基于双流Transformer的大规模手语数据高质量自动筛选方法
本发明属于数据挖掘,具体涉及一种基于双流transformer的大规模手语数据高质量自动筛选方法。
背景技术:
1、对于基于深度学习的手语识别翻译任务,手语数据质量规模是很重要的,尤其是训练数据的质量规模决定了手语识别翻译效果的上限,而模型和算法的改进只是在不断地逼近这个上限。目前,手语识别翻译研究所使用到的开源手语数据集均存在规模小、缺乏多样性等问题,而这些问题会导致手语识别翻译模型泛化能力不强,无法落地实用。因此,手语识别翻译研究急需大规模、多样性的手语数据来提升识别翻译模型的性能和泛化能力。而在构建海量、复杂的手语数据过程中,不可避免地会采集到错误数据,例如手语顺序错误、手势错误和手语遗漏等情况。错误数据会让模型学习到错误的映射关系,导致手语识别翻译效果的降低。如果使用人工对大规模手语数据集进行检查,则是严重消耗人力成本和时间成本。
2、综上,本发明基于计算机视觉中的深度学习技术,提出一种基于双流transformer的大规模手语数据高质量自动筛选方法,能够自动筛选错误手语数据,在构建大规模手语数据集过程中提升了数据质量,为手语识别翻译模型建立正确的映射关系提供了数据基础,有助于构建泛化能力强和性能更好的手语识别翻译模型。
技术实现思路
1、针对现有技术的不足,本发明拟解决的技术问题是,提供一种基于双流transformer的大规模手语数据高质量自动筛选方法。
2、本发明解决所述技术问题采用的技术方案是:
3、一种基于双流transformer的大规模手语数据高质量自动筛选方法,其特征在于,该方法包括以下步骤:
4、第一步:获取若干个视频对作为数据集,视频对由同一个手语动作的标准手语视频和被筛选手语视频组成,标准手语视频不包含错误数据,被筛选手语视频与标准手语视频需保证在相同视角下采集;使用mediapipe库分别对标准手语视频和被筛选手语视频进行手势识别,得到标准手语骨骼视频和被筛选手语骨骼视频;
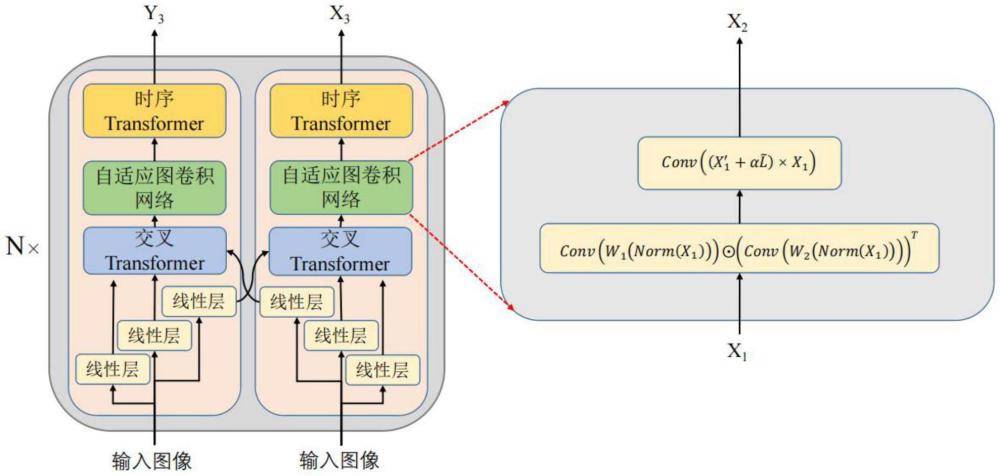
5、第二步:构建手语筛选模型;手语筛选模型包括多个顺序连接的特征提取模块,最后一个特征提取模块的输出特征经过一个多层感知机映射为两类,正类代表被筛选手语视频质量合格,负类代表被筛选手语视频质量不合格;
6、手语筛选模型的输入是由标准手语骨骼视频和被筛选手语骨骼视频组成的视频对,每个特征提取模块包括结构相同的两个分支,每个分支包括顺序连接的交叉transformer、自适应图卷积网络和时序tranformer,交叉transformer的输出特征和骨骼图的邻接矩阵输入到自适应图卷积网络中进行特征提取,自适应图卷积网络的输出特征输入到时序tranformer,自适应图卷积网的输出特征x2表示为:
7、
8、x′1=conv(w1(norm(x1)))⊙(conv(w2(norm(x1))))t
9、式中,conv(·)表示卷积操作,α是权重因子;是对称归一化的拉普拉斯矩阵,根据骨骼图得到;x1是交叉transformer的输出特征,norm(·)表示归一化操作,w1、w2表示线性变换,⊙表示点积;
