基于多尺度特征的表情识别方法、装置及设备
本发明涉及表情识别,具体地,涉及一种基于多尺度特征的表情识别方法、装置及设备。
背景技术:
1、随着面部表情识别技术的应用不断增多,研究人员发现在面部表情识别技术中的困难和挑战不断增多。首先,在早期研究阶段,大多数的面部表情识别模型都是基于实验室可控环境下所采集到的表情数据集进行开发的,然而,在自然环境中,这些模型的适用性并不是很强。并且,在自然条件下,人脸表情图像中特征的情况较为复杂,导致传统方法提取出的表情特征中均存在一定的噪声,识别效果不理想,因此,如何解决表情识别模型在各种复杂场景下的适用性,成为了亟待解决的问题。
技术实现思路
1、为了解决现有技术中存在的上述问题,本发明提供了一种基于多尺度特征的表情识别方法、装置及设备。
2、根据本发明实施例的第一方面,提供一种基于多尺度特征的表情识别方法,所述方法包括:
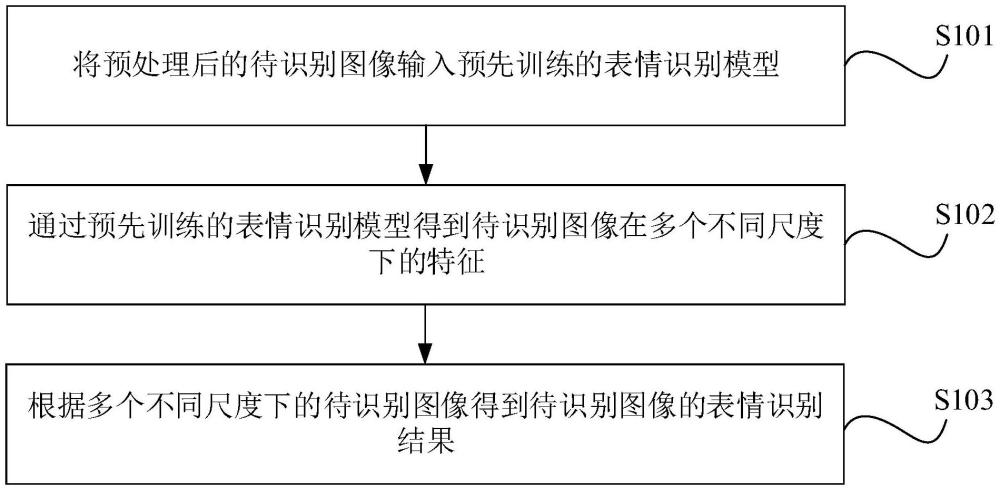
3、将预处理后的待识别图像输入预先训练的表情识别模型;
4、通过预先训练的所述表情识别模型得到所述待识别图像在多个不同尺度下的特征;
5、根据多个不同尺度下的所述待识别图像得到所述待识别图像的表情识别结果。
6、可选地,所述表情识别模型还包括残差自注意力模块;在所述将预处理后的待识别图像输入预先训练的表情识别模型之前,所述方法还包括:
7、对训练集中的原始图像添加噪声,得到加噪图像;
8、根据所述原始图像、所述加噪图像和所述残差自注意力模块,得到所述原始图像对应的第一注意力输出和所述加噪图像对应的第二注意力输出;
9、根据所述第一注意力输出和所述第二注意力输出得到所述原始图像对应的第一识别结果和所述加噪图像对应的第二识别结果;
10、根据所述第一注意力输出和所述第二注意力输出之间的对比损失得到第一损失;
11、根据所述第一识别结果与所述原始图像对应的真实识别结果之间的损失得到第二损失;
12、根据所述第一损失和所述第二损失调整所述表情识别模型的参数直至达到预设训练截至条件,得到预先训练的所述表情识别模型。
13、可选地,所述表情识别模型还包括多尺度特征提取模块;所述根据所述原始图像、所述加噪图像和所述残差自注意力模块,得到所述原始图像对应的第一注意力输出和所述加噪图像对应的第二注意力输出,包括:
14、利用所述多尺度特征提取模块提取所述原始图像的多个不同尺度的第一特征以及所述加噪图像的多个不同尺度的第二特征;其中,所述第一特征和所述第二特征的多个不同尺度一一对应;
15、将所述第一特征和所述第二特征输入所述残差自注意力模块,得到所述第一特征对应的第一注意力输出和所述第二特征对应的第二注意力输出。
16、可选地,所述将所述第一特征和所述第二特征输入所述残差自注意力模块,得到所述第一特征对应的第一注意力输出和所述第二特征对应的第二注意力输出,包括:
17、对所述第一特征和所述第二特征进行处理,得到处理后的所述第一特征和处理后的所述第二特征;
18、将处理后的所述第一特征映射为第一查询向量、第一键向量和第一值向量,并将处理后的所述第二特征映射为第二查询向量、第二键向量和第二值向量;
19、计算所述第一查询向量和第一键向量的第一相似度,并将所述第一相似度进行归一化处理,作为第一权重;
20、将所述第一权重与所述第一值向量加权求和,得到所述第一注意力输出;
21、计算所述第二查询向量和第二键向量的第二相似度,并将所述第二相似度进行归二化处理,作为第二权重;
22、将所述第二权重与所述第二值向量加权求和,得到所述第二注意力输出。
23、可选地,所述对所述第一特征和所述第二特征进行处理,得到处理后的所述第一特征和处理后的所述第二特征,包括:
24、根据设定窗口对所述第一特征和所述第二特征分别进行分割,得到对应的多个第一向量和多个第二向量;
25、对所述多个第一向量进行特征映射,得到处理后的所述第一特征;
26、对所述多个第二向量进行特征映射,得到处理后的所述第二特征。
27、可选地,所述表情识别模型还包括多尺度特征融合模块;在所述将所述第一权重与所述第一值向量加权求和,得到所述第一注意力输出之后,所述方法还包括:
28、利用所述设定窗口对所述第一注意力输出进行处理,得到新第一特征;
29、在多个不同尺度下,将尺度相同的新第一特征和第一特征相加,得到多个不同尺度下的特征图;
30、利用所述多尺度特征融合模块将所述多个不同尺度下的特征图融合,得到融合特征。
