一种论坛文本认知状态感知模型的构建方法
本发明涉及构建模型领域,尤其涉及一种论坛文本认知状态感知模型的构建方法。
背景技术:
1、协作学习环境下的论坛讨论是学习者思维过程和知识技能的外化表达,是识别学习者认知水平和自主探究能力的重要途径。利用论坛文本评估学习者的认知水平不仅有助于学习者及时发现在线学习过程中的问题,从而改进学习策略,也有助于教师提供个性化的学习指导,提升教学质量和学习成效。传统的文本分析方法更适用于一般领域的文本主题分类或情感识别,忽视了学生参与讨论时认知状态随时间的演化过程,因此难以充分挖掘和理解讨论文本中的复杂语义结构和深层认知内涵,导致其在认知状态感知任务上表现不佳。基于此,本发明提出一种融合文本前后语句间时序语义特征的论坛文本认知状态感知模型是至关重要的。
技术实现思路
1、有鉴于此,本发明提供了一种论坛文本认知状态感知模型的构建方法。
2、为解决上述技术问题,本发明采取了如下技术方案:
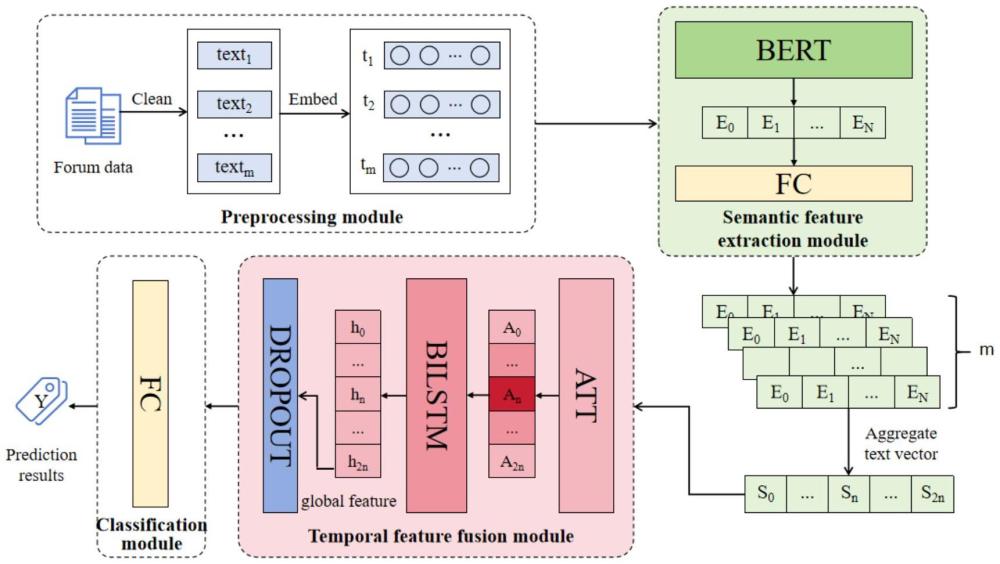
3、一种论坛文本认知状态感知模型的构建方法,其特征在于,包括数据采集模块、预处理模块、语义提取模块、时序特征融合模块和分类模块;其中,
4、数据采集模块用来收集论坛文本数据;
5、预处理模块用于对论坛文本进行分类,并将文本转换为机器可接受的向量形式;
6、语义提取模块用于得到讨论文本内部的上下文语义特征;
7、时序特征融合模块用于充分挖掘并融合独立讨论文本之间的时序认知特征即全局特征;
8、分类模块用于对文本表征的认知水平进行分类。
9、优选的,所述数据采集的方法为:
10、首先对论坛文本进行标注分类,将收集到的论坛文本数据根据krathwohl提出的布鲁姆教育目标分类法的修订版人工标注为0、1两类;0代表记忆、理解、应用三个低阶认知水平,1代表分析、评价、创造三个高阶认知水平。
11、优选的,所述预处理的方法为:
12、首先将所有文本段进行长度的归一化处理,对长度小于指定最大长度的文本进行zero padding操作,对长度大于指定最大长度的文本进行truncation操作,使得每条文本的长度统一为n;其次在序列的开始和结束分别添加[cls]和[sep]特殊标记,然后将清洗后的文本切分成token,以及每个token对应的编码token embeddings,同时生成与之对应的attention mask来区别原有的token与填充的token,input_ids和attention_mask张量一起构成了词嵌入向量,其中n表示文本最大长度。
13、优选的,所述语义提取模块由一个bert层和一个全连接层构成,其中,bert是一种基于transformer架构的深度学习模型,它通过在大规模无标注文本数据上进行预训练学习到丰富的语言表示。
14、优选的,所述语义提取的方法为:
15、选择bert提取文本的局部语义特征,将预处理阶段得到的词嵌入向量x作为输入,即:
16、e=bert(x)#(1)
17、由此可以获得bert层输出的文本局部语义特征向量e=(e0,e1,…,en-1),n表示最大序列长度;再将该向量输入到一个全连接层,以便在捕获文本中关键语义特征的同时尽可能保留文本的原始特征,即:
18、e′=ew+b#(2)
19、其中,d1,d2分别表示bert的隐藏层大小;
20、由此得到压缩后的局部语义特征向量e′=(e0,e1,…,en-1),n表示最大序列长度。
21、优选的,所述时序特征融合模块由一个注意力层、一个bilstm层和一个dropout层组成。
22、优选的,所述时序特征融合方法为:
23、对于语义提取模块获得的每一个局部语义特征向量e′,均获取了当前文本的前n条和后n条文本向量构成前后文窗口,以该窗口中的2n+1条文本向量序列s=(s0,…,sn,...s2n)作为注意力层的输入,在注意力层中计算该文本序列之间的相互依赖关系,并输出带有注意力的特征表示;注意力得分的计算公式可表示为:
24、q=swq,k=swk,v=swv#(3)
25、
26、其中,权重矩阵d2是bilstm的隐藏层大小,dk是键矩阵k的维度,输出是值(v)矩阵的加权求和,权重由注意力得分确定;注意力层通过考虑文本序列之间的相互作用,得到增强的向量表达a=(a0,…,an,...,a2n),其中ai=(a1,a2,…,an)表示每个文本段的输出不仅包含自身的信息,还包含了其他段的相关信息,对认知水平评估贡献较大的文本段赋予更高的权重,以此作为bilstm层的输入。
