一种异构场景下复杂技能主动学习、增强与虚实迁移方法
本申请涉及深度强化学习领域,尤其涉及一种异构场景下复杂技能主动学习、增强与虚实迁移方法。
背景技术:
1、当前基于强化学习尤其是深度强化学习的技能学习方法在机器人相关应用领域取得了较大的成功。但由于强化学习在训练智能体过程中需在交互环境中基于试错探索机制进行学习,导致智能体难以高效地训练得到最优或次优的策略,这对技能策略训练的高效性和稳定性提出了巨大挑战。
2、随着强化学习、模仿学习等方法逐渐被应用到3c装配领域,但技能学习通常需要大量的训练数据,在真实环境中数据收集成本高昂,直接实施策略训练通常是不可行。
技术实现思路
1、本申请旨在至少在一定程度上解决相关技术中的技术问题之一。
2、为此,本申请的第一个目的在于提出一种异构场景下复杂技能主动学习、增强方法,在没有教师模型或示教数据的情况下,在技能学习领域借鉴人类互学习的机制来增强技能学习的性能表现和稳定性。
3、本申请的第二个目的在于提出一种虚实迁移方法,实现操作技能从仿真环境到真实装配环境的虚实迁移。
4、为达上述目的,本申请第一方面实施例提出了一种异构场景下复杂技能主动学习、增强方法,包括:
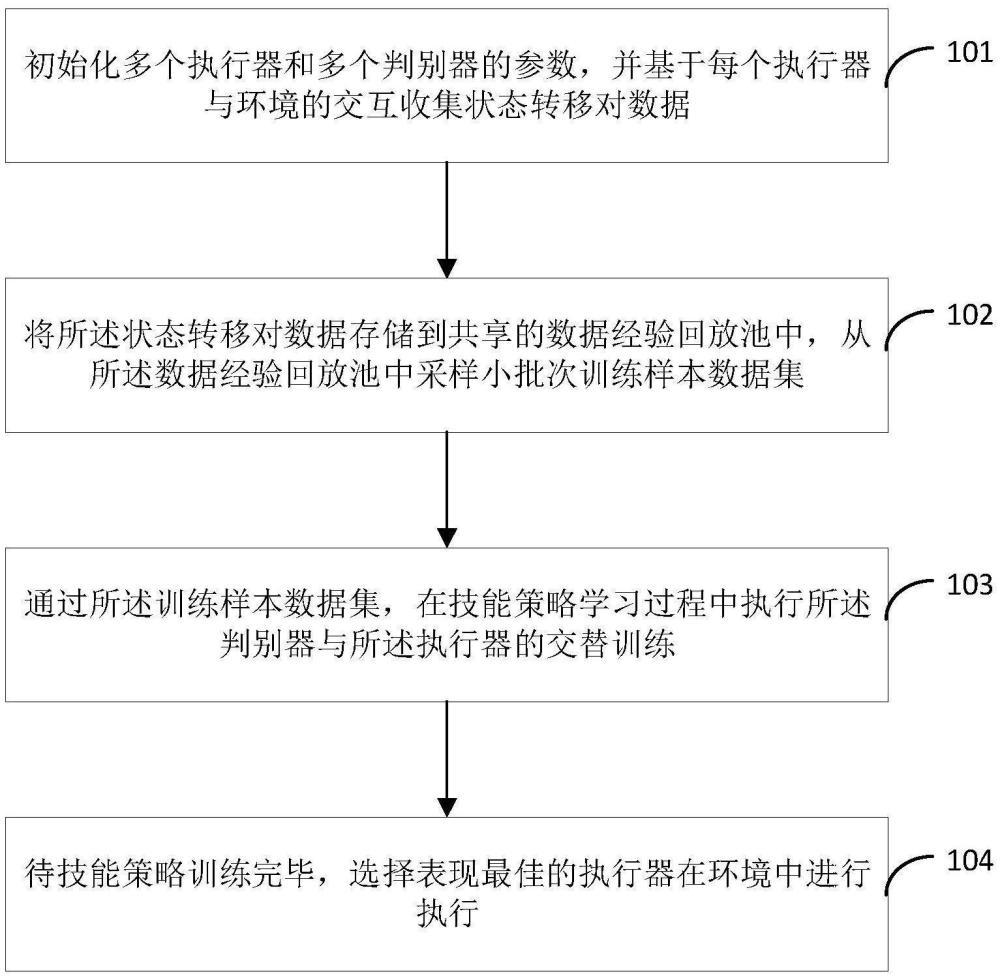
5、初始化多个执行器和多个判别器的参数,并基于每个执行器与环境的交互收集状态转移对数据;
6、将所述状态转移对数据存储到共享的数据经验回放池中,从所述数据经验回放池中采样小批次训练样本数据集;
7、通过所述训练样本数据集,在技能策略学习过程中执行所述判别器与所述执行器的交替训练;
8、待技能策略训练完毕,选择表现最佳的执行器在环境中进行执行。
9、可选的,所述基于每个执行器与环境的交互收集状态转移对数据{(st,at,rt,st+1)},包括:
10、在每个交互时间步t,每个执行器πθi接收状态st并输出对应于状态st的动作正态分布,其中,i表示第i个策略函数,θ表示策略函数的参数;
11、从所述正态分布中采样动作at:t~πθi(·|t),并控制执行器πθi在交互环境中进行执行at;
12、执行完动作at后,执行器πθi的状态转移到新的状态st+1并接收到奖励rt。
13、可选的,还包括:
14、所有执行器共享数据经验回放池不同执行器与环境交互得到的状态转移对数据被存储在同一个数据经验回放池中;
15、当所述数据经验回放池达到最大容量时,采用先进先出原则用最新收集到的交互收集状态转移对数据替换最早收集到的交互收集状态转移对数据。
16、可选的,所述在技能策略学习过程中执行所述判别器与所述执行器的交替训练,包括:
17、每个判别器的训练开始于计算目标值y,所有判别器都基于最小化均方误差的形式进行优化;
18、每个执行器πθi的训练开始于计算蒸馏损失,并使用梯度上升法对每个执行器的参数进行优化。
19、为达上述目的,本申请第二方面实施例提出了一种虚实迁移方法,包括:
20、基于真实3c装配场景构建数字孪生环境,在所述数字孪生环境中采集多模态示教数据;
21、基于所述多模态示教数据的技能解析建立技能知识库,根据所述技能指示库生成操作任务的基本策略序列;
22、采用残差强化学习和课程学习对每个基元策略序列进行学习,通过编码器-解码器模型实现技能策略从数字孪生环境到真实环境的迁移,所述技能策略是通过上述第一方面中任一项所述异构场景下复杂技能主动学习、增强方法得到的。
23、可选的,所述基于真实3c装配场景构建数字孪生环境,在所述数字孪生环境中采集多模态示教数据,包括:
24、基于unity仿真引擎构建与真实3c装配场景等效并一致的所述孪生环境;
25、基于虚拟现实vr设备在所述数字孪生环境中实现对所述多模态示教数据的采集。
26、可选的,所述多模态示教数据的技能解析过程,包括:
