规则识别方法、装置、电子设备、存储介质及程序产品与流程
本申请涉及计算机 ,尤其涉及一种规则识别方法、装置、电子设备、存储介质及程序产品。
背景技术:
1、面对互联网上的海量数据,使用互联网爬虫技术来获取数据已经成为大数据分析和数据挖掘的必然趋势,而网络爬虫技术的本质是通过自动化程序模拟人类在互联网上的浏览行为,从而收集和提取特定网站上的信息。其中,通过配置网页的xpath(xml pathlanguage,可扩展标记语言路径语言)规则或正则表达式来获取特定网站上的信息是关键技术。因此如何快速的配置种子网站的xpath规则是自动化数据采集的研究方向之一。
2、在相关技术中,大多通过人工识别并配置网页的xpath规则来实现对公开信源网站的数据采集,通过客户端将人工配置的xpath规则同步到爬虫服务端进行规则管理,爬虫工具可读取爬虫服务端的xpath规则进行数据采集。
3、但是,通过人工识别xpath规则的方法效率低,且容易出现人为错误。
技术实现思路
1、本申请实施例提供一种规则识别方法、装置、电子设备、存储介质及程序产品,用以解决现有的人工识别xpath规则的方法效率低,且容易出现人为错误的技术问题。
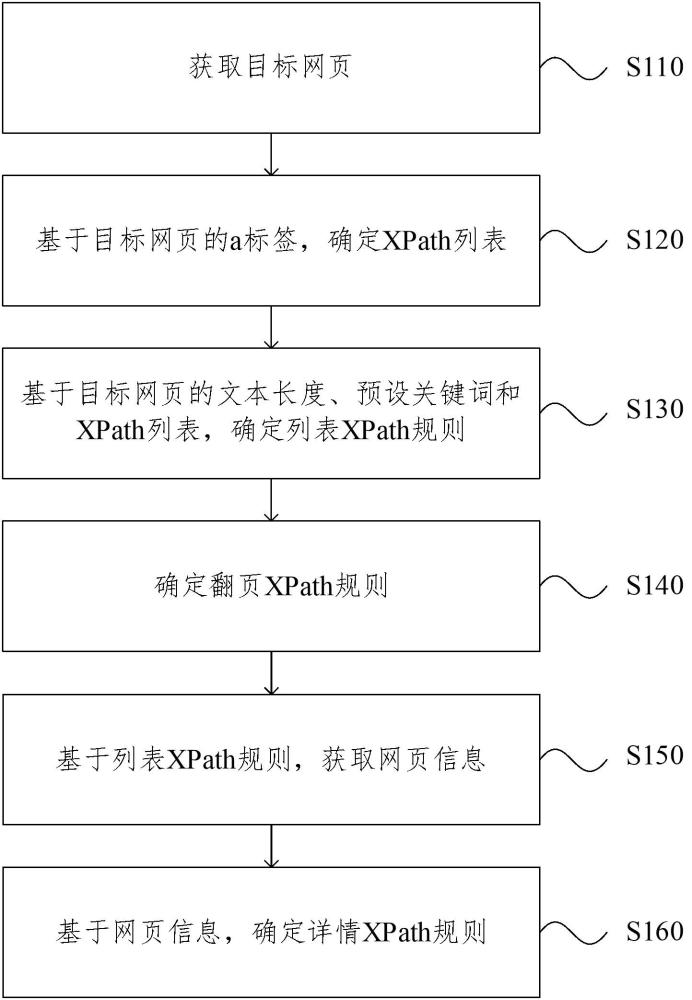
2、第一方面,本申请实施例提供一种规则识别方法,包括:获取目标网页;基于目标网页的a标签,确定xpath列表;基于目标网页的文本长度、预设关键词和xpath列表,确定列表xpath规则;确定翻页xpath规则;基于列表xpath规则,获取网页信息;基于网页信息,确定详情xpath规则。
3、在一个实施例中,基于目标网页的a标签,确定xpath列表,包括:基于目标网页的a标签和a标签所在的文本,递归获取a标签的父元素;确定父元素的每一子元素;确定每一子元素的层级结构;基于父元素、每一子元素和每一子元素的层级结构,确定xpath列表。
4、在一个实施例中,基于目标网页的文本长度、预设关键词和xpath列表,确定列表xpath规则,包括:基于目标网页的文本长度和预设关键词,从xpath列表中过滤出匹配的xpath规则,生成xpath规则集合;对xpath规则集合进行泛化,获得泛化xpath规则集合;对泛化xpath规则集合中的xpath簇进行计数,获得泛化xpath规则集合中每一xpath簇的计数结果,并对每一xpath簇的计数结果依次排序,提取计数结果最大的xpath簇作为最优xpath规则;基于最优xpath规则,在xpath列表中寻找匹配的xpath规则,并基于xpath列表中匹配的xpath规则,组合生成列表规则;基于最优xpath规则,查找class属性和/或id属性符合条件的目标xpath规则,并基于目标xpath规则,对列表规则进行替换组合,生成列表xpath规则。
5、在一个实施例中,翻页xpath规则包括第一翻页规则和第二翻页规则,第一翻页规则为基于get请求的翻页规则,第二翻页规则为基于post请求的翻页规则;确定翻页xpath规则,包括:确定目标网页中包含连续数字的待识别标签;判断待识别标签是否为a标签;若待识别标签是a标签,则获取待识别标签的url,并基于待识别标签的url,确定第一翻页规则;若待识别标签不是a标签,则基于待识别标签的标签属性特征,确定第二翻页规则。
6、在一个实施例中,网页信息包括详情网页url、列表标题和发布时间;基于列表xpath规则,获取网页信息,包括:基于列表xpath规则,获取详情网页url;将列表xpath规则所在的a标签的文本作为列表标题;获取列表xpath规则所在的a标签的所有兄弟元素和每一兄弟元素的文本;基于每一兄弟元素和每一兄弟元素的文本,通过时间正则表达式获取发布时间。
