一种深度学习网络中神经元卷积核的计算优化方法与流程
本发明涉及深度学习领域,具体的是一种深度学习网络中神经元卷积核的计算优化方法。
背景技术:
1、卷积神经网络(convolutional neural network,cnn)是一种前馈型的神经网络,其在大型图像处理方面有出色的表现,目前已经被大范围使用到图像分类、定位等领域中。相较于其他神经网络结构,卷积神经网络需要的参数相对较少,使的其能够广泛应用。
2、卷积核就是图像处理时,给定输入图像,输入图像中一个小区域中像素加权平均后成为输出图像中的每个对应像素,其中权值由一个函数定义,这个函数称为卷积核。
3、在卷积神经网络中,卷积层的计算量占据总体计算量90%以上,因此,卷积层运算的加速是卷积神经网络加速的重要组成部分。为实现卷积神经网络的优化计算,本领域研究人员进行了深入研究。
4、cn1374692公开了一种内在并行的二维离散小波变换的vlsi结构的设计方法,通过移位加技术将滤波器中的乘法操作变为移位寄存器和加法器的操作;通过公用子表达式技术尽量减少滤波器实现中的移位寄存器和加法器的个数;通过滤波器合并技术将低通滤波器和高通滤波器操作中的公共项合并,在一个紧凑的硬件结构中同时实现低通和高通的并行操作;通过滤波器组合并技术将2-d dwt列滤波的两组滤波器合而为一,以增加硬件的利用率。但是,由于滤波器系数往往不规则,故公用子表达式并不适用于神经网络卷积核和滤波器。两个滤波器中的公用表达式合并非常有限,但这依赖于卷积神经网特有的架构,并不适合滤波器。
5、cn110059817a则公开了一种实现低资源消耗卷积器的方法,该方案将卷积器的乘法核内部进行拆解,将乘法核内部具有相同偏移量的数据进行相加,形成卷积加法核;根据每个卷积加法核所对应的偏移量,对卷积加法核的结果进行相应的移位,并通过加法树算出最终的卷积结果。该发明的硬件消耗相比传统方法大约节省5~1 0%的lut资源(fpga实现),并且具有易于部署及方便重用等优点。该方案与cn1374692基本一致,虽然cn1374692用于小波变换,cn110059817a用于卷积,但二者都是将卷积运算中的乘法运算转换成二进制加法之和,再(相加)合并(指数)相同项;然后将合并项按照指数值做算数移位,最后将所有合并项求和。其方法没有本质上的区别,如cn1374692文献所述,此种方法仅适用于asic专用集成电路设计,但是并非适合市面上常见的可编程处理器,特别是vliw的数字信号处理器。
技术实现思路
1、本发明针对背景技术中存在的问题,设计了优化深度学习网络中神经元卷积核的计算优化方法,主要贡献在于提出了几种减少乘法运算的方法。相对于加法运算,乘法的复杂度高很多,需要的片上面积和功耗也都高很多。因此,尽可能地减少卷积核运算中的乘法数目是很有必要的。