27、通过时间-空间-事件相关模型,对采集的所述多模态示教数据进行精确解析,得到rgb-d图像和三维力数据;
28、使用时间-空间-接触特征分割系统对所述多模态示教数据的装配动作序列进行识别和分割。
29、可选的,所述采用残差强化学习和课程学习对每个基元策略序列进行学习,包括:
30、在每个时间步t,对于给定的状态-动作对,目标函数优化遵循所述技能策略执行时最大化获得的预期累计奖励,动作是由所述技能策略输出用于控制机器人的运动的指令。
31、可选的,所述通过编码器-解码器模型实现技能策略从数字孪生环境到真实环境的迁移,包括:
32、将编码器作为图像输入的特征提取器,实现将所述技能策略从数字孪生环境迁移到真实环境的装配场景中。
33、可选的,还包括:
34、使用多层次知识结构表示机器人的基本操作,通过动态层对从人类动作演示中推导出的动作序列进行存储,通过静态层存储在任务场景中相对固定的基础知识。
35、本申请的实施例提供的技术方案至少带来以下有益效果:
36、在异构场景下复杂技能主动学习、增强过程中,通过结合强化学习和知识蒸馏技术,不仅提高了技能学习的效率,还增强了策略的鲁棒性和泛化能力,为解决复杂环境下的技能学习问题提供了一种新的视角和方法;并且,基于数字孪生环境辅助的3c装配操作技能学习方法,不仅提升了技能学习的效率和准确性,还极大地增强了技能在复杂和不确定环境中的应用潜力,实现操作技能从仿真环境到真实装配环境的虚实迁移,进而在真实装配环境中,可以完成机器人在虚拟环境中的操作任务,减少了虚拟与真实空间域的误差,对于在装配环境中典型且常见的拾放、插孔等任务,机器人完成准确率得到提升,具有鲁棒性。
37、本申请附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本申请的实践了解到。
技术特征:
1.一种异构场景下复杂技能主动学习、增强方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述基于每个执行器与环境的交互收集状态转移对数据{(st,at,rt,st+1)},包括:
3.根据权利要求1所述的方法,其特征在于,还包括:
4.根据权利要求1所述的方法,其特征在于,所述在技能策略学习过程中执行所述判别器与所述执行器的交替训练,包括:
5.一种虚实迁移方法,其特征在于,包括:
6.根据权利要求5所述的方法,其特征在于,所述基于真实3c装配场景构建数字孪生环境,在所述数字孪生环境中采集多模态示教数据,包括:
7.根据权利要求5所述的方法,其特征在于,所述多模态示教数据的技能解析过程,包括:
8.根据权利要求5所述的方法,其特征在于,所述采用残差强化学习和课程学习对每个基元策略序列进行学习,包括:
9.根据权利要求5所述的方法,其特征在于,所述通过编码器-解码器模型实现技能策略从数字孪生环境到真实环境的迁移,包括:
10.根据权利要求5所述的方法,其特征在于,还包括:
技术总结
本申请提出了一种异构场景下复杂技能主动学习、增强与虚实迁移方法,该方法包括:首先通过多执行器环境互动收集状态数据,存入共享经验池,采样后交替训练执行器与判别器,最终选定最优执行器部署,实现复杂技能主动学习与增强;然后在3C装配的数字孪生环境下,通过采集多模态数据构建技能知识库,生成策略序列,运用残差强化学习等技术优化,通过编码解码模型实现技能策略从虚拟到现实的迁移。基于本申请提出的方案,没有教师模型或示教数据的情况下,通过结合强化学习和知识蒸馏技术,提高了技能学习的效率,为解决复杂环境下的技能学习问题提供了一种新的视角和方法,并实现了操作技能从仿真环境到真实装配环境的虚实迁移。
技术研发人员:孙富春,周怀东
受保护的技术使用者:清华大学
技术研发日:
技术公布日:2024/9/26
- 还没有人留言评论。精彩留言会获得点赞!