一种基于解耦模块挖掘的文本风格迁移方法与流程
本发明涉及文本处理,尤其涉及一种基于解耦模块挖掘的文本风格迁移方法。
背景技术:
1、文本风格迁移是自然语言生成领域中一个关键任务,旨在保留句子核心内容语义的同时改变其风格属性,这包括但不限于情感,礼貌,格式。此任务不仅能够用于中和攻击性言论,还对无监督摘要、翻译乃至语音识别等多种下游任务有益。
2、由于缺乏平行数据作为监督信息,现有主流方法采用无监督方式进行设计。这些方法在transformer架构中引入了额外的风格嵌入,并构建至少三种复杂的损失来制造监督性,如循环一致性损失、自我重构损失以及风格损失。然而,由于缺少作为监督信息的平行数据,转换的过程往往具有高语义发散性,导致迁移质量不佳,具体体现在转换句子的语义保存度不足和风格不精确。
技术实现思路
1、基于背景技术存在的技术问题,本发明提出了一种基于解耦模块挖掘的文本风格迁移方法,实现了高风格准确度与高语义保存度的文本风格迁移。
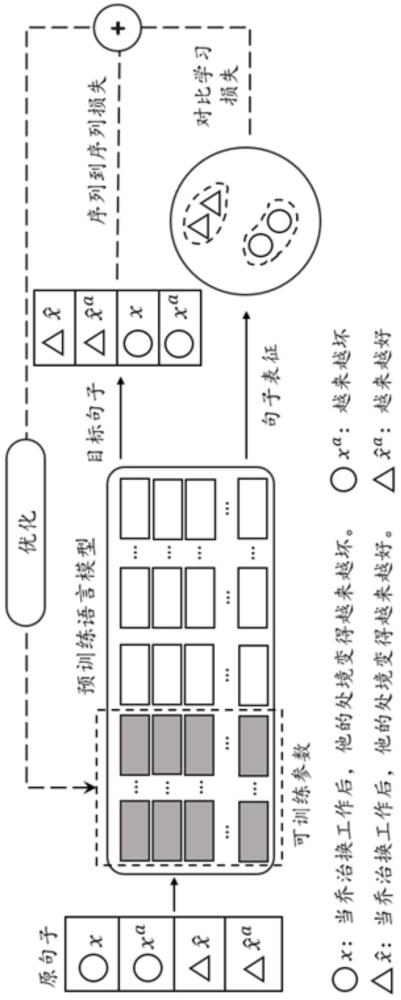
2、本发明提出的一种基于解耦模块挖掘的文本风格迁移方法,将给定任意句子与目标风格输入到预训练语言模型中,在保持输入句子内容不变的同时以产生含有目标风格属性的句子;
3、所述预训练语言模型将前缀token作为一种虚拟token拼接在输入的句子之前,并通过一个可训练的矩阵,将前缀token映射为每一层的前缀embedding,则矩阵是唯一训练的前缀参数,使得在冻结预训练语言模型参数的同时仅训练调整连续的前缀参数,所述前缀token表示前缀令牌,所述前缀embedding表示前缀嵌入向量;
4、所述预训练语言模型的训练过程如下:
5、步骤一、获取多个原始句子,基于解耦大模型对每个原始句子进行解耦以挖掘该原始句子对应的原始属性模块,将原始句子分为原始属性模块和内容模块,所述内容模块为原始句子中去掉原始属性模块的部分;
6、步骤二、原始句子在保留内容模块的同时将原始属性模块修改为目标属性模块,以转换原始句子的风格,得到合成平行句子;
7、步骤三、利用bleu分数来衡量合成平行句子的语义保存程度,从而过滤低语义保存度的合成平行句子,获得多组高质量平行数据及其解耦模块集合,将集合作为训练集以训练预训练语言模型,所述表示第个原始句子,表示第个原始句子对应的原始属性模块,表示第个原始句子对应的合成平行句子,表示第个原始属性模块对应的目标属性模块,是合成平行句子的数量,所述bleu分数表示原始句子与合成平行句子之间的相似度得分;
8、步骤四、将训练集中的原始句子和原始属性模块作为一组正例对,将原始句子和合成平行句子作为一组负例对,以原始句子和目标属性模块作为一组负例对;取训练集中每个句子的表征为,基于对比学习训练预训练语言模型,以优化前缀参数,所述表征包括原始句子、原始属性模块、合成平行句子以及目标属性模块对应的表征;
9、步骤五、预训练语言模型在训练过程中,基于原始句子与合成平行句子,利用序列到序列损失在对数似然目标上进行梯度更新,以优化前缀参数。
10、进一步地,在利用bleu分数来衡量合成平行句子的语义保存程度中,具体为:
11、假设要采样组合成平行句子,并且是组合成平行句子的最大长度;
12、首先将组根据其长度分为组,其中第组包含了个长度为的合成平行句子,;
13、对于第组合成平行句子,采样最高bleu分数数量为的组内样本,根据合成平行句子长度采样的方式确保解耦大模型能够学习在不同句子长度下具有高语义保存的转换模式。
