知识图谱构建方法、装置、介质、电子设备及程序产品与流程
本公开涉及电子信息,具体地,涉及一种知识图谱构建方法、装置、介质、电子设备及程序产品。
背景技术:
1、知识图谱(knowledge graph, kg)是一种用于表示和组织结构化知识的图形化知识库,它以图的形式表示实体之间的关系和属性。知识图谱是语义网络的一种扩展,通过将丰富的实体、关系和属性组织成图的形式,以便机器能够更好地理解和推理知识。知识图谱的运作依赖于大量的节点信息。
2、然而,某些领域(例如煤矿设备的故障诊断领域)的知识文本通常难以获取,或者获取成本极高,难以大量获取,从而影响了这些领域中知识图谱的构建。
技术实现思路
1、本公开的目的是提供一种知识图谱构建方法、装置、介质、电子设备及程序产品。
2、为了实现上述目的,第一方面,本公开提供一种知识图谱构建方法,包括:
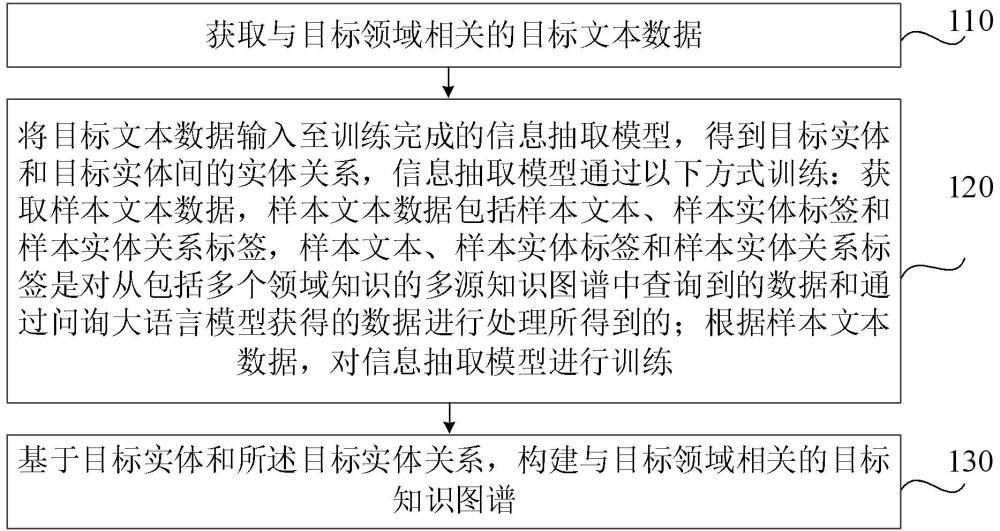
3、获取与目标领域相关的目标文本数据;
4、将所述目标文本数据输入至训练完成的信息抽取模型,得到目标实体和目标实体间的实体关系;
5、基于所述目标实体和所述目标实体关系,构建与所述目标领域相关的目标知识图谱;
6、其中,所述信息抽取模型通过以下方式训练:获取样本文本数据,所述样本文本数据包括样本文本、样本实体标签和样本实体关系标签,所述样本文本、所述样本实体标签和所述样本实体关系标签是对从包括多个领域知识的多源知识图谱中查询到的数据和通过问询大语言模型获得的数据进行处理所得到的;根据所述样本文本数据,对信息抽取模型进行训练。
7、可选的,所述方法还包括:
8、确定与样本实体类别对应的第一查询语句模板,并基于所述第一查询语句模板构建与所述样本实体类别对应的第一查询语句,并针对所述多源知识图谱执行所述第一查询语句,以得到与样本实体类别对应的样本实体和样本文本,直至查询到的所述样本实体和样本文本的数量达到第一预设阈值。
9、可选的,所述方法还包括:
10、确定与样本实体关系类别对应的第二查询语句模板,并基于所述第二查询语句模板构建与所述样本实体关系类别对应的第二查询语句,并针对所述多源知识图谱执行所述第二查询语句,以得到与所述样本实体关系类别对应的样本实体关系和样本文本,直至查询到的所述样本实体关系的数量达到第二预设阈值。
11、可选的,所述方法还包括:
12、确定与样本实体类别对应的第一问题模板,并基于所述第一问题模板构建与所述样本实体类别对应的第一问询文本,并针对所述大语言模型执行所述第一问询文本,以得到与所述样本实体类别对应的样本实体和样本文本,直至获取的所述样本文本达到第三预设阈值。
13、可选的,所述方法还包括:
14、确定与样本实体关系类别对应的第二问题模板,并基于所述第二问题模板构建与所述样本实体关系类别对应的第二问询文本,并针对所述大语言模型执行所述第二问询文本,以得到与所述样本实体关系类别对应的样本实体关系和样本文本,直至获取的所述样本文本达到第四预设阈值;
15、可选的,所述根据所述样本文本数据,对信息抽取模型进行训练,包括:
16、在所述信息抽取模型的训练过程中,在每次根据所述样本文本数据更新完所述信息抽取模型后,基于数据选择策略和数据来源权重进行知识自搜索,得到更新的样本文本数据,其中,所述数据来源权重用于表征更新的样本文本数据来源于所述多源知识图谱和所述大语言模型的比例;
17、基于更新的样本文本数据,对所述信息抽取模型进行更新,直至满足预设迭代条件。
18、可选的,所述数据选择策略为以下策略中的任意一种:
19、随机选择策略;
20、基于样本重要性的选择策略;
21、基于梯度的选择策略。
22、可选的,所述根据所述样本文本数据,对信息抽取模型进行迭代训练,还包括:
23、利用大语言模型,对所述样本文本进行信息抽取,得到第一预测样本实体和第一预测样本实体关系;
24、利用所述信息抽取模型,对所述样本文本进行信息抽取,得到第二预测样本实体和第二预测样本实体关系;
25、基于所述第一预测样本实体、所述第一预测样本实体关系、所述样本实体标签和所述样本实体关系标签,构造第一损失值;
26、基于所述第二预测样本实体、所述第二预测样本实体关系、所述样本实体标签和所述样本实体关系标签,构造第二损失值;
