一种基于大模型的境外诈骗短信识别方法与流程
本发明涉及数据处理,具体涉及一种基于大模型的境外诈骗短信识别方法。
背景技术:
1、自2023年初以来,随着预训练大模型chatgpt的问世,展现出在自然语言处理方面的卓越能力。本文利用大数据、大模型等技术,针对各种场景建立了垃圾短信智能防御、治理和阻断体系,能够快速、精准、智能地拦截诈骗短信。
2、传统领域针对诈骗短信的识别方法主要有两类:基于规则的方法和基于机器学习的方法。基于规则的方法是根据预先定义的变体字对应关系表进行替换。基于机器学习的方法是利用神经网络等模型进行变体字识别和还原。
3、基于规则的诈骗短信的识别方法是根据预先定义的变体字对应关系表进行替换,优点是简单快速,缺点是需要人工维护变体字表,无法覆盖所有可能的变体字,并且容易出现误替换的情况。基于机器学习的诈骗短信的识别方法是利用神经网络等模型进行变体字识别和还原,优点是可以自动学习变体字规律,缺点是需要大量的标注数据进行训练,而且模型的表示能力和生成能力有限,无法处理复杂和多样的变体字。
技术实现思路
1、本发明的目的是提供一种基于大模型的境外诈骗短信识别方法,该方法借助chatgpt为代表的大模型技术具备强大的语义识别、情感与意图分析能力,借助大模型微调技术,将诈骗短信特征学习与大模型的自然语义理解能力相结合,提出一种反诈识别二分类大模型,利用提示词工程技术,实现短信情感与意图多维度分析,实现诈骗短信特征深层识别,实现对高变异火星文诈骗短信的识别,为诈骗短信治理提供新手段。
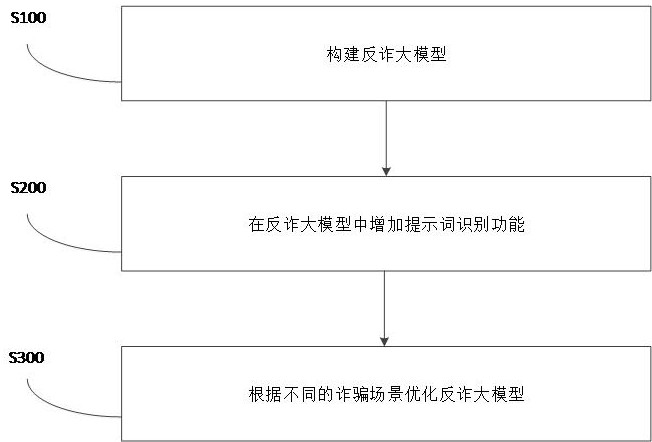
2、一种基于大模型的境外诈骗短信识别方法,包括:
3、构建反诈大模型;
4、在所述反诈大模型中增加提示词识别功能;
5、根据不同的诈骗场景优化反诈大模型。
6、优选地,所述构建反诈大模型包括:
7、采用基础预训练大模型和诈骗短信监控适配层融合得到反诈大模型。
8、优选地,所述构建反诈大模型之后,还包括对反诈大模型进行训练,具体为:
9、采用指定式微调法选择性更新反诈大模型中数据稀缺的模块和新发的模块;
10、采用重参数化微调法改变反诈大模型的参数;
11、设置预训练模型为:;
12、生成模型参数为:;
13、采用增量式微调法在反诈大模型中添加新的层或模块:
14、;
15、将权重变化w分解为较低秩的表示,假设w表示给定神经网络层中的权重矩阵,然后使用常规反向传播,可以获得权重更新w,即通常被计算为损失乘以学习率的负梯度:;
16、更新后的权重为:。
17、优选地,所述在所述反诈大模型中增加提示词识别功能包括:
18、构建prompt提示词工程:将诈骗短信分为情感分类、深层意图识别、内容领域分类和判断量化分类四类;
19、设置prompt的参数;
20、将不同类型的诈骗短信输入设置好的prompt,prompt输出判断结果。
21、优选地,所述设置prompt的参数包括:
22、采用top-k采样、top-p采样和temperature采样动态调整prompt的生成结果;
23、temperature采样中状态的概率表示为:;
24、是状态的概率,是状态的能量,k是波兹曼常数,t是系统的温度,m是系统所能到达的所有量子态的数目。
25、优选地,所述根据不同的诈骗场景优化反诈大模型包括:
26、根据诈骗短信深层的数据维度特征,提取字符unicode区间分布、字符符号类型、分词统计的泛化特征;
27、根据所述泛化特征对样本进行维护和更新分类器参数;
28、针对未被识别的诈骗短信,对消息进行短信内容、url特征串的聚类分析;
29、通过人工审核方式确定是否为诈骗短信;
30、如是,则将未被识别的诈骗短信加入到诈骗短信指纹样本库中。
31、优选地,所述根据诈骗短信深层的数据维度特征,提取字符unicode区间分布、字符符号类型、分词统计的泛化特征包括:
32、在混合语系、生僻字符、不可见字符、结合符号、emoji表情中提取字符unicode区间分布的泛化特征;
33、在异常短信底层符号类型概率分布中提取字符符号类型分布特征;
34、在汉字形近变异词、字词间隔干扰、音近词和英文词语中提取分词统计特征。
35、一种基于大模型的境外诈骗短信识别系统,包括:
36、构建模块,用于构建反诈大模型;