14、进一步地,在步骤四中,基于对比学习训练预训练语言模型,以优化前缀参数,具体为:
15、
16、其中,表示对比学习损失,表示温度系数,表示由作为正例的原始属性模块组成正例句子集合,表示正例句子集合中的正例句子,表示由作为负例的合成平行句子以及作为负例的目标属性模块组成的负例句子集合,表示原始句子的表征,表示正例句子的表征,表示句子的表征,表示正例句子集合和负例句子集合中的任意一个句子。
17、进一步地,在步骤五中,基于序列到序列损失在对数似然目标上进行梯度更新,以优化前缀参数,具体包括:
18、
19、其中,表示序列到序列损失,表示合成平行句子的长度,表示合成平行句子中第个字,表示合成平行句子中的前个字,表示原始句子,表示根据原始句子与合成平行句子前个字来生成合成平行句子第个字的概率。
20、进一步地,预训练语言模型的总损失为:
21、
22、表示预训练语言模型的总损失,表示平衡参数,用于平衡对比学习损失和序列到序列损失。
23、本发明提供的一种基于解耦模块挖掘的文本风格迁移方法的优点在于:本发明结构中提供的一种基于解耦模块挖掘的文本风格迁移方法,包括了解耦数据合成范式与解耦学习方法,在解耦数据合成范式中,运用解耦思想来设计思维链prompt,以此指引解耦大模型在保存原始文本语义的同时进行文本风格的转换,从而合成了文本风格迁移领域稀缺的高质量平行数据;解耦学习方法中,设计了两种损失()分别从两个重要方面解决文本风格迁移问题。其中对比学习损失可以提高文本风格迁移模型对句子属性特征的关注度,从而有利于风格迁移过程中的风格准确性。序列到序列损失可以约束输出的语义空间并且充分利用预训练语言模型内部的知识,从而有利于风格迁移过程中的语义保存。
技术特征:
1.一种基于解耦模块挖掘的文本风格迁移方法,其特征在于,将给定任意句子与目标风格输入到预训练语言模型中,在保持输入句子内容不变的同时以产生含有目标风格属性的句子;
2.根据权利要求1所述的基于解耦模块挖掘的文本风格迁移方法,其特征在于,在利用bleu分数来衡量合成平行句子的语义保存程度中,具体为:
3.根据权利要求1所述的基于解耦模块挖掘的文本风格迁移方法,其特征在于,在步骤四中,基于对比学习训练预训练语言模型,以优化前缀参数,具体为:
4.根据权利要求3所述的基于解耦模块挖掘的文本风格迁移方法,其特征在于,在步骤五中,基于序列到序列损失在对数似然目标上进行梯度更新,以优化前缀参数,具体包括:
5.根据权利要求4所述的基于解耦模块挖掘的文本风格迁移方法,其特征在于,预训练语言模型的总损失为:
技术总结
本发明公开了一种基于解耦模块挖掘的文本风格迁移方法,将给定任意句子与目标风格输入到预训练语言模型中,在保持输入句子内容不变的同时以产生含有目标风格属性的句子;所述预训练语言模型将前缀token作为一种虚拟token拼接在输入的句子之前,并通过一个可训练的矩阵,将前缀token映射为每一层的前缀embedding,则矩阵是唯一可以训练的前缀参数,使得在冻结预训练语言模型参数的同时仅训练调整连续的前缀参数;该文本风格迁移方法实现了高风格准确度与高语义保存度的文本风格迁移。
技术研发人员:张勇东,毛震东,胡博,韩靖轩
受保护的技术使用者:合肥综合性国家科学中心人工智能研究院(安徽省人工智能实验室)
技术研发日:
技术公布日:2024/7/25
- 还没有人留言评论。精彩留言会获得点赞!