一种多文档场景下的问答方法、装置、介质和设备与流程
本申请涉及自然语言处理,特别涉及一种多文档场景下的问答方法、装置、介质和设备。
背景技术:
1、文档问答系统是指从大规模文档数据中查找到与用户问题相关答案的一套完整的系统。系统会接收文本输入的问题,并在给定文档集合的情况下,自动提取信息并生成对应的答案。
2、现有技术中,在多文档场景下进行问答的一般步骤为:收集包含相关信息的多个文档;根据用户的问题,使用自然语言处理技术从多个文档中提取相关的查询片段或关键词;基于提取的查询片段或关键词对文档进行排序,从排名前的文档中抽取出可能的答案。
3、但是,传统通用问答模型可能对于某个专业领域问题的回答并不与该专业领域相关,存在缺乏依据、存在幻觉等问题,无法满足用户在不同专业领域应用场景上的特定需求,不具有灵活性。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种多文档场景下的问答方法、装置、介质和设备。
2、本说明书采用下述技术方案:
3、本说明书提供了一种多文档场景下的问答方法,包括:
4、获取不同专业领域场景下的多文档;
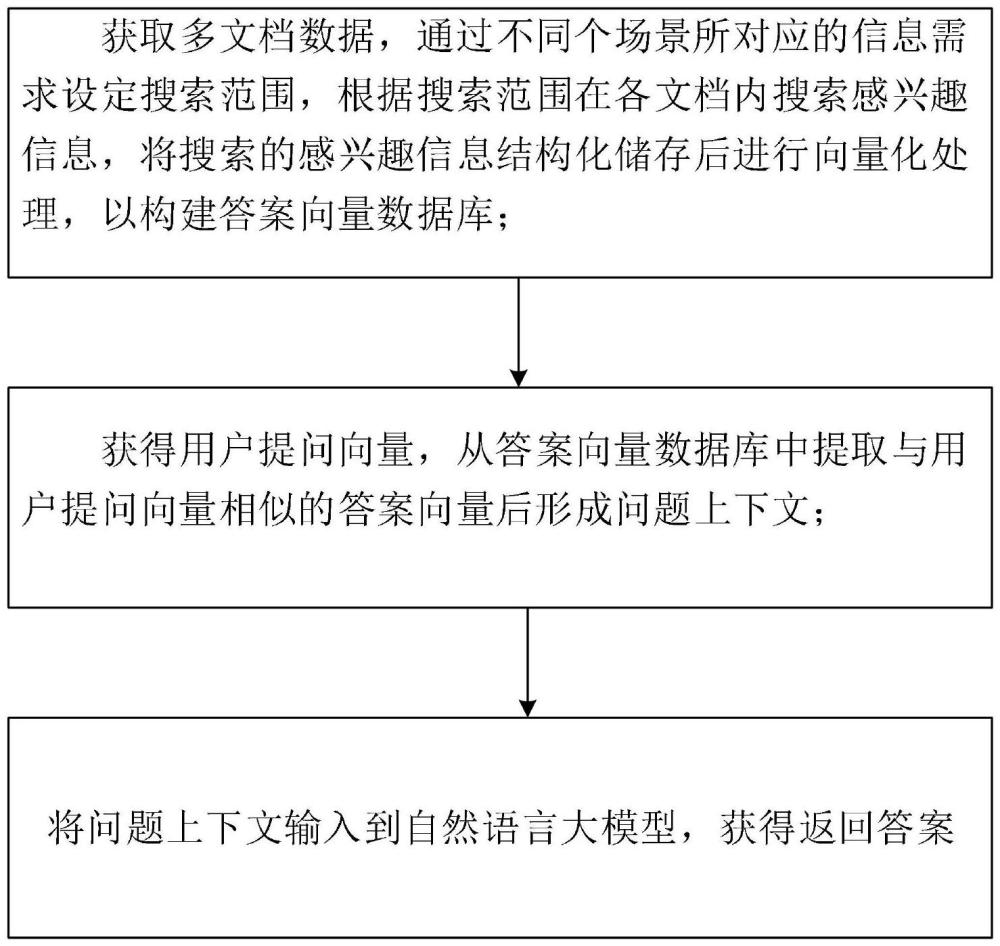
5、通过不同专业领域场景所对应的需求设定搜索范围,根据搜索范围在各文档内搜索与需求相匹配的感兴趣信息,将搜索的感兴趣信息结构化储存后进行向量化处理,以构建答案向量数据库;
6、获得用户提问向量,从答案向量数据库中提取与用户提问向量相似的答案向量后形成问题上下文;
7、将问题上下文输入到自然语言大模型,获得返回答案。
8、进一步地,所述将搜索的感兴趣信息结构化储存后进行向量化处理,以构建答案向量数据库,具体包括:
9、从去除乱码后的文档中搜索感兴趣信息,将搜索到的感兴趣信息结构化存储在本地json文件中;
10、使用embedding模型对存储在本地json文件中的感兴趣信息数据进行向量转化,将转换后的向量数据写入到pinecone向量库,以获得答案向量数据库。
11、进一步地,所述从答案向量数据库中提取与用户提问向量相似的答案向量后形成问题上下文,具体包括:
12、基于余弦相似度,从答案向量数据库中提取与用户提问向量相似的答案向量数据,并进行返回;
13、取余弦相似度排序最小的n个答案向量数据与用户提问向量合,构建问题上下文promptnew:
14、promptnew={p|p=random(promptold,doc)}
15、其中,promptold是问题向量数据;doc是余弦相似度cosine最小的n个答案向量数据;random(*,*)是多文档场景下的问答的随机函数,首先把n个答案向量数据和问题向量数据组合成新的集合,然后通过随机抽取方法组合成新的集合;p是n个答案向量数据和问题向量数据组合成的新集合元素。
16、进一步地,所述自然语言大模型为gpt模型。
17、进一步地,在各文档内搜索感兴趣信息之前,对多文档数据进行预处理,具体包括:
18、设定单文档中出现乱码的阈值,当某个文档中出现乱码并且乱码比例大于所设定的阈值时,从文档集中删除该文档;当某个文档中出现乱码并且乱码比例小于所设定的阈值时,从文档集中去除该乱码而不删除该文档。
19、本说明书提供了一种多文档场景下的问答装置,包括:
20、数据获取模块,用于获取不同专业领域场景下的多文档;
