用于演化图历史可达性查询的高效索引方法
本发明涉及信息,尤其涉及一种用于演化图历史可达性查询的高效索引方法。
背景技术:
1、可达性查询是一个基本问题,在静态图上已经得到了很好的研究,但对于演化图却没有引起太多关注。有几个实际应用程序可以从历史可达性查询中受益。例如,在蛋白质-蛋白质相互作用网络中,研究两种蛋白质是否参与共同的生物过程或分子功能非常重要。连接可达性可以帮助监测这两种蛋白质在特定时期内是否连续属于同一生物组织。在货币交易监控中,用户账户可以被视为一个顶点,而货币交易可以被视为两个用户账户之间的边。分离可达性可以帮助识别两个可疑账户之间在较长监控周期内指定的短时间内是否存在交易路径。
2、静态图的可达性查询方法的主要思想是构造各种索引以使可达性查询更加高效。然而,这些方法不能用于演化图,因为由于顶点和边的删除或插入,为快照构建的索引不适用于其他快照。一种简单的方法是通过给定时间间隔内每个快照上的bfs/dfs遍历来回答查询,这会带来较高的查询时间开销。另一种方法是为演化图的每个快照构建索引,但当演化图具有大量快照时,空间效率低下。因此,本发明提出的一种用于演化图历史可达性查询的高效索引方法具有重大意义。
技术实现思路
1、本发明目的就是为了弥补已有技术的缺陷,提供一种用于演化图历史可达性查询的高效索引方法,本发明可以对演化图序列构建索引,即hr-index,通过hr-index可以高效的回答任何历史可达性查询,且该索引可以随着演化图序列的增加而低成本的动态更新。
2、本发明是通过以下技术方案实现的:
3、一种用于演化图历史可达性查询的高效索引方法,所述方法包括:
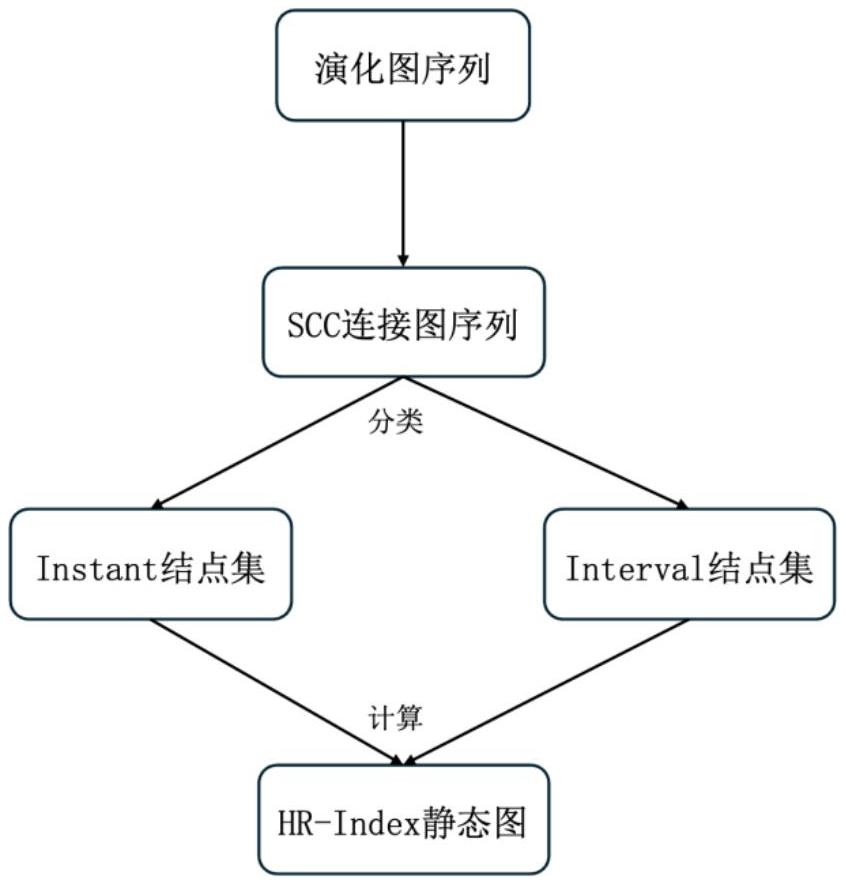
4、采用强连通分量技术降低演化图的结点数及边数;
5、通过新颖的设计将对演化图的历史可达性查询转化为对静态图的查询;
6、通过优化技术来有效的减少索引的结点数;
7、一种可动态更新索引的方法。
8、其中,所述的演化图指的是一系列有向图序列,可以定义为g=(g0,···,g||g||-1),其中每个gx=(vx,ex)是g在某个时间点的快照,具有一组顶点和一组边。∥g∥是g中快照的个数,称为g的长度。具体来说,gi是演化图g在时间间隔i=[tx,ty]上的快照子序列,即gi=(gx,···,gy)。其中tx,ty表示两个不同的时刻,gx,gy分别表示tx,ty这两个时刻的演化图g,vx表示演化图gx的结点集,ex表示演化图gx的边集。
9、其中,有向图的强连通分量(scc),表示为si,是g的最大强连通子图。如果两个顶点属于同一个scc,则它们互相可达。通过将每个scc视为一个新的顶点,可以将原始图转换为有向无环图(或dag)。当演化图随着时间的推移而演变,其scc也会发生变化。快照中同一scc中的两个顶点在下一个快照中可能因为边删除而无法到达。相反,两个不同的scc可以在下一个快照中合并成新的scc。因此本发明利用tarjans算法来识别g中每个快照的scc,并将每个快照都转换成一张用scc表示的dag,最后组成一系列由dag构成的新的演化图序列,该序列中的图中的每个顶点都代表一个scc。
10、其中,将对演化图的历史可达性查询转化为对静态图的查询的技术是将dag构成的演化图序列转化为一张静态图hr-index,将对任意时刻的可达性查询转化为对hr-index上的两个点的可达性查询。定义一种新的结点类型为scc的id加该scc的生存时间(即它在哪些时刻存在于演化图序列中),以这种新的结点作为hr-index的结点,表示形式为<sccid,lifetime>;hr-index的边则遵循如下规则:对于任意两个结点<s1,l1>和<s2,l2>,当在l2的全部时刻内均有s1可达s2且有时,建立一条由<s1,l1>指向<s2,l2>的边。可达性查询转化则如下:当要查询tx时刻结点s和结点t是否可达时,在hr-index查找结点<s1,l1>和<s2,l2>,其中满足s∈s1,t∈s2,tx∈l1,tx∈l2,之后查询<s1,l1>是否可达<s2,l2>,便可得知tx时刻结点s是否可达结点t。