37、功能添加模块,用于在所述反诈大模型中增加提示词识别功能;
38、优化模块,用于根据不同的诈骗场景优化反诈大模型。
39、一种电子设备,包括:处理器和存储器,所述存储器用于存储计算机程序代码,所述计算机程序代码包括计算机指令,当所述处理器执行所述计算机指令时,所述电子设备执行一种基于大模型的境外诈骗短信识别方法。
40、一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序包括程序指令,所述程序指令当被电子设备的处理器执行时,使所述处理器执行一种基于大模型的境外诈骗短信识别方法。
41、本发明的有益效果在于:1.本发明基于预训练大模型,采用叠加“反诈专用提示词(prompt)+反诈样本微调(loray的大模型训练方式,形成基于垃圾短信的反诈大模型,旨在解决短信领域的诈骗问题。通过引入反诈大模型,成功打造了一套全面、精准、智能的垃圾短信治理平台,能够在短时间内快速识别、防范和拦截各类诈骗短信,为用户提供更加安全可靠的通信环境。2.相比传统的基于规则的方法和基于机器学习的方法的垃圾短信系统,反诈大模型在诈骗短信的预测准确率、拦截准确率方面取得了明显提升。经过某运营商针对境外短信的试点验证,境外涉诈短信案件量同比下降85%,涉诈预警量同比下降99.98%,彰显了系统在诈骗短信治理方面的显著成果。这表明,反诈大模型不仅在实践中表现出了高效性和可靠性,而且为境外短信安全问题的应对提供了有效解决方案,具有广泛的应用前景和推广价值。3.本方案能够还原高变异的火星文诈骗短信之外,还能够判断该短信是否是诈骗短信。4.本方案能实现读音相似字和字形相似字还原,还能够从短信语义情感特征分析、意图特征分析和诈骗可疑度等多维度进行评估,全面准确预测诈骗短信内容。
技术特征:
1.一种基于大模型的境外诈骗短信识别方法,其特征在于,包括:
2.根据权利要求1所述的一种基于大模型的境外诈骗短信识别方法,其特征在于,所述构建反诈大模型包括:
3.根据权利要求1所述的一种基于大模型的境外诈骗短信识别方法,其特征在于,所述构建反诈大模型之后,还包括对反诈大模型进行训练,具体为:
4.根据权利要求1所述的一种基于大模型的境外诈骗短信识别方法,其特征在于,所述在所述反诈大模型中增加提示词识别功能包括:
5.根据权利要求4所述的一种基于大模型的境外诈骗短信识别方法,其特征在于,所述设置prompt的参数包括:
6.根据权利要求1所述的一种基于大模型的境外诈骗短信识别方法,其特征在于,所述根据不同的诈骗场景优化反诈大模型包括:
7.根据权利要求6所述的一种基于大模型的境外诈骗短信识别方法,其特征在于,所述根据诈骗短信深层的数据维度特征,提取字符unicode区间分布、字符符号类型、分词统计的泛化特征包括:
8.一种基于大模型的境外诈骗短信识别系统,其特征在于,包括:
9.一种电子设备,其特征在于,包括:处理器和存储器,所述存储器用于存储计算机程序代码,所述计算机程序代码包括计算机指令,当所述处理器执行所述计算机指令时,所述电子设备执行如权利要求1至7任一项所述的一种基于大模型的境外诈骗短信识别方法。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中存储有计算机程序,所述计算机程序包括程序指令,所述程序指令当被电子设备的处理器执行时,使所述处理器执行权利要求1至7任意一项所述的一种基于大模型的境外诈骗短信识别方法。
技术总结
本发明的目的是提供一种基于大模型的境外诈骗短信识别方法,该方法包括:构建反诈大模型;在所述反诈大模型中增加提示词识别功能;根据不同的诈骗场景优化反诈大模型。本发明借助ChatGPT为代表的大模型技术具备强大的语义识别、情感与意图分析能力,借助大模型微调技术,将诈骗短信特征学习与大模型的自然语义理解能力相结合,提出一种反诈识别二分类大模型,利用提示词工程技术,实现短信情感与意图多维度分析,实现诈骗短信特征深层识别,实现对高变异火星文诈骗短信的识别,为诈骗短信治理提供新手段。
技术研发人员:钟盛
受保护的技术使用者:广州市申迪计算机系统有限公司
技术研发日:
技术公布日:2025/3/24
- 还没有人留言评论。精彩留言会获得点赞!