基于文本内容特征对齐的视频描述方法与系统
本发明属于计算机视觉与视频处理,特别涉及基于文本内容特征对齐的视频描述方法与系统。
背景技术:
1、视频描述是一个活跃的研究课题,目标是用自然语言句子描述视频内容。它具有广泛的应用,例如辅助视障人士、视频检索和人机交互。近年来,由于深度学习技术的推进和msr-vtt、msvd等大规模数据集的收集,视频字幕技术取得了显著进步。然而,由于视频本身包含各种各样的对象、事件和复杂的场景,注释者很难用一句话全面地描述视频,因此每个视频常常会有多个描述,以减轻注释偏差。为了更准确地理解视频与描述之间的关系,研究人员不断探索先进的模型架构。尽管现有模型取得了进步,但仍面临一个关键问题:即监督是模棱两可的问题,也被称为“一对多”的问题,这归根到底源于视频与字幕对齐不足。
2、为了解决这一问题,最新的研究方法试图通过屏蔽与文本相似度较低的视频帧来实现视频文本对齐。但是,这种方法在操作过程中可能会导致大量空间细节的丢失,且主要用于跨模态检索任务,不能直接应用于视频字幕生成任务。
3、如上所述,基于视频文本对齐仍缺少可靠的方法,直接影响视频描述的精准性。基于此,有必要提出一种新的方法实现视频文本对齐,提升字幕质量,以解决上述技术问题。
技术实现思路
1、鉴于上述状况,本发明的主要目的是为了提出基于文本内容特征对齐的视频描述方法,以解决上述技术问题。
2、本发明提供了基于文本内容特征对齐的视频描述方法,所述方法包括如下步骤:
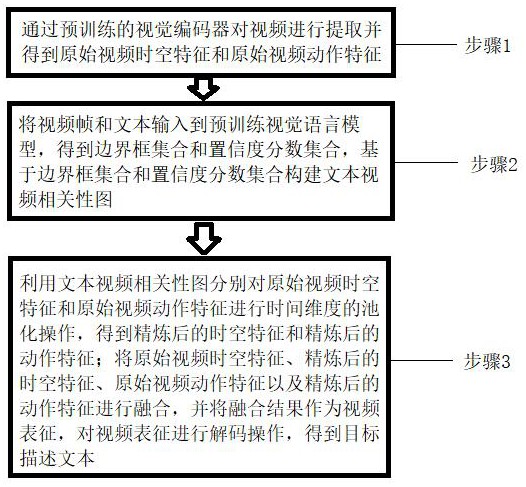
3、步骤1、通过预训练的视觉编码器对视频进行提取并得到原始视频时空特征和原始视频动作特征;
4、步骤2、将视频帧和文本输入到预训练视觉语言模型,得到边界框集合和置信度分数集合,基于边界框集合和置信度分数集合构建文本视频相关性图;
5、步骤3、利用文本视频相关性图分别对原始视频时空特征和原始视频动作特征进行时间维度的池化操作,得到精炼后的时空特征和精炼后的动作特征;
6、将原始视频时空特征、精炼后的时空特征、原始视频动作特征以及精炼后的动作特征进行融合,并将融合结果作为视频表征,对视频表征进行解码操作,得到目标描述文本。
7、本发明还提出基于文本内容特征对齐的视频描述系统,所述系统包括:
8、特征提取模块,通过预训练的视觉编码器对视频进行提取并得到原始视频时空特征和原始视频动作特征;
9、相关性图构建模块,将视频帧和文本输入到预训练视觉语言模型,得到边界框集合和置信度分数集合,基于边界框集合和置信度分数集合构建文本视频相关性图;
10、描述文本生成模块,利用文本视频相关性图分别对原始视频时空特征和原始视频动作特征进行时间维度的池化操作,得到精炼后的时空特征和精炼后的动作特征;将原始视频时空特征、精炼后的时空特征、原始视频动作特征以及精炼后的动作特征进行融合,并将融合结果作为视频表征,对视频表征进行解码操作,得到目标描述文本。
11、与现有技术相比,本发明有益效果如下:
12、1、本发明以文本内容为条件,结合视频帧来构建文本视频相关性图,并与视频时空特征和视频动作特征进行融合来优化视频表征,不仅提供多样化的视频表示,还抑制多余或分散注意力的视觉信息和动作信息,实现视频文本对齐,生成目标描述文本。
13、2、本发明的附加方面与优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实施例了解到。
14、本发明的附加方面与优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实施例了解到。
技术特征:
1.一种基于文本内容特征对齐的视频描述方法,其特征在于,所述方法包括如下步骤:
2.根据权利要求1所述的一种基于文本内容特征对齐的视频描述方法,其特征在于,在所述步骤1中,通过预训练的视觉编码器对视频进行提取并得到原始视频时空特征和原始视频动作特征,具体步骤如下;
3.根据权利要求2所述的一种基于文本内容特征对齐的视频描述方法,其特征在于,在所述步骤2中,将视频帧和文本输入到预训练视觉语言模型,得到边界框集合和置信度分数集合,基于边界框集合和置信度分数集合构建文本视频相关性图,具体步骤为:
4.根据权利要求3所述的一种基于文本内容特征对齐的视频描述方法,其特征在于,为视频中每一帧构建空白图片,过程存在如下关系式:
5.根据权利要求4所述的一种基于文本内容特征对齐的视频描述方法,其特征在于,在所述步骤3中,利用文本视频相关性图分别对原始视频时空特征和原始视频动作特征进行时间维度的池化操作,得到精炼后的时空特征和精炼后的动作特征,具体步骤如下:
6.根据权利要求5所述的一种基于文本内容特征对齐的视频描述方法,其特征在于,对文本视频相关性图进行帧级别的平均池化操作,得到池化后的文本视频相关性图,利用池化后的文本视频相关性图对原始视频动作特征进行时间维度的池化操作,得到精炼后的动作特征,过程存在如下关系式:
7.根据权利要求6所述的一种基于文本内容特征对齐的视频描述方法,其特征在于,在所述步骤3中,将原始视频时空特征、精炼后的时空特征、原始视频动作特征以及精炼后的动作特征进行融合是采用拼接操作实现的,对应的关系式如下:
8.根据权利要求7所述的一种基于文本内容特征对齐的视频描述方法,其特征在于,在所述步骤3中,解码操作采用的是transformer解码器。
9.一种基于文本内容特征对齐的视频描述系统,其特征在于,所述系统应用如上述权利要求1至8任意一项所述的基于文本内容特征对齐的视频描述方法,所述系统包括:
技术总结
本发明提出基于文本内容特征对齐的视频描述方法与系统,该方法包括:通过预训练的视觉编码器对视频进行提取并得到原始视频时空特征和原始视频动作特征;将视频帧和文本输入到预训练视觉语言模型,得到边界框集合和置信度分数集合,基于边界框集合和置信度分数集合构建文本视频相关性图;利用文本视频相关性图得到精炼后的时空特征和精炼后的动作特征;基于原始视频时空特征、精炼后的时空特征、原始视频动作特征以及精炼后的动作特征得到目标描述文本。本发明以文本为条件,结合视频帧来构建文本视频相关性图,并与视频时空特征和视频动作特征进行融合来优化视频表征,以达到视频文本对齐的效果。
技术研发人员:姜文晖,官文彬,黎海军,方玉明,冯佳辉,陈俊杰
受保护的技术使用者:江西财经大学
技术研发日:
技术公布日:2024/9/12
- 还没有人留言评论。精彩留言会获得点赞!