一种基于强弱一致性的半监督对抗互训练语义分割方法
本发明涉及语义分割,具体涉及一种基于强弱一致性的半监督对抗互训练语义分割方法。
背景技术:
1、语义分割是计算机视觉领域内的一项基本视觉任务,旨在将图像中的像素分为不同的类别。近年来,深度神经网络再语义分割方面表现出了巨大的潜力。然而,深度神经网络的成功主要归功于大量的注释数据集。对于语义分割任务,通常需要像素级注释,这意味着标注人员需要手动标记每张图像的数十万像素。因此,收集精确标记的数据用于训练深度神经网络,需要极大的人工成本。此外,对于某些特定的语义类别,标注样本可能很难获得,导致模型的性能受限。
2、为了解决这些问题,半监督学习技术被引入到语义分割任务中,其目的是通过使用一小组像素级精确标注的数据和大量的无标签数据来学习网络模型。在半监督语义分割中,未标注的图像可以用来学习更丰富的表征,帮助模型理解更广泛的语义信息。但是来自于有标签数据的信息是十分有限的,因为标签数据的数量远远小于无标签数据的数量。因此如何充分无标签数据来辅助有标签数据进行模型训练就成为一个关键问题。
3、近年来,深度学习技术的快速发展为半监督语义分割带来了新的机遇。通过将深度卷积神经网络(cnn)用于语义分割任务,研究人员取得了显著的进展。然而,现有的半监督语义分割方法仍然存在一些挑战,如对未标注数据的合理利用、标记样本的不平衡分布、双分支网络中分支同化导致模型崩溃等。
技术实现思路
1、发明目的:本发明的目的是提供一种基于强弱一致性的半监督对抗互训练语义分割方法,解决双分支网络中分支同化导致模型崩溃的问题。
2、技术方案:本发明所述的一种基于强弱一致性的半监督对抗互训练语义分割方法,包括以下步骤:
3、s1获取开源网站pascal voc2012数据集体并进行预处理;
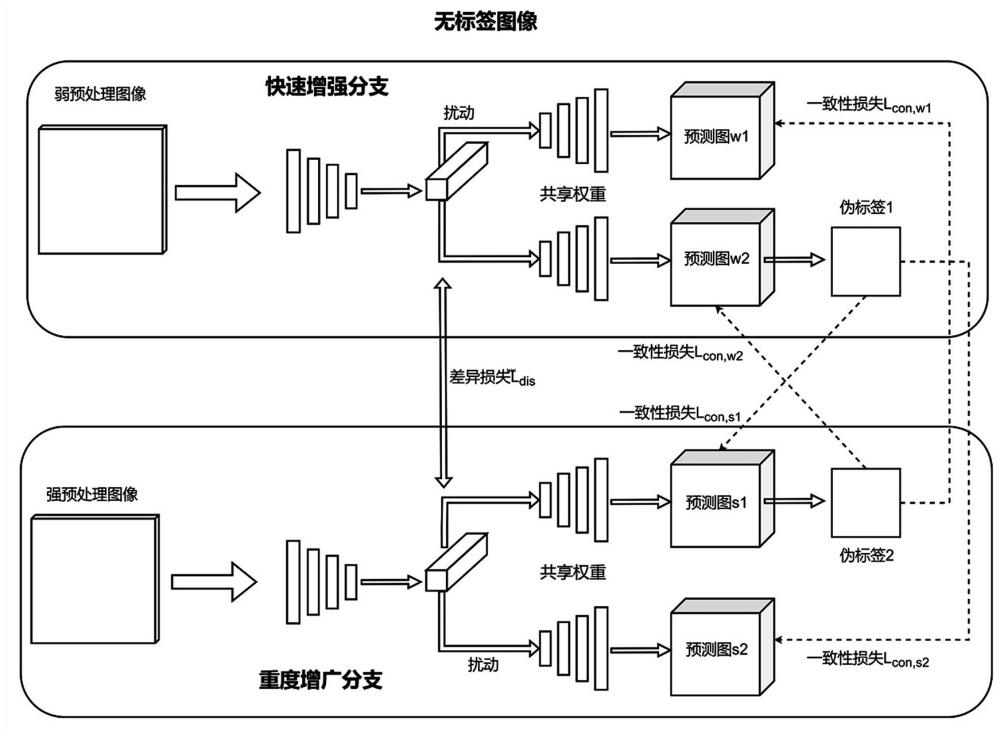
4、s2构建基于改进的deeplabv3+差异特征一致性融合伪标签分支监督分割网络并进行训练,包括:快速增强网络和重度增广网络;
5、s3输出分割图。
6、进一步的,步骤s1中,pascal voc2012数据集1464张用于训练的全标注图像,1449张用于验证的图像和1456张用于测试的图像;其中,将1464张随机划分为有标签图像和无标签图像;预处理具体如下:将训练图像进行随机缩放、裁剪、水平翻转后作为快速增强网络的输入;将经过随机缩放、裁剪、水平翻转的图像利用色彩抖动transforms.colorjitter随机调整图像的亮度、对比度、饱和度和色相;利用随机灰度化transforms.randomgrayscale随机将图像转换成灰度图像后再进行随机的模糊变换作为重度增广网络的输入;即得到一组完全按像素标注的图像和一组未标注的图像;其中,m和n表示标记图像和未标记图像的数量,其中,,;其中,c表示通道;h表示高度;w表示宽度;是每个像素one-hot标签,其中,y 表示分割类别的数目。
7、进一步的,步骤s2中,快速增强网络和重度增广网络包括:特征差异提取模块、特征解码模块、伪标签合成模块、交叉监督模块;其中,特征差异提取模块用于进行图像的特征提取;特征解码模块用于在快速增强网络和重度增广网络中分别进行扰动特征和无扰动特征,其中,无扰动特征采用图像扰动和特征扰动dropout构成的双路扰动进行;然后输入到快速增强网络和重度增广网络两个共享权重的解码器上进行解码分别得到快速增强网络两张预测图和重度增广网络两张预测图;伪标签合成模块采用邻近像素预测生成伪标签;其中,快速增强网络和重度增广网络分别生成第一伪标签和第二伪标签;交叉监督模块用于将快速增强网络中不进行扰动的预测图合成伪标签,然后利用伪标签监督重度增广网络预测图的训练。
