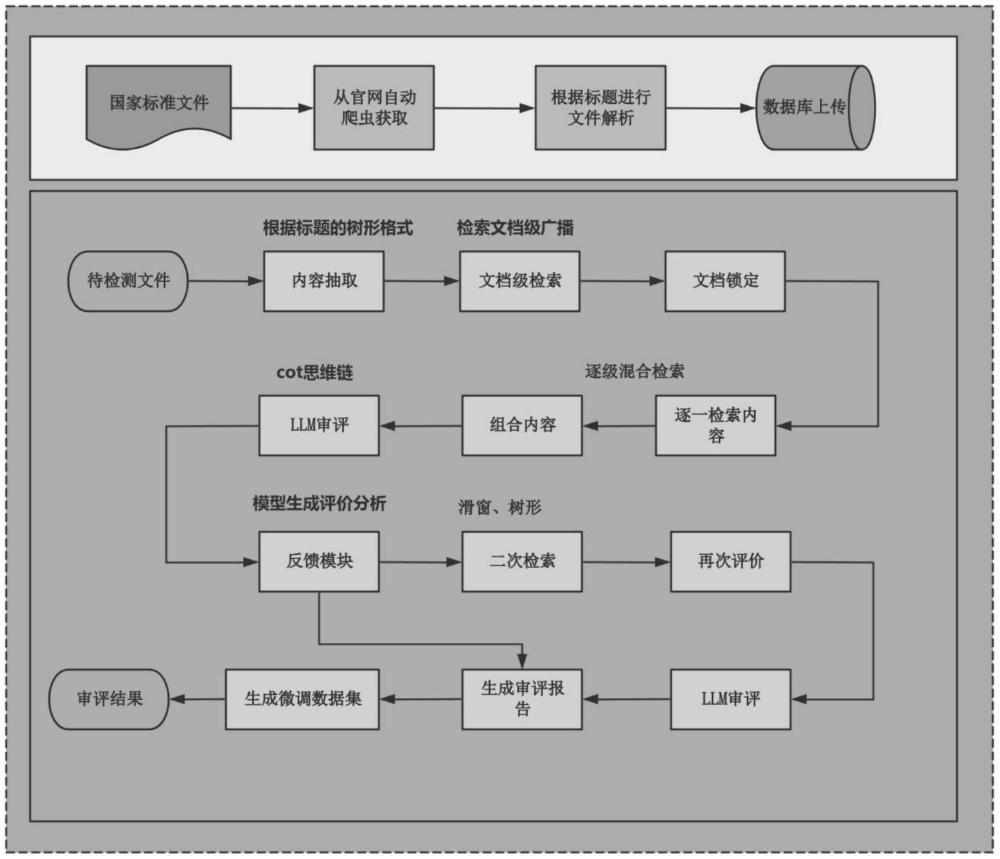
1、有鉴于现有技术的上述缺陷,本发明提出一种基于大模型的文档指标审评方法,本发明设计的技术方案步骤包括:
2、s10:采集国家标准文件;
3、s20:对所述国家标准文件进行统一化处理并存入向量数据库;
4、s30:基于待检测文档在所述向量数据库中寻找对应国家标准文件;
5、s40:逐一检索所述待检测文档的标题和文本,以标题检索为优先,文本检索为辅助,从大到小拆分文本块检索,目标检索到所述待检测文档和对应国家标准文件的最小单元的文本对应关系;
6、s50:基于openai的审评模型输出审评结果,所述待检测文档作为审评模型的输入,所述对应国家标准文件作为审评模型的证据,输出审评结果;
7、s60:对所述评审结果进行反馈判断,并对不符合反馈判断的评审结果进行二次评审更替评审结果;
8、s70:整理评审结果并组成微调数据集。
9、优选地,所述s10包括使用网络爬虫程序,对国家标准官方网站进行抓取国家标准文件。
10、优选地,所述s10还包括对所述国家标准文件进行pdf转图片水印去除处理和版面恢复文档复原处理;
11、所述pdf转图片水印去除处理包括使用图片转化技术将所述国家标准文件的pdf文件逐页转化为png格式的图片,使用像素点修改技术对所述png格式的图片进行识别并移除官方的红色水印。
12、优选地,所述版面恢复文档复原处理包括采用光学ocr技术对所述png格式的图片中的文字内容进行精准定位、排版还原及结构化提取,基于深度学习技术识别并重建文档的原始布局,包括png格式的图片元素的位置与层次关系,并转换为可编辑的docx格式文档。
13、优选地,所述s20包括:将所述国家标准文件中的指标进行提取,按照标题等级的区分形成一颗json格式的指标树状文本,使用embedding模型进行文本内容的嵌入,将向量和文档树的位置信息和父子信息关联都存储到es向量数据库中去,其中的输入参数dims为向量长度,为768维,字段为text类型用于配置bm25算法检索。
14、优选地,所述s60包括以下步骤:
15、s601:计算输入和证据的相似度isrel,计算审评模型的输入、审评结果和证据之间的支持度issup;
16、s602:判断相似度isrel和支持度lssup是否大于等于预设阈值,是,反馈为待定评审结果并执行步骤s6003;否,反馈为有误评审结果;
17、s603:计算输入和审评结果的适用度isuse并判断是否大于等于预设阈值,是,将待定评审结果进一步反馈为准确评审结果;否,采用全文检索进行二次审评更替待定评审结果。
18、优选地,所述isrel、issup、isuse为模型prompt编写的判断。
19、优选地,如图3所示,所述采用全文检索进行二次审评更替待定评审结果包括以下步骤:
20、s6001:对审评模型的输入和证据进行滑窗检索,将检索到的文本块取前后的文本加入一起形成大文本;
21、s6002:将大文本分块拆分为文本句子、文本关键词和文本摘要,并制作索引到大文本;
22、s6003:将文本句子、文本关键词和文本摘要构成树节点并进行余弦相似度检索,根据规则将树节点的同级和/或父子节点作为补充信息返回;
23、s6004:基于补充信息返回,更替评审结果并输出。