11、其中,优化技术指的是通过合并scc的id来减少hr-index所需的存储空间。在利用tarjans算法来识别g中每个快照的scc时,每个scc会被赋予独一无二的id,但如果两个scc未曾在同一时刻同时出现,即它们的生存周期没有交集,则用同一个id表示这两个scc也不会造成混淆,同时会节约存储空间、提升查询效率。因此,本发明利用图着色问题对这一问题进行建模,由于这一问题已被证明是np难问题,本发明采用近似算法welch powell算法进行求解并对scc的id进行优化。
12、其中,动态更新索引的方法为,对后续到来的若干演化图按上述方法构建hr-index,之后检查两个hr-index中的所有入度为0的结点,由于两个hr-index是独立构建的,因此会有一些结点表示了相同的scc但却具有不同的id,将其中所有表示同一个scc的结点合并,这一过程称为初步合并。在完成初步合并的新hr-index中,从所有入度为0的结点出发进行广度优先遍历(bfs),在遍历过程中按规则检查可合并的结点并将它们合并,最后完成动态更新过程。
13、本发明的优点是:
14、1、本发明提出一种新颖的、高效的索引方法用于支持演化图序列的历史可达性查询,现实中顶点规模千万级的动态图数据所构建出来的的hr-index顶点规模仅为数万,且其上的历史可达性查询效率较当前先进方法提升了2-3个数量级;
15、2、为了应对演化图序列会动态更新这一问题,本发明进一步提出了一种高效率的更新方法,可根据新的演化图序列对已构建好的hr-index进行高效更新,与全部重新构建hr-index相比具有几倍的效率提升,可以适用于更多样化的应用场景。
技术特征:
1.一种用于演化图历史可达性查询的高效索引方法,其特征在于,所述方法包括:
2.根据权利要求1所述的一种用于演化图历史可达性查询的高效索引方法,其特征在于,所述的演化图指的是一系列有向图序列,定义为g=(g0,···,g||g||-1),其中每个gx=(vx,ex)是演化图g在某个时间点的快照,具有一组顶点和一组边;∥g∥是演化图g中快照的个数,称为演化图g的长度,gi是演化图g在时间间隔i=[tx,ty]上的快照子序列,即gi=(gx,···,gy),其中tx,ty表示两个不同的时刻,gx,gy分别表示tx,ty这两个时刻的演化图g,vx表示演化图gx的结点集,ex表示演化图gx的边集。
3.根据权利要求2所述的一种用于演化图历史可达性查询的高效索引方法,其特征在于,步骤101所述的采用强连通分量技术降低演化图的结点数及边数,具体如下:
4.根据权利要求3所述的一种用于演化图历史可达性查询的高效索引方法,其特征在于,所述的将每个快照都转换成一张用强连通分量scc表示的有向无环图dag,具体方法为:在每一张快照图上用tarjans算法来识别当前快照图中的所有强连通分量scc,用si表示,si是一个结点的集合,对均有s→t,对于强连通分量scc表示的有向无环图dag,将其记作gdag=(vdag,edag),其中vdag由si组成,即每个强连通分量scc作为一个gdag中的结点;而gdag中的边由各si中的点的连接关系构成,具体为:如果有s→t且s∈si,t∈sj,则有边(si,sj)∈edag,gdag是无权图,si,sj表示演化图g中的强连通分量,所以若有多个s→t且s∈si,t∈sj,则只创建一条边(si,sj),同时维护一张scc表,此scc表记录了每个强连通分量scc对应的id、所包含的所有结点及生存周期,对演化图序列中的所有快照都作此处理,最后得到由有向无环图dag构成的新的演化序列图,其中的每个结点均代表一个强连通分量scc,edag表示gdag中的边,dag是有向无环图,gdag表示一个有向无环图,其结点均为所述的强连通分量si,而它的边的集合就由edag表示。