8、进一步的,特征差异提取模块具体如下:设快速增强网络和重度增广网络的特征提取器为ψf和分类器为ψcls,将视图经过特征提取器ψf的特征表示为fα;对于和,分别将预处理后的图像视图输入到快速增强网络和重度增广网络中,经过两个子网的特征提取器后得到两个特征表示和;使用差异损失最小化两个特征表示和之间的余弦相似度,公式表示为:
9、;
10、其中, 表示标签数据和无标签数据,表示快速增强分支提取的特征信息,为重度增广分支提取信息。
11、进一步的,在特征解码模块中,将无扰动特征经过分类器ψcls后的预测记为,将加入dropout扰动的特征经过分类器ψcls后的预测记为,则监督损失表示为:
12、;
13、其中,l表示属于标签图像,为标签图像监督训练损失,m表示标签图像的数量,w和h表示图像的宽、高,为交叉熵损失,为第m张标签图像的第n个像素,w和s分别为快速增强网络和重度增广网络,为快速增强分支的无扰动预测,为快速增强分支的扰动预测;分别表示重度增广网络的无扰动和扰动预测,为真实标签。
14、进一步的,伪标签合成模块公式如下:设给定一个预测中的一个像素和相应的每个类别预测,检查其周围n×n像素邻域内的邻域像素,计算和属于同一类c的联合概率,然后计算两个像素中至少有一个属于类别c的概率,公式如下:
15、;
16、其中,表示快速增强网络和重度增广网络,为预测的第j行,k列的像素点,为像素的邻域像素点;分别表示像素、对于类别c的预测概率;
17、对于每个类c,选择最大信息熵的邻居,公式如下:
18、;
19、其中,max表示最大值筛选,表示在所有3*3邻域的像素点中寻找的最大值。
20、进一步的, 交叉监督模块公式如下:
21、;
22、其中,表示快速增强网络和重度增广网络,表示分支i的无监督一致性损失。表示分支i的预测和标签冲突的高置信度一致性损失,为其他情况下分支i的无标签一致性损失。为高置信度冲突情况下一致性损失的权重;公式如下:
23、;
24、公式如下:
25、;
26、其中,n为无标签图像的数量,w和h为图像的宽高,为分支i的第m张图像的第n个像素预测,为第(3-i)分支生成的伪标签的第m张图像第n个像素标签;表示在预测和标签冲突的情况下且置信度高于阈值时为1,表示除高置信度冲突的其他情况。
27、进一步的,在模型训练中,总损失函数由监督损失、一致性损失和特征差异损失构成,公式如下:
28、;
29、其中,为总损失函数,表示监督损失,为无标签一致性损失,为特征差异损失,是三个损失函数的调整权重。
30、有益效果:与现有技术相比,本发明具有如下显著优点:使用互训练的思想构建了一个基于强弱一致性的对抗联合训练架构方法,用于半监督语义分割,不仅拥有很好的端对端训练,而且在训练中使用了互训练的方法,两个分支相互监督避免了确认偏差的影响,且特征对抗的思想更是强制让模型拥有更强的泛化能力,强弱一致性也让模型能够在图像包含较少有效信息的情况下有很好的性能。
技术特征:
1.一种基于强弱一致性的半监督对抗互训练语义分割方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于强弱一致性的半监督对抗互训练语义分割方法,其特征在于,步骤s1中,pascal voc2012数据集1464张用于训练的全标注图像,1449张用于验证的图像和1456张用于测试的图像;其中,将1464张随机划分为有标签图像和无标签图像;预处理具体如下:将训练图像进行随机缩放、裁剪、水平翻转后作为快速增强网络的输入;将经过随机缩放、裁剪、水平翻转的图像利用色彩抖动transforms.colorjitter随机调整图像的亮度、对比度、饱和度和色相;利用随机灰度化transforms.randomgrayscale随机将图像转换成灰度图像后再进行随机的模糊变换作为重度增广网络的输入;即得到一组完全按像素标注的图像和一组未标注的图像;其中,m和n表示标记图像和未标记图像的数量,其中,,;其中,c表示通道;h表示高度;w表示宽度;是每个像素one-hot标签,其中,y 表示分割类别的数目。