27、联合所述第一损失值和所述第二损失值,对所述信息抽取模型的模型参数进行更新。
28、可选的,所述目标领域为煤矿设备的故障诊断领域。
29、第二方面,本公开提供一种知识图谱构建装置,包括:
30、第一获取模块,被配置为获取与目标领域相关的目标文本数据;
31、第一抽取模块,被配置为将所述目标文本数据输入至训练完成的信息抽取模型,得到目标实体和目标实体间的实体关系;
32、第一构建模块,被配置为基于所述目标实体和所述目标实体关系,构建与所述目标领域相关的目标知识图谱;
33、其中,所述信息抽取模型通过以下方式训练:获取样本文本数据,所述样本文本数据包括样本文本、样本实体标签和样本实体关系标签,所述样本文本、所述样本实体标签和所述样本实体关系标签是对从包括多个领域知识的多源知识图谱中查询到的数据和通过问询大语言模型获得的数据进行处理所得到的;根据所述样本文本数据,对信息抽取模型进行训练。
34、第三方面,本公开提供一种非临时性计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现第一方面中任一项所述方法的步骤。
35、第四方面,本公开提供一种电子设备,包括:
36、存储器,其上存储有计算机程序;
37、处理器,用于执行所述存储器中的所述计算机程序,以实现第一方面中任一项所述方法的步骤。
38、第五方面,本公开提供一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现第一方面中任一项所述的方法的步骤。
39、通过上述技术方案,在训练信息抽取模型时,通过问询大语言模型和查询多源知识图谱样本文本数据,并基于样本文本数据信息用于抽取模型的训练,利用已有的大规模数据集或者其他相关领域的知识图谱数据来辅助目标领域所对应的信息抽取模型的训练,从而解决了因训练数据获取成本极高或训练数据难以大量获取的问题,实现了仅具备小规模数据的目标领域所对应的信息抽取模型的训练,提升了该信息抽取模型的性能。
40、本公开的其他特征和优点将在随后的具体实施方式部分予以详细说明。
技术特征:
1.一种知识图谱构建方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述方法还包括:
3.根据权利要求1所述的方法,其特征在于,所述方法还包括:
4.根据权利要求1所述的方法,其特征在于,所述方法还包括:
5.根据权利要求1所述的方法,其特征在于,所述方法还包括:
6.根据权利要求1所述的方法,其特征在于,所述根据所述样本文本数据,对信息抽取模型进行训练,包括:
7.根据权利要求6所述的方法,其特征在于,所述数据选择策略为以下策略中的任意一种:
8.根据权利要求6所述的方法,其特征在于,所述根据所述样本文本数据,对信息抽取模型进行迭代训练,还包括:
9.根据权利要求1所述的方法,其特征在于,所述目标领域为煤矿设备的故障诊断领域。
10.一种知识图谱构建装置,其特征在于,包括:
11.一种非临时性计算机可读存储介质,其上存储有计算机程序,其特征在于,该计算机程序被处理器执行时实现权利要求1-9中任一项所述方法的步骤。
12.一种电子设备,其特征在于,包括:
13.一种计算机程序产品,包括计算机程序,其特征在于,该计算机程序被处理器执行时实现权利要求1-9中任一项所述的方法的步骤。
技术总结
本公开涉及一种知识图谱构建方法、装置、介质、电子设备及程序产品,方法包括:获取与目标领域相关的目标文本数据;将目标文本数据输入至训练完成的信息抽取模型,得到目标实体和目标实体间的实体关系;基于目标实体和目标实体关系,构建与目标领域相关的目标知识图谱;其中,信息抽取模型通过以下方式训练:获取样本文本数据,样本文本数据包括样本文本、样本实体标签和样本实体关系标签,样本文本、样本实体标签和样本实体关系标签是对从包括多个领域知识的多源知识图谱中查询到的数据和通过问询大语言模型获得的数据进行处理所得到的,解决了因训练数据获取成本极高或训练数据难以大量获取的问题。
技术研发人员:张雄,奥帅,赵涵,李波,胡伟,尹成龙
受保护的技术使用者:国家能源集团国源电力有限公司
技术研发日:
技术公布日:2024/11/21
- 还没有人留言评论。精彩留言会获得点赞!