27、优选的,所述时序特征融合方法还包括bilstm模型通过前向和后向lstm充分挖掘序列数据的长期特征,a=(a0,…,an,...,a2n)是模型的输入部分,表示2n+1个包含其他文本序列特征的独立文本向量表示,t时刻的输出计算方法如下:
28、
29、其中,和分别表示lstm在t时刻的前向和后向输出结果,ht表示bilstm在t时刻的输出结果,wt和vt分别表示前向输出的前向和后向权重矩阵,bt表示t时刻的偏置;
30、由此得到文本序列的融合时序认知特征代表融合时序认知特征之后的向量表示;
31、最后一个时间步的特征向量h2n反映了整个序列的认知特征,同时综合了前向和后向lstm的前后文信息;因此取序列最后一个时间步的输出h2n送入dropout层随机丢弃一部分特征,这有助于减少模型在训练数据上的过度拟合;计算公式如下:
32、
33、其中,m中的每个元素为独立同分布的伯努利随机变量,p表示h2n中每个元素被保留的概率;由此得到时序特征融合的全局特征向量
34、优选的,所述分类模块包括一个全连接层。
35、优选的,所述分类方法为:
36、经过dropout处理后的全局特征向量输入全连接层,该层将特征向量映射到最终类别的预测得分,可表示为:
37、
38、其中,b∈r1×2;
39、采用交叉熵损失函数来衡量模型预测的概率分布与真实概率分布之间的差异,以此作为优化模型参数的依据,将模型的输出转化为类别概率,进而与真实类别标签的概率分布进行比较;
40、数学公式如下:
41、
42、其中,y是真实标签的概率,是模型预测的概率。
43、本发明相对于现有技术取得了以下技术效果:
44、通过实验表明,本发明提出的模型在基于论坛讨论数据的认知状态感知任务中优于其他基线模型,同时经消融实验验证,表明了本发明提出的融合讨论文本前后语句间时序语义特征对模型分类效果的积极影响。
技术特征:
1.一种论坛文本认知状态感知模型的构建方法,其特征在于,包括数据采集模块、预处理模块、语义提取模块、时序特征融合模块和分类模块;其中,
2.根据权利要求1所述的一种论坛文本认知状态感知模型的构建方法,其特征在于,所述数据采集的方法为:
3.根据权利要求1所述的一种论坛文本认知状态感知模型的构建方法,其特征在于,所述预处理的方法为:
4.根据权利要求1所述的一种论坛文本认知状态感知模型的构建方法,其特征在于,所述语义提取模块由一个bert层和一个全连接层构成,其中,bert是一种基于transformer架构的深度学习模型,它通过在大规模无标注文本数据上进行预训练学习到丰富的语言表示。
5.根据权利要求1所述的一种论坛文本认知状态感知模型的构建方法,其特征在于,所述语义提取的方法为:
6.根据权利要求1所述的一种论坛文本认知状态感知模型的构建方法,其特征在于,所述时序特征融合模块由一个注意力层、一个bilstm层和一个dropout层组成。
7.根据权利要求1所述的一种论坛文本认知状态感知模型的构建方法,其特征在于,所述时序特征融合方法为:
8.根据权利要求7所述的一种论坛文本认知状态感知模型的构建方法,其特征在于,所述时序特征融合方法还包括bilstm模型通过前向和后向lstm充分挖掘序列数据的长期特征,a=(a0,…,an,...,a2n)是模型的输入部分,表示2n+1个包含其他文本序列特征的独立文本向量表示,t时刻的输出计算方法如下:
9.根据权利要求1所述的一种论坛文本认知状态感知模型的构建方法,其特征在于,所述分类模块包括一个全连接层。
10.根据权利要求1所述的一种论坛文本认知状态感知模型的构建方法,其特征在于,所述分类方法为:
技术总结
本发明公开了一种论坛文本认知状态感知模型的构建方法,包括数据采集模块、预处理模块、语义提取模块、时序特征融合模块和分类模块;其中,数据采集模块用于收集论坛文本数据;预处理模块用于对论坛文本进行分类,并将文本转换为机器可接受的向量形式;语义提取模块用于得到独立文本内部的上下文语义特征;时序特征融合模块用于充分挖掘并融合独立讨论文本之间的时序认知特征以得到讨论文本的全局特征;分类模块用于对文本表征的认知水平进行分类。通过实验表明,本发明提出的模型在基于论坛讨论数据的认知状态感知任务中优于其他基线模型,同时经消融实验验证,表明了本发明提出的融合讨论文本前后语句间时序语义特征对模型分类效果的积极影响。
技术研发人员:何秀玲,叶思蓉,方静,李洋洋,肖雄
受保护的技术使用者:华中师范大学
技术研发日:
技术公布日:2024/12/5
- 还没有人留言评论。精彩留言会获得点赞!