10、第三步:对手语筛选模型进行训练,根据训练后的手语筛选模型对被筛选手语视频进行筛选。
11、与现有技术相比,本发明的有益效果主要表现在:
12、为了实现错误数据的筛选,本发明以正确手语视频数据作为标准,将被筛选手语视频与标准手语视频进行对比,判断视频对的类别,进而反映被筛选手语视频质量是否合格,因此基于transformer网络构建双流形式的手语筛选模型。采用交叉transformer关注到两个视频之间手语动作的共性而不会被手语者个体之间的不同手语风格而影响,自适应图卷积网络能够加强骨骼特征提取能力,提取到丰富的特征信息,时序transformer可以很好的关注到时间序列上的重要帧,从而使模型更加适用于大规模手语数据高质量自动筛选,解决了手语数据质量低下的问题,进而优化了手语识别翻译模型的训练速度,提升了手语识别翻译效果。
技术特征:
1.一种基于双流transformer的大规模手语数据高质量自动筛选方法,其特征在于,该方法包括以下步骤:
2.根据权利要求1所述的基于双流transformer的大规模手语数据高质量自动筛选方法,其特征在于,所述交叉transformer的输入分别通过三个线性层转换为查询向量、键向量和值向量,第一个分支的交叉transformer的查询向量作为第二个分支的交叉transformer的查询向量,第二个分支的交叉transformer的查询向量作为第一个分支的交叉transformer的查询向量,则交叉transformer的输出特征x1表示为:
3.根据权利要求1或2所述的基于双流transformer的大规模手语数据高质量自动筛选方法,其特征在于,时序transformer的输入特征分别通过三个线性层转换成查询向量q、键向量k和值向量v,则时序transformer的输出特征x3表示为:
4.根据权利要求1所述的基于双流transformer的大规模手语数据高质量自动筛选方法,其特征在于,对称归一化的拉普拉斯矩阵表示为:
5.根据权利要求1所述的基于双流transformer的大规模手语数据高质量自动筛选方法,其特征在于,所述手语筛选模型包含四个特征提取模块。
技术总结
本发明公开了一种基于双流Transformer的大规模手语数据高质量自动筛选方法,首先获取同一个手语动作的标准手语视频和被筛选手语视频,标准手语视频不包含错误数据,且被筛选手语视频与标准手语视频需保证在相同视角下采集;使用MediaPipe库分别对标准手语视频和被筛选手语视频进行手势识别,得到标准手语骨骼视频和被筛选手语骨骼视频;然后,构建包含多个顺序连接的特征提取模块的手语筛选模型,最后一个特征提取模块的输出特征经过一个多层感知机映射为两类,正类代表被筛选手语视频质量合格,负类代表被筛选手语视频质量不合格;对手语筛选模型进行训练,根据训练后的手语筛选模型对被筛选手语视频进行筛选。该方法以正确手语视频数据作为标准,将被筛选手语视频与标准手语视频进行对比,判断视频对的类别,进而反映被筛选手语视频质量是否合格,解决了手语数据质量低下的问题。
技术研发人员:袁甜甜,蔡佳良,薛翠红,杨学,朱宇
受保护的技术使用者:天津理工大学
技术研发日:
技术公布日:2024/10/31
- 还没有人留言评论。精彩留言会获得点赞!