一种内存多线程模糊检索方法与流程
本发明涉及模糊检索,特别是涉及一种内存多线程模糊检索方法。
背景技术:
1、模糊检索是一种利用字符串相似度值进行检索的方法,它解决了完全匹配检索的限制,大大提高检索结果的召回率。模糊检索常用于电商产品名称词条检索、百科知识词条检索等场景中,通过模糊检索技术,能够对用户搜索词中的错别字、不准确的搜索词也能得到很好的检索结果。
2、当前数据模糊检索主要包括数据库模糊匹配,搜索引擎全文检索等。
3、数据检索包括数据筛选与数据排序。在数据库检索中,常见的数据库如mysql、sqlserver、oracle等检索主要采用索引方式,根据用户的检索词以及排序条件实现相似数据查找与排序;在搜索引擎检索中,目前主流的搜索引擎如solr、elasticsearch等采用全文检索加tf/idf倒排索引可实现数据检索加排序功能。
4、当数据库存储数据达到百万甚至千万级时,数据库建立的索引需要占用大量的磁盘空间,检索效率也会随着数据增大变得越来越慢;采用搜索引擎技术,需要额外维护一套搜索引擎软件,且搜索引擎常采用分布式部署,对硬件资源也有一定的要求。
技术实现思路
1、鉴于传统数据库检索慢,搜索引擎硬件要求高以及维护成本高等问题,本发明提供了一种内存多线程模糊检索方法,能够实现数据高效、快速检索,具有较高的应用价值。
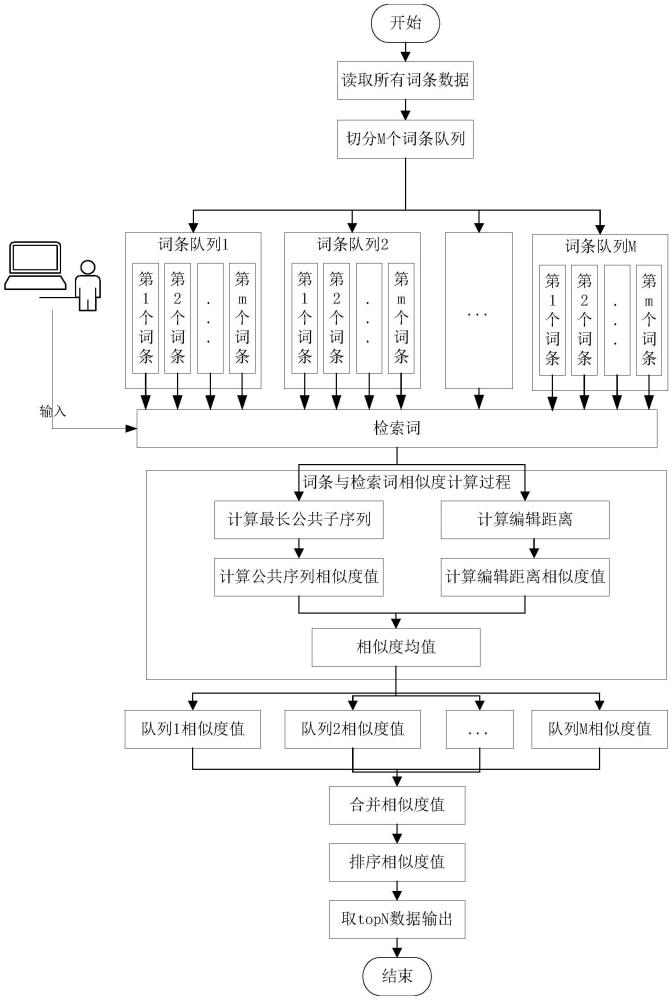
2、本发明公开了一种内存多线程模糊检索方法,其包括:
3、步骤1:采用多线程并行运算的方式分别计算词条与用户检索词的编辑距离相似度值和公共序列相似度值;
4、步骤2:求取每个词条与检索词对应的编辑距离相似度值和公共序列相似度值的均值并对其进行排序,从中选取前n个字符串作为模糊检索结果。
5、进一步地,所述步骤1包括:
6、获取词条数据,并将词条数据切分成m份,形成m个词条队列;
7、根据用户输入的检索词,申请m个线程池,每个线程池对应一个词条队列,计算每个线程池的词条队列中每个词条与检索词的最长公共子序列长度以及公共子序列相似度值;计算每个线程池的词条队列中每个词条与检索词的编辑距离以及编辑距离相似度值。
8、进一步地,采用动态规划方法计算词条与检索词之间的最长公共子序列,其具体步骤为:
9、步骤101:构造一个二维数组result[i][j],表示字符串s1以第i个字符结尾,字符串s2以第j个字符结尾的最长公共子序列长度;字符串s1表示词条,字符串s2表示检索词;
10、步骤102:初始化result数组中每个元素都为0;
11、步骤103:递归计算result[i][j]的值,当s1[i]=s2[j]时,result[i][j]=
12、result[i-1][j-1]+1,否则result[i][j]=0;递归过程中,记录result[i][j]最大值以及索引位置,即可得到最长公共子序列以及长度值。
13、进一步地,根据每个词条与检索词的最长公共子序列长度以及每个词条与检索词的长度,得到每个词条与检索词的公共子序列相似度值。
14、进一步地,所述每个词条与检索词的公共子序列相似度值的计算公式为:
15、
16、其中,sim_lcs(s1,s2)为词条s1与检索词s2的公共子序列相似度值,lcs(s1,s2)表示s1、s2两个字符串的最长公共子序列长度,len()表示字符串的长度,sim_lcs的取值范围为[0,1]。
17、进一步地,所述步骤2包括:
18、计算m个词条队列中每个词条对应的公共子序列相似度值与编辑距离相似度值的均值,将m个词条队列中的所有词条对应的相似度均值按照从大到小的顺序排序,取出前n个最大相似度值作为模糊检索结果。
19、进一步地,采用动态规划方法计算编辑距离,其具体步骤为:
20、步骤201:构造一个二维数组edit[i][j],表示字符串s1以第i个字符结尾,字符串s2以第j个字符结尾的最小编辑距离;符串s1为词条,字符串s2为检索词;
21、步骤202:按以下公式对edit[i][j]数组进行赋值;
22、
23、其中,
24、
25、步骤203:取edit[i][j]数组右下角的值作为编辑距离。
26、进一步地,根据每个词条与检索词的编辑距离以及每个词条与检索词的长度,得到每个词条与检索词的编辑距离相似度值。
27、进一步地,编辑距离相似度的计算公式为:
28、
29、其中,edit(s1,s2)表示词条s1、检索词s2两个字符串的编辑距离,len()表示字符串的长度,sim_edit的取值范围为[0,1]。
30、进一步地,所述步骤2包括:
31、合并所有线程的相似度均值,并按照从大到小排序,根据用户检索要求,取出排名前n个数据输出,并释放m个线程。
32、由于采用了上述技术方案,本发明具有如下的优点:
33、1、与单独采用编辑距离或者最长公共子序列长度的检索结果相比,本发明结合了最长公共子序列长度的排序以及最短编辑距离的排序,使最终的排序结果更合理,效果更好,同时采用多线程的方式进行并行计算,极大地提高了检索效率。
34、2、硬件与维护成本低。该检索方法可以封装成函数集成到项目中,无需维护额外的软件,减少外部依赖,也无需采用大数据框架,增加服务器进行分布式部署。
35、3、检索速度快。该检索方法采用多线程的方式进行并发计算,计算结果准确,速度快。
36、4、检索结果好。该检索方法结合了最长公共子序列与编辑距离的优点,解决了最长公共子序列只按长度排序和编辑距离只按距离排序的缺点,使得排序结果更合理,效果更好。
37、5、本发明在不依赖大数据检索组件(如es、solr)的情况下,对用户输入的检索词,能够在极短的时间内从百万级甚至千万级词条中高效搜索出可靠的结果。
技术特征:
1.一种内存多线程模糊检索方法,其特征在于,包括:
2.根据权利要求1所述的内存多线程模糊检索方法,其特征在于,所述步骤1包括:
3.根据权利要求2所述的内存多线程模糊检索方法,其特征在于,采用动态规划方法计算词条与检索词之间的最长公共子序列,其具体步骤为:
4.根据权利要求2所述的内存多线程模糊检索方法,其特征在于,根据每个词条与检索词的最长公共子序列长度以及每个词条与检索词的长度,得到每个词条与检索词的公共子序列相似度值。
5.根据权利要求4所述的内存多线程模糊检索方法,其特征在于,所述每个词条与检索词的公共子序列相似度值的计算公式为:
6.根据权利要求1所述的内存多线程模糊检索方法,其特征在于,所述步骤2包括:
7.根据权利要求1所述的内存多线程模糊检索方法,其特征在于,采用动态规划方法计算编辑距离,其具体步骤为:
8.根据权利要求1所述的内存多线程模糊检索方法,其特征在于,根据每个词条与检索词的编辑距离以及每个词条与检索词的长度,得到每个词条与检索词的编辑距离相似度值。
9.根据权利要求8所述的内存多线程模糊检索方法,其特征在于,编辑距离相似度的计算公式为:
10.根据权利要求2所述的内存多线程模糊检索方法,其特征在于,所述步骤2包括:
技术总结
本发明公开了一种内存多线程模糊检索方法,其包括:采用多线程并行运算的方式分别计算词条与用户检索词的编辑距离相似度值和公共序列相似度值;求取每个词条与检索词对应的编辑距离相似度值和公共序列相似度值的均值并对其进行排序,从中选取前N个字符串作为模糊检索结果。本发明在不依赖大数据检索组件的情况下,能够针对用户输入的检索词在极短的时间内从百万级甚至千万级词条中高效搜索出可靠的结果。
技术研发人员:景亮,张永红,蒋嘉健,刘远航,胡益
受保护的技术使用者:电信科学技术第五研究所有限公司
技术研发日:
技术公布日:2025/1/6
- 还没有人留言评论。精彩留言会获得点赞!