3.根据权利要求1所述的一种基于强弱一致性的半监督对抗互训练语义分割方法,其特征在于,步骤s2中,快速增强网络和重度增广网络包括:特征差异提取模块、特征解码模块、伪标签合成模块、交叉监督模块;其中,特征差异提取模块用于进行图像的特征提取;特征解码模块用于在快速增强网络和重度增广网络中分别进行扰动特征和无扰动特征,其中,无扰动特征采用图像扰动和特征扰动dropout构成的双路扰动进行;然后输入到快速增强网络和重度增广网络两个共享权重的解码器上进行解码分别得到快速增强网络两张预测图和重度增广网络两张预测图;伪标签合成模块采用邻近像素预测生成伪标签;其中,快速增强网络和重度增广网络分别生成第一伪标签和第二伪标签;交叉监督模块用于将快速增强网络中不进行扰动的预测图合成伪标签,然后利用伪标签监督重度增广网络预测图的训练。
4.根据权利要求3所述的一种基于强弱一致性的半监督对抗互训练语义分割方法,其特征在于,特征差异提取模块具体如下:设快速增强网络和重度增广网络的特征提取器为ψf和分类器为ψcls,将视图经过特征提取器ψf的特征表示为fα;对于和,分别将预处理后的图像视图输入到快速增强网络和重度增广网络中,经过两个子网的特征提取器后得到两个特征表示和;使用差异损失最小化两个特征表示和之间的余弦相似度,公式表示为:
5.根据权利要求3所述的一种基于强弱一致性的半监督对抗互训练语义分割方法,其特征在于,在特征解码模块中,将无扰动特征经过分类器ψcls后的预测记为,将加入dropout扰动的特征经过分类器ψcls后的预测记为,则监督损失表示为:
6.根据权利要求3所述的一种基于强弱一致性的半监督对抗互训练语义分割方法,其特征在于,伪标签合成模块公式如下:设给定一个预测中的一个像素和相应的每个类别预测,检查其周围n×n像素邻域内的邻域像素,计算和属于同一类c的联合概率,然后计算两个像素中至少有一个属于类别c的概率,公式如下:
7.根据权利要求3所述的一种基于强弱一致性的半监督对抗互训练语义分割方法,其特征在于, 交叉监督模块公式如下:
8.根据权利要求3所述的一种基于强弱一致性的半监督对抗互训练语义分割方法,其特征在于,在模型训练中,总损失函数由监督损失、一致性损失和特征差异损失构成,公式如下:
技术总结
本发明公开了一种基于强弱一致性的半监督对抗互训练语义分割方法,包括以下步骤:(1)获取开源网站Pascal VOC2012数据集体并进行预处理;(2)构建基于改进的deeplabV3+差异特征一致性融合伪标签分支监督分割网络并进行训练,包括:快速增强网络和重度增广网络;(3)输出分割图;本发明使用互训练的思想构建了一个基于强弱一致性的对抗联合训练架构方法,用于半监督语义分割,不仅拥有很好的端对端训练,而且在训练中使用了互训练的方法,两个分支相互监督避免了确认偏差的影响,且特征对抗的思想更是强制让模型拥有更强的泛化能力,强弱一致性也让模型能够在图像包含较少有效信息的情况下有很好的性能。
技术研发人员:陈亚当,李家戚,卢楚翰
受保护的技术使用者:南京信息工程大学
技术研发日:
技术公布日:2024/8/15
- 还没有人留言评论。精彩留言会获得点赞!