特征提取的数据去重方法、装置、电子设备及存储介质与流程
本发明涉及计算机,尤其涉及一种特征提取的数据去重方法、装置、电子设备及存储介质。
背景技术:
1、现有的数据去重方法主要基于比较和匹配的原理,通过对数据进行逐个比较来检测重复项。
2、现有的基于比较和匹配实现的数据去重方法,在处理大规模数据时面临着计算复杂度高和效率低的挑战。另外,对于文本数据而言,简单的比较方法可能无法准确地判断语义上相似但不完全相同的文本,导致数据去重效率较低。
技术实现思路
1、本发明提供一种特征提取的数据去重方法、装置、电子设备及存储介质,用以提升数据去重的效率。
2、本发明提供一种特征提取的数据去重方法,包括如下步骤:
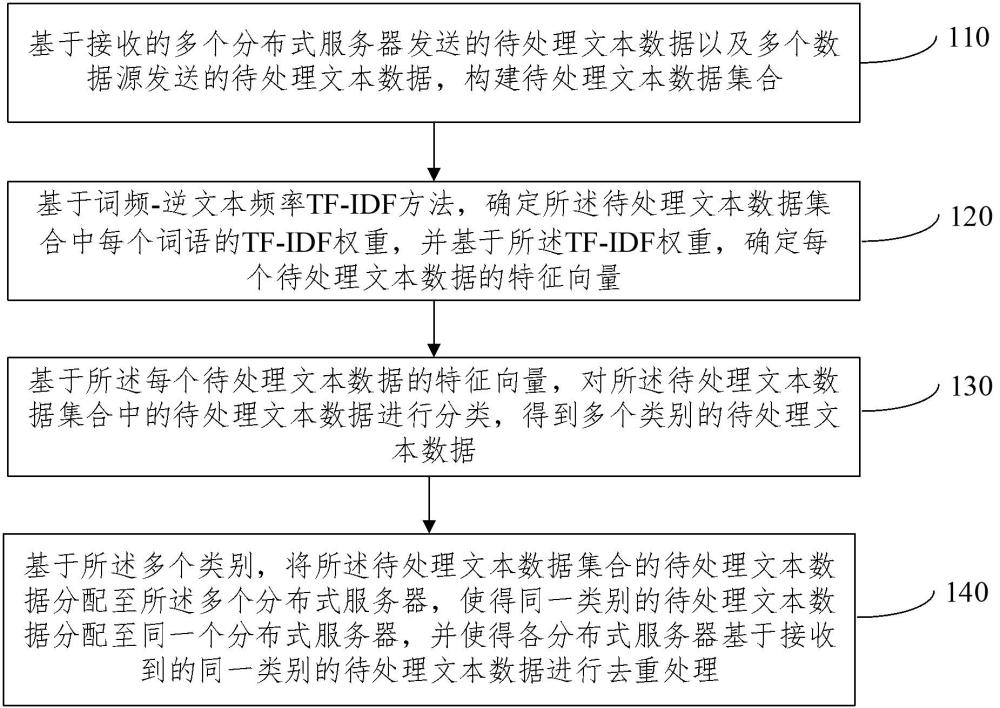
3、基于接收的多个分布式服务器发送的待处理文本数据以及多个数据源发送的待处理文本数据,构建待处理文本数据集合;
4、基于词频-逆文本频率tf-idf方法,确定所述待处理文本数据集合中每个词语的tf-idf权重,并基于所述tf-idf权重,确定每个待处理文本数据的特征向量;
5、基于所述每个待处理文本数据的特征向量,对所述待处理文本数据集合中的待处理文本数据进行分类,得到多个类别的待处理文本数据;
6、基于所述多个类别,将所述待处理文本数据集合的待处理文本数据分配至所述多个分布式服务器,使得同一类别的待处理文本数据分配至同一个分布式服务器,并使得各分布式服务器基于接收到的同一类别的待处理文本数据进行去重处理。
7、根据本发明提供的一种特征提取的数据去重方法,基于所述每个待处理文本数据的特征向量,对所述待处理文本数据集合中的待处理文本数据进行分类,得到多个类别的待处理文本数据,包括:
8、基于待处理文本数据的特征向量的确定公式,确定所述待处理文本数据集合中的各待处理文本数据的特征向量;
9、所述待处理文本数据的特征向量的确定公式是基于待处理文本数据中每个词语的特征向量、待处理文本数据中包含的所有词语的数量、待处理文本数据中的词语在待处理文本数据中计算的词频-逆文本频率tf-idf权重确定的;
10、基于所述各待处理文本数据的特征向量的取值,对所述待处理文本数据集合中相似的待处理文本数据进行确定;
11、将所述待处理文本数据集合中相似的待处理文本数据归为一类,以实现对所述待处理文本数据集合中的待处理文本数据进行分类,得到多个类别的待处理文本数据。
12、根据本发明提供的一种特征提取的数据去重方法,所述待处理文本数据的特征向量的确定公式为:
13、;
14、其中,为待处理文本数据的特征向量,n为待处理文本数据中包含的所有词语的数量,为待处理文本数据中的词语在待处理文本数据中的tf-idf权重。
15、根据本发明提供的一种特征提取的数据去重方法,所述基于词频-逆文本频率tf-idf方法,确定所述待处理文本数据集合中每个词语的tf-idf权重,包括:
16、基于词频-逆文本频率tf-idf方法,确定所述待处理文本数据集合中每个词语的词频以及每个词语的逆文档频率;
17、基于所述词频以及所述逆文档频率,确定所述待处理文本数据集合中每个词语的tf-idf权重。
18、根据本发明提供的一种特征提取的数据去重方法,所述基于所述多个类别,将所述待处理文本数据集合的待处理文本数据分配至所述多个分布式服务器,包括:
19、确定所述多个类别的待处理文本数据中各类别的待处理文本数据的数量;
20、获取所述多个分布式服务器的资源利用率,基于各分布式服务器的资源利用率以及所述各类别的待处理文本数据的数量,将所述待处理文本数据集合的待处理文本数据分配至所述多个分布式服务器。
21、根据本发明提供的一种特征提取的数据去重方法,所述构建待处理文本数据集合之后,还包括:
22、对所述待处理文本数据集合中的待处理文本数据进行数据预处理;
23、所述数据预处理包括文本分词、去停用词以及去除标点符号。
24、根据本发明提供的一种特征提取的数据去重方法,所述待处理文本数据的特征向量是基于将待处理文本数据中每个词语的tf-idf权重作为向量维度构建的。
25、本发明还提供一种特征提取的数据去重装置,包括如下模块:
26、集合构建模块,用于基于接收的多个分布式服务器发送的待处理文本数据以及多个数据源发送的待处理文本数据,构建待处理文本数据集合;
27、权重确定模块,用于基于词频-逆文本频率tf-idf方法,确定所述待处理文本数据集合中每个词语的tf-idf权重,并基于所述tf-idf权重,确定每个待处理文本数据的特征向量;
28、分类模块,用于基于所述每个待处理文本数据的特征向量,对所述待处理文本数据集合中的待处理文本数据进行分类,得到多个类别的待处理文本数据;
29、分发处理模块,用于基于所述多个类别,将所述待处理文本数据集合的待处理文本数据分配至所述多个分布式服务器,使得同一类别的待处理文本数据分配至同一个分布式服务器,并使得各分布式服务器基于接收到的同一类别的待处理文本数据进行去重处理。
30、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述特征提取的数据去重方法。
31、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述特征提取的数据去重方法。
32、本发明提供的特征提取的数据去重方法、装置、电子设备及存储介质,通过确定待处理文本数据集合中每个词语的tf-idf权重,构建每个词语的特征向量。基于每个词语的特征向量,对待处理文本数据集合中的待处理文本数据进行分类,确定多个类别,并基于确定的多个类别,将待处理文本数据集合的待处理文本数据分配至多个分布式服务器,使得同一类别的待处理文本数据分配至同一个分布式服务器。每个分布式服务器可以独立地进行去重处理,无需依赖中心服务器的实时计算,提升了数据去重效率。
技术特征:
1.一种特征提取的数据去重方法,其特征在于,所述方法包括:
2.根据权利要求1所述的特征提取的数据去重方法,其特征在于,所述基于所述每个待处理文本数据的特征向量,对所述待处理文本数据集合中的待处理文本数据进行分类,得到多个类别的待处理文本数据,包括:
3.根据权利要求2所述的特征提取的数据去重方法,其特征在于,所述待处理文本数据的特征向量的确定公式为:
4.根据权利要求1所述的特征提取的数据去重方法,其特征在于,所述基于词频-逆文本频率tf-idf方法,确定所述待处理文本数据集合中每个词语的tf-idf权重,包括:
5.根据权利要求1所述的特征提取的数据去重方法,其特征在于,所述基于所述多个类别,将所述待处理文本数据集合的待处理文本数据分配至所述多个分布式服务器,包括:
6.根据权利要求1所述的特征提取的数据去重方法,其特征在于,所述构建待处理文本数据集合之后,还包括:
7.根据权利要求1所述的特征提取的数据去重方法,其特征在于,所述待处理文本数据的特征向量是基于将待处理文本数据中每个词语的tf-idf权重作为向量维度构建的。
8.一种特征提取的数据去重装置,其特征在于,包括:
9.一种电子设备,包括存储器、处理器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至7任一项所述特征提取的数据去重方法。
10.一种非暂态计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7任一项所述特征提取的数据去重方法。
技术总结
本发明提供一种特征提取的数据去重方法、装置、电子设备及存储介质,其中方法包括:基于接收的待处理文本数据,构建待处理文本数据集合;基于TF‑IDF方法,确定待处理文本数据集合中每个词语的TF‑IDF权重,并基于TF‑IDF权重,确定每个待处理文本数据的特征向量;基于特征向量,对待处理文本数据集合中的待处理文本数据进行分类,得到多个类别的待处理文本数据;基于多个类别,将待处理文本数据集合的待处理文本数据分配至多个分布式服务器进行去重处理。使得同一类别的待处理文本数据分配至同一个分布式服务器。每个分布式服务器可以独立地进行去重处理,无需依赖中心服务器的实时计算,提升了数据去重效率。
技术研发人员:崔丽杰
受保护的技术使用者:苏州元脑智能科技有限公司
技术研发日:
技术公布日:2024/11/26
- 还没有人留言评论。精彩留言会获得点赞!