7、在一个实施例中,基于网页信息,确定详情xpath规则,包括:基于详情网页url,下载详情网页;基于列表标题,确定详情网页中的标题元素位置;基于发布时间,确定详情网页中的发布时间位置;基于标题元素位置和发布时间位置,获取详情网页中的第一正文元素;基于正文标签属性特征,确定详情网页中的第二正文元素;基于标签密度算法,确定详情网页中的第三正文元素;基于预设业务关键词,确定详情网页中的第四正文元素;基于第一正文元素、第二正文元素、第三正文元素和第四正文元素,确定详情xpath规则。
8、第二方面,本申请实施例提供一种规则识别装置,包括:获取模块,用于获取目标网页;列表规则确定模块,用于基于目标网页的a标签,确定xpath列表;基于目标网页的文本长度、预设关键词和xpath列表,确定列表xpath规则;翻页规则确定模块,用于确定翻页xpath规则;详情规则确定模块,用于基于列表xpath规则,获取网页信息;基于网页信息,确定详情xpath规则。
9、第三方面,本申请实施例提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现如上述任一种规则识别方法。
10、第四方面,本申请实施例提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种规则识别方法。
11、第五方面,本申请实施例提供一种计算机程序产品,包括计算机程序,计算机程序被处理器执行时实现如上述任一种规则识别方法。
12、本申请实施例提供的规则识别方法、装置、电子设备、存储介质及程序产品,获取目标网页;基于目标网页的a标签,确定xpath列表;基于目标网页的文本长度、预设关键词和xpath列表,确定列表xpath规则;确定翻页xpath规则;基于列表xpath规则,获取网页信息;基于网页信息,确定详情xpath规则。通过上述方式,可实现xpath规则的自动识别,无需人工操作,可提高xpath规则的识别效率,避免出现人为错误。
技术特征:
1.一种规则识别方法,其特征在于,包括:
2.根据权利要求1所述的规则识别方法,其特征在于,所述基于所述目标网页的a标签,确定xpath列表,包括:
3.根据权利要求2所述的规则识别方法,其特征在于,所述基于所述目标网页的文本长度、预设关键词和所述xpath列表,确定列表xpath规则,包括:
4.根据权利要求1所述的规则识别方法,其特征在于,所述翻页xpath规则包括第一翻页规则和第二翻页规则,所述第一翻页规则为基于get请求的翻页规则,所述第二翻页规则为基于post请求的翻页规则;
5.根据权利要求1所述的规则识别方法,其特征在于,所述网页信息包括详情网页url、列表标题和发布时间;
6.根据权利要求5所述的规则识别方法,其特征在于, 所述基于所述网页信息,确定详情xpath规则,包括:
7.一种规则识别装置,其特征在于,包括:
8.一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至6任一项所述规则识别方法。
9.一种非暂态计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至6任一项所述规则识别方法。
10.一种计算机程序产品,包括计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至6任一项所述规则识别方法。
技术总结
本申请涉及计算机技术领域,提供一种规则识别方法、装置、电子设备、存储介质及程序产品。方法包括:获取目标网页;基于目标网页的a标签,确定XPath列表;基于目标网页的文本长度、预设关键词和XPath列表,确定列表XPath规则;确定翻页XPath规则;基于列表XPath规则,获取网页信息;基于网页信息,确定详情XPath规则。通过上述方式,可实现XPath规则的自动识别,无需人工操作,可提高XPath规则的识别效率,避免出现人为错误。
技术研发人员:宋保国,张勇,刘浩,赵济朋,韩盈盈,张孝,白江龙,鄢邦杰,郑书芳,王楠
受保护的技术使用者:中移在线服务有限公司
技术研发日:
技术公布日:2024/12/19
- 还没有人留言评论。精彩留言会获得点赞!