24、有益效果:本发明提出一种基于大模型的文档指标审评方法,通过向量数据库和大模型的结合,能够快速匹配待检测文档和国家标准文件;利用大模型(openai的模型)进行审评,能够更精确地判断文档是否符合国家标准,提高审评的准确性和一致性;通过逐一检索标题和文本,并从大到小拆分文本块,可以实现细粒度的文档审评,确保每一个文本单元都得到仔细检查,对于初次审评结果不满意的部分,系统可以进行二次评审,逐步优化审评结果,保证最终输出的结果更加符合预期。
技术特征:
1.一种基于大模型的文档指标审评方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于大模型的文档指标审评方法,其特征在于,所述s10包括使用网络爬虫程序,对国家标准官方网站进行抓取国家标准文件。
3.根据权利要求2所述的一种基于大模型的文档指标审评方法,其特征在于,所述s10还包括对所述国家标准文件进行pdf转图片水印去除处理和版面恢复文档复原处理;
4.根据权利要求3所述的一种基于大模型的文档指标审评方法,其特征在于,所述版面恢复文档复原处理包括采用光学ocr技术对所述png格式的图片中的文字内容进行精准定位、排版还原及结构化提取,基于深度学习技术识别并重建文档的原始布局,包括png格式的图片元素的位置与层次关系,并转换为可编辑的docx格式文档。
5.根据权利要求1所述的一种基于大模型的文档指标审评方法,其特征在于,所述s20包括:将所述国家标准文件中的指标进行提取,按照标题等级的区分形成一颗json格式的指标树状文本,使用embedding模型进行文本内容的嵌入,将向量和文档树的位置信息和父子信息关联都存储到es向量数据库中去,其中的输入参数dims为向量长度,为768维,字段为text类型用于配置bm25算法检索。
6.根据权利要求1所述的一种基于大模型的文档指标审评方法,其特征在于,所述s60包括以下步骤:
7.根据权利要求6所述的一种基于大模型的文档指标审评方法,其特征在于,所述isrel、issup、isuse为模型prompt编写的判断。
8.根据权利要求7所述的一种基于大模型的文档指标审评方法,其特征在于,所述采用全文检索进行二次审评更替待定评审结果包括以下步骤:
技术总结
本申请涉及数据处理技术领域,本申请提供一种基于大模型的文档指标审评方法,包括:S10:采集国家标准文件;S20:对所述国家标准文件进行统一化处理并存入向量数据库;S30:基于待检测文档在所述向量数据库中寻找对应国家标准文件;S40:逐一检索所述待检测文档的标题和文本;S50:基于OpenAI的审评模型输出审评结果,所述待检测文档作为审评模型的输入,所述对应国家标准文件作为审评模型的证据,输出审评结果;S60:对所述评审结果进行反馈判断,并对不符合反馈判断的评审结果进行二次评审更替评审结果;S70:整理评审结果并组成微调数据集。本申请通过规范了审评的模式,每一步都有迹可寻,可以溯源追踪到审评的每一步,效果更加出众和方便。
技术研发人员:尚文利,邝金华,李引,肖乐杰,时昊天,常志伟,王一龙,何维
受保护的技术使用者:广州大学
技术研发日:
技术公布日:2024/9/9
- 还没有人留言评论。精彩留言会获得点赞!