5.根据权利要求4所述的一种用于演化图历史可达性查询的高效索引方法,其特征在于,所述的对所有的强连通分量scc用图着色问题进行建模,具体方法为:依次检查每两个不同的强连通分量scc,如果它们的生存周期没有交集,则在它们之间创建一条边,最后得到一张结点为所有的scc,边为按照上述规则创建的无向图,在创建完对应的图后,在这张图上运用welch powell算法求解图着色问题,并根据求解结果对强连通分量scc的id进行优化,如果求解的结果中有多个结点被标记为一种颜色,则代表这些强连通分量scc共用一个id,则在这些id中挑选一个作为所有这些强连通分量scc的id。
6.根据权利要求5所述的一种用于演化图历史可达性查询的高效索引方法,其特征在于,所述的建立并维护一张出邻居表,具体方法为:记录每个强连通分量scc即si在哪些时刻可达哪些其它结点,具体来说,若si在tx时刻可达sj,则将sj称为si的出邻居,根据tx时刻si是否有入邻居,即是否有其它的scc可达si,将sj分类为interval型出邻居或instant型出邻居,若tx时刻si是有入邻居,则sj为instant型出邻居,否则为interval型出邻居。
7.根据权利要求6所述的一种用于演化图历史可达性查询的高效索引方法,其特征在于,所述的根据出邻居表构建hr-index静态图,具体方法为:
8.根据权利要求7所述的一种用于演化图历史可达性查询的高效索引方法,其特征在于,所述的将对演化图的历史可达性查询转化为对hr-index静态图的查询,具体方法为:当要查询tx时刻结点s和结点t是否可达时,在hr-index查找结点<s1,l1>和<s2,l2>,其中满足s∈s1,t∈s2,tx∈l1,tx∈l2,之后查询<s1,l1>是否可达<s2,l2>,便知tx时刻结点s是否可达结点t;static-query表示在静态图hr-index上进行可达性查询,使用grail方法对静态的hr-index构建索引并支持可达性查询。
9.根据权利要求8所述的一种用于演化图历史可达性查询的高效索引方法,其特征在于,所述的当出现新的演化图序列时,对新的序列构建新的hr-index静态图,并与已经存在的hr-index静态图合并,得到更新后的hr-index静态图,具体方法为:当出现新的演化图序列时,对新增的子序列部分按照步骤101-103方法所述构建新的hr-index,将新构建的hr-index记作ig2,将已经存在的hr-index记作ig1,之后检查两个hr-index中的所有入度为0的结点,由于两个hr-index是独立构建的,因此会有一些结点表示了相同的scc但却具有不同的id,将其中所有表示同一个scc的结点合并,这一过程称为初步合并;在完成初步合并的新hr-index中,从所有入度为0的结点出发进行广度优先遍历bfs,在遍历过程中按规则检查可合并的结点并将它们合并,最后完成动态更新过程。
技术总结
本发明公开了一种用于演化图历史可达性查询的高效索引方法,所述方法包括:采用强连通分量技术降低演化图的结点数及边数;通过新颖的设计将对演化图的历史可达性查询转化为对静态图的查询;通过两种优化技术来有效的减少索引的结点数。本发明可以在大规模演化图上高效的回答历史可达性查询问题,为各种下游任务提供重要支撑。
技术研发人员:曹佳阳,杨雅君
受保护的技术使用者:天津大学合肥创新发展研究院
技术研发日:
技术公布日:2024/11/4
- 还没有人留言评论。精彩留言会获得点赞!