2、技术方案:
3、一种深度学习网络中神经元卷积核的计算优化方法,应用于1)同一卷积核中权重参数的合并优化,以及2)同层跨多个卷积核中对应输入位置权重参数的合并优化;优化方法包括以下步骤:
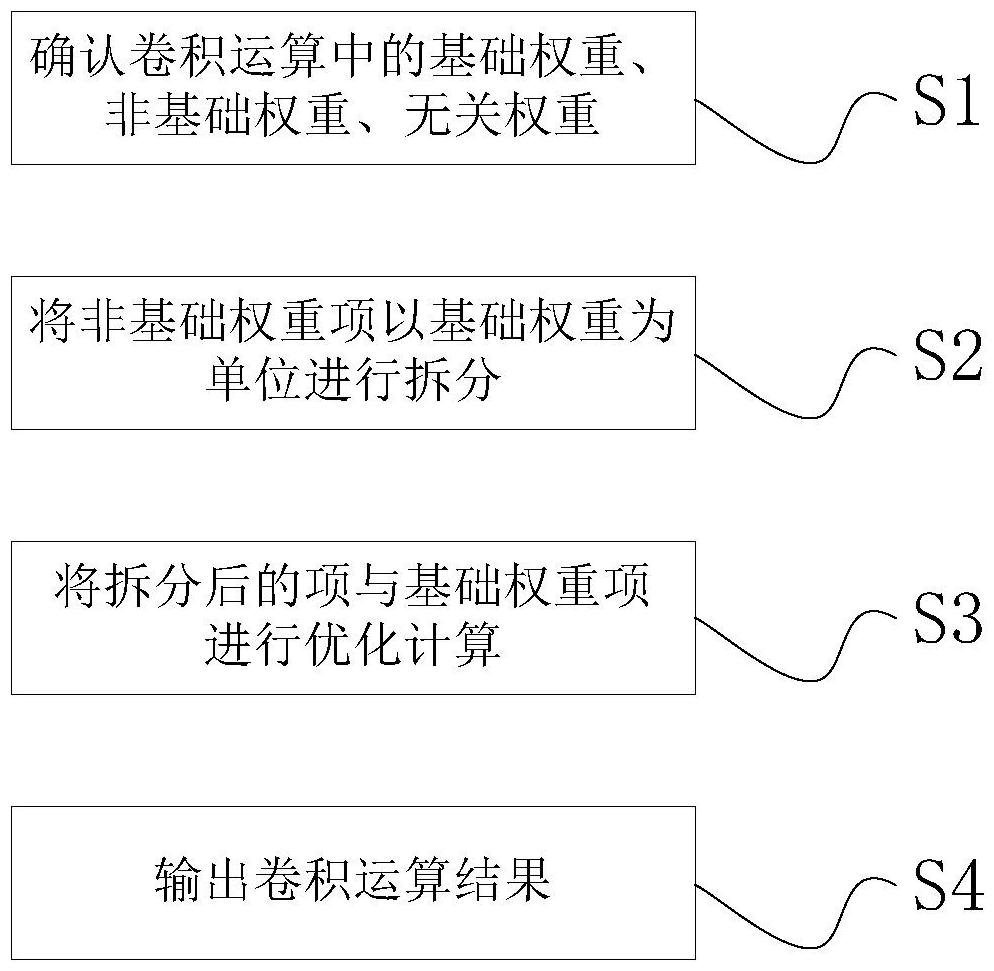
4、s1、确认卷积运算中的基础权重、非基础权重、无关权重,含基础权重的项记为基础权重项、含非基础权重的项记为非基础权重项、含无关权重的项记为无关项;
5、s2、将非基础权重项以基础权重为单位进行拆分;
6、s3、将拆分后的项与基础权重项进行优化计算;
7、s4、输出卷积运算结果。
8、优选的,所述基础权重的获取方法为:将所有权重进行排序,权重值最小的作为基础权重。
9、优选的,除基础权重、非基础权重外的权重,作为无关权重。
10、优选的,将基础权重记为wpj,满足以下条件的权重作为非基础权重:
11、wpi=awpj (1)
12、或wpk=wpj+2m(2)
13、其中,a为任意正整数,m为任意自然数,wpi、wpk均为非基础权重。
14、优选的,s2中,将非基础权重项以基础权重为单位进行拆分,具体是将非基础权重改写为式(1)或式(2)的形式。
15、优选的,非基础权重项与基础权重项在同一个卷积核中,对于卷积运算:
16、xiwpi+xjwpj+xkwpk+…
17、s3进行优化计算是:
18、xiwpi+xjwpj+xkwpk+…=wpj(axi+xj+xk)+xk2m+…
19、其中,axi通过将xi移位获得,xk2m通过将xk移位获得。
20、优选的,a=2n±1,axi通过将xi左移n位后,±xi获得;xk2m通过将xk左移m位获得。
21、优选的,非基础权重项与基础权重项不在同一个卷积核中,则s3所述优化计算是:将非基础权重项以s2中改写的形式进行计算;
22、具体的,对于:
23、卷积核p1中卷积运算:xiwpj+…
24、卷积核p2中卷积运算:xiwpi+…
25、卷积核p3中卷积运算:xiwpk+…
26、s3进行优化计算是:
27、卷积核p1的输出为:xjwpj+…
28、卷积核p2的输出为:axjwpj+…
29、卷积核p3的输出为:xjwpj+xj2m+…
30、其中,axj通过将xj移位获得,xj2m通过将xj移位获得。
31、优选的:a=2n±1,axj通过将xj左移n位后,±xj获得;xj2m通过将xj左移m位获得。
32、本发明的有益效果
33、本发明利用算数运算规律,二进制数的分解以及移位加法器等方式来减少卷积运算中的乘法运算,实现深度学习网络中神经元卷积核的计算优化。