21、答案向量数据库构建模块,用于通过不同专业领域场景所对应的需求设定搜索范围,根据搜索范围在各文档内搜索与需求相匹配的感兴趣信息,将搜索的感兴趣信息结构化储存后进行向量化处理,以构建答案向量数据库;
22、上下文获取模块,用于获得用户提问向量,从答案向量数据库中提取与用户提问向量相似的答案向量后形成问题上下文;
23、回答模块,用于将问题上下文输入到自然语言大模型,获得返回答案。
24、本说明书提供了一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述多文档场景下的问答方法。
25、本说明书提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述多文档场景下的问答方法。
26、本说明书采用的上述至少一个技术方案能够达到以下有益效果:
27、在本说明书提供的多文档场景下的问答方法中,根据不同专业领域所对应的专业信息需求设定搜索范围,可以确保获取的答案与专业领域相关,从而提供与问题更加对应的专业回答,避免了在专业领域回答缺乏依据、存在幻觉等问题。
28、另外,结构化储存和向量化处理可以让得到的感兴趣信息以一种标准化和机器友好的方式存储,使得不同领域的数据可以以统一的形式存在,问答模型能够快速地进行检索和匹配,更灵活地适应不同的查询需求和应用场景,可以满足用户在不同应用场景上的特定需求。
技术特征:
1.一种多文档场景下的问答方法,其特征在于,包括:
2.如权利要求1所述的多文档场景下的问答方法,其特征在于,所述将搜索的感兴趣信息结构化储存后进行向量化处理,以构建答案向量数据库,具体包括:
3.如权利要求1所述的多文档场景下的问答方法,其特征在于,所述从答案向量数据库中提取与用户提问向量相似的答案向量后形成问题上下文,具体包括:
4.如权利要求1所述的多文档场景下的问答方法,其特征在于,所述自然语言大模型为gpt模型。
5.如权利要求1所述的多文档场景下的问答方法,其特征在于,在各文档内搜索感兴趣信息之前,对多文档数据进行预处理,具体包括:
6.一种多文档场景下的问答装置,其特征在于,包括:
7.一种计算机可读存储介质,其特征在于,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述权利要求1~5任一项所述的方法。
8.一种计算机设备,其特征在于,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述权利要求1~5任一所述的方法。
技术总结
本发明公开了一种多文档场景下的问答方法、装置、介质和设备,涉及自然语言处理技术领域。包括:获取多文档数据,通过不同场景所对应的信息需求设定搜索范围,根据搜索范围在各文档内搜索感兴趣信息,将搜索的感兴趣信息结构化储存后进行向量化处理,以构建答案向量数据库;获得用户提问向量,从答案向量数据库中提取与用户提问向量相似的答案向量后形成问题上下文;将问题上下文输入到自然语言大模型,获得返回答案。根据不同场景的不同信息需求设定搜索范围,提供与问题更加对应的专业回答;结构化储存和向量化处理可以让感兴趣信息以机器友好的方式存储,问答模型能够快速地进行检索和匹配,更灵活地适应不同的查询需求和应用场景。
技术研发人员:李伟,王仕民,姚俊彦
受保护的技术使用者:江西省金控科技产业集团有限公司
技术研发日:
技术公布日:2024/11/4
- 还没有人留言评论。精彩留言会获得点赞!