31、可选地,所述表情识别模型还包括分类模块,在所述利用所述多尺度特征融合模块将所述多个不同尺度下的特征图融合,得到融合特征之后,所述方法还包括:
32、将所述融合特征输入所述分类模块,通过线性映射将所述融合特征转换为二维的融合特征;
33、利用所述分类模块中的全连接神经网络得到所述第一识别结果。
34、可选地,在对训练集中的原始图像添加噪声,得到加噪图像之前,所述方法还包括:
35、获取表情识别数据集;
36、根据所述表情识别数据集获取所述训练集和测试集;
37、将所述训练集和所述测试集的图像尺寸调整一致;
38、利用所述测试集测试所述表情识别模型是否达到所述预设训练截至条件。
39、根据本发明实施例的第二方面,提供一种基于多尺度特征的表情识别装置,所述装置包括:
40、输入模块,用于将预处理后的待识别图像输入预先训练的表情识别模型;
41、多尺度特征获取模块,用于通过预先训练的表情识别模型得到所述待识别图像在多个不同尺度下的特征;
42、结果获取模块,用于根据多个不同尺度下的所述待识别图像得到所述待识别图像的表情识别结果。
43、根据本公开实施例的第三方面,提供一种基于多尺度特征的表情识别装置,包括:处理器;用于存储处理器可执行指令的存储器;
44、其中,所述处理器被配置为:执行所述可执行指令以实现上述第一方面中的任一实施方式所述的基于多尺度特征的表情识别方法的步骤。
45、本发明提供的技术方案可以包括以下有益效果:
46、通过上述技术方案,通过在表情识别模型获取待识别图像的多尺度特征,使模型能够提取到更具判别性、泛化性的特征,由于不同尺度的特征网络所关注的位置与范围都不同,因此本发明中的表情识别模型还可以根据不同尺度下的特征进行表情识别,能够在各种复杂环境中使用,具有较好的适应性和较好的识别结果。
技术特征:
1.一种基于多尺度特征的表情识别方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于多尺度特征的表情识别方法,其特征在于,所述表情识别模型包括残差自注意力模块;在所述将预处理后的待识别图像输入预先训练的表情识别模型之前,所述方法还包括:
3.根据权利要求2所述的基于多尺度特征的表情识别方法,其特征在于,所述表情识别模型还包括多尺度特征提取模块;所述根据所述原始图像、所述加噪图像和所述残差自注意力模块,得到所述原始图像对应的第一注意力输出和所述加噪图像对应的第二注意力输出,包括:
4.根据权利要求3所述的基于多尺度特征的表情识别方法,其特征在于,所述将所述第一特征和所述第二特征输入所述残差自注意力模块,得到所述第一特征对应的第一注意力输出和所述第二特征对应的第二注意力输出,包括:
5.根据权利要求4所述的基于多尺度特征的表情识别方法,其特征在于,所述对所述第一特征和所述第二特征进行处理,得到处理后的所述第一特征和处理后的所述第二特征,包括:
6.根据权利要求5所述的基于多尺度特征的表情识别方法,其特征在于,所述表情识别模型还包括多尺度特征融合模块;在所述将所述第一权重与所述第一值向量加权求和,得到所述第一注意力输出之后,所述方法还包括:
7.根据权利要求6所述的基于多尺度特征的表情识别方法,其特征在于,所述表情识别模型还包括分类模块,在所述利用所述多尺度特征融合模块将所述多个不同尺度下的特征图融合,得到融合特征之后,所述方法还包括:
8.根据权利要求2所述的基于多尺度特征的表情识别方法,其特征在于,在对训练集中的原始图像添加噪声,得到加噪图像之前,所述方法还包括:
9.一种基于多尺度特征的表情识别装置,其特征在于,所述装置包括:
10.一种电子设备,其特征在于,包括:
技术总结
本发明涉及一种基于多尺度特征的表情识别方法、装置及设备,该方法包括:将预处理后的待识别图像输入预先训练的表情识别模型;通过预先训练的表情识别模型得到待识别图像在多个不同尺度下的特征;根据多个不同尺度下的待识别图像得到待识别图像的表情识别结果。通过上述技术方案,通过在表情识别模型获取待识别图像的多尺度特征,使模型能够提取到更具判别性、泛化性的特征,由于不同尺度的特征网络所关注的位置与范围都不同,因此本发明中的表情识别模型还可以根据不同尺度下的特征进行表情识别,能够在各种复杂环境中使用,具有较好的适应性和较好的识别结果。
技术研发人员:田小林,程杰,陶硕,焦李成
受保护的技术使用者:西安电子科技大学
技术研发日:
技术公布日:2024/9/26
- 还没有人留言评论。精彩留言会获得点赞!