34、本发明针对可编程处理器,如vliw、有数字信号处理扩展的cpu、数据流处理器等。这类处理器同时具有多个加法器和乘法器,有的还有除法器和超越函数加速器。在这些处理器中,加法和乘法通常都在一个时钟周期内完成,虽然两者需要的功耗大不相同。在有些处理器中乘法也可能花费二个时钟周期,但这远远低于将一个乘法运算分解成的加法数目。对于8位的二进制乘法,一个乘法运算平均可以分解成4个加法,需要4个时钟周期才能完成,而一个乘法只需要1-2个时钟周期。因此,减少乘法运算的数目不仅降低功耗,还可以加快运算速度。
35、本发明旨在针对上述可编程处理器卷积网的计算优化,其目的是降低乘法运算的数目,也因此降低了总的运算数目,其目的和应用范围不同于两个对比参考文献(cn110059817a、cn110059817a)。我们还用常见的resnet卷积网做了优化实验,其结果是能够将乘法运算数目降低到50-60%左右。采用了权重索引读取方法,在可编程处理器上的性能也有大幅提高。
技术特征:
1.一种深度学习网络中神经元卷积核的计算优化方法,其特征在于,优化方法包括以下步骤:
2.根据权利要求1所述的方法,其特征在于,所述基础权重的获取方法为:将所有权重进行排序,权重值最小的作为基础权重。
3.根据权利要求1所述的方法,其特征在于,除基础权重、非基础权重外的权重,作为无关权重。
4.根据权利要求1所述的方法,其特征在于,将基础权重记为wpj,满足以下条件的权重作为非基础权重:
5.根据权利要求4所述的方法,其特征在于,s2中,将非基础权重项以基础权重为单位进行拆分,具体是将非基础权重改写为式(1)或式(2)的形式。
6.根据权利要求4所述的方法,其特征在于,非基础权重项与基础权重项在同一个卷积核中,对于卷积运算:
7.根据权利要求6所述的方法,其特征在于,a=2n±1,axi通过将xi左移n位后,±xi获得;xk2m通过将xk左移m位获得。
8.根据权利要求4所述的方法,其特征在于,非基础权重项与基础权重项不在同一个卷积核中,则s3所述优化计算是:将非基础权重项以s2中改写的形式进行计算;
9.根据权利要求8所述的方法,其特征在于:a=2n±1,axj通过将xj左移n位后,±xj获得;xj2m通过将xj左移m位获得。
技术总结
本发明公开了一种深度学习网络中神经元卷积核的计算优化方法,包括以下步骤:S1、确认卷积运算中的基础权重、非基础权重、无关权重,含基础权重的项记为基础权重项、含非基础权重的项记为非基础权重项、含无关权重的项记为无关项;S2、将非基础权重项以基础权重为单位进行拆分;S3、将拆分后的项与基础权重项进行优化计算;S4、输出卷积运算结果。本发明利用算数运算规律,二进制数的分解以及移位加法器等方式来减少卷积运算中的乘法运算,实现深度学习网络中神经元卷积核的计算优化。
技术研发人员:黄昊,李涛
受保护的技术使用者:海飞科(南京)信息技术有限公司
技术研发日:
技术公布日:2024/11/7
- 还没有人留言评论。精彩留言会获得点赞!