一种基于深度网络迁移学习的藏文古籍文档字符识别方法
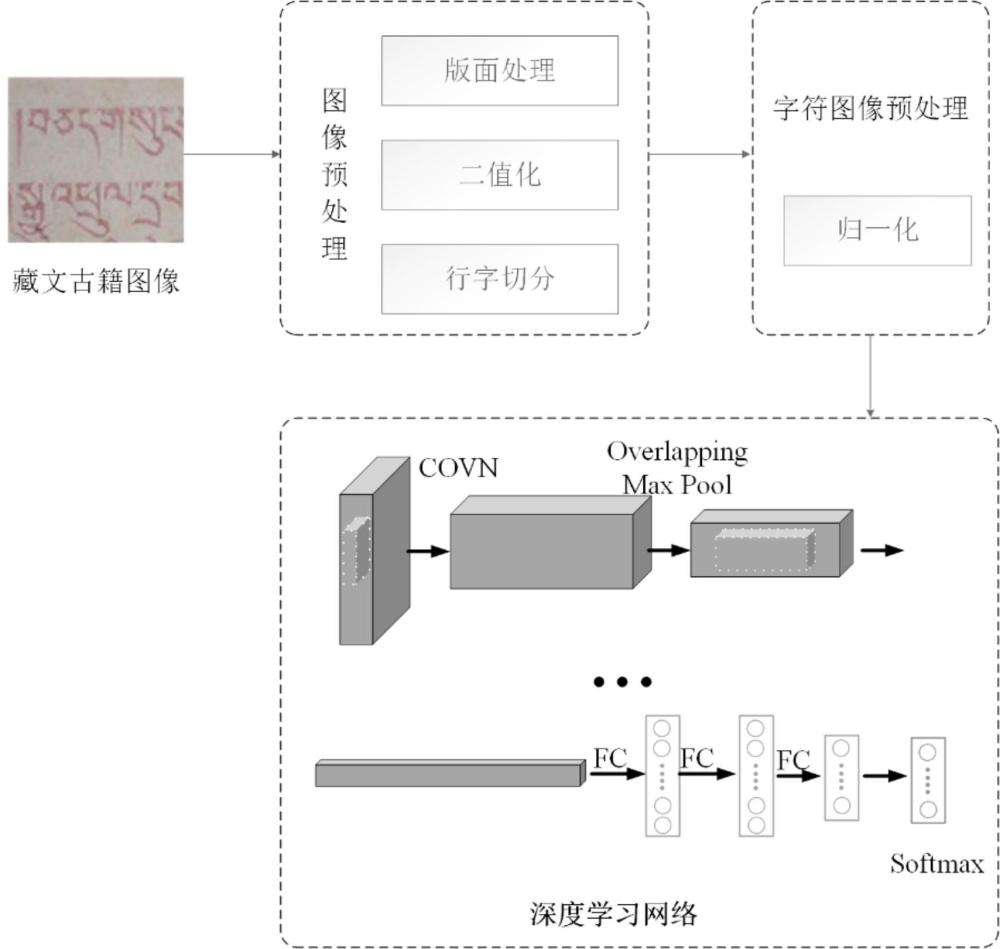
本发明涉及深度学习的藏文文字图像识别,具体是一种基于深度网络迁移学习的藏文古籍文档字符识别方法。
背景技术:
1、然而,由于时间和环境的影响,许多藏文古籍已经受损或陈旧,无法长期保存和利用。为了保护和利用这些宝贵的文化遗产,数字化保护成为必要措施。通过对藏文古籍文档图像的分析与识别,可以将古籍内容重新排版印刷,在尽可能保持原貌的同时实现永久保存和永续利用。
2、基于cnn和rnn的深度学习方法已经初步用在藏文数字识别、藏文印刷体识别和自然场景藏文识别上,并取得了一定的成绩。但是,现有的深度学习识别方法依赖于大量的有标注数据,直接使用少量标注样本训练深度模型极易发生过拟合,获取大量的有标注图像需要巨大的标注代价,目前没有公开的有标记的藏文古籍文档字符图像样本集可供使用。且样本库不同类别数量极不平衡,部分样本类别数量极少。通过旋转缩放等方式来平衡数据集类别数量,以此来训练网络模型,总体样本数量较少,特征丰富性不足,直接训练的识别模型泛化性和鲁棒性不理想。因此,研究面向零样本、无监督的藏文古籍文档图像字符识别成为了当下重要的研究问题。
技术实现思路
1、本发明的目的在于提供一种基于深度网络迁移学习的藏文古籍文档字符识别方法,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:
3、一种基于深度网络迁移学习的藏文古籍文档字符识别方法,1.构造藏文估计字符图像数据集,根据自上而下、自左至右以及首选组合部件原则拆分藏文字符为多个部件。利用这些部件及其位置信息,可以通过随机旋转等方式合成藏文字符图像数据集,使其更接近于真实的藏文古籍文档图像。
4、一种基于深度网络迁移学习的藏文古籍文档字符识别方法,其特征在于,包括以下步骤:
5、s1、构造藏文估计字符图像数据集:根据自上而下、自左至右以及首选组合部件原则拆分藏文字符为多个部件。利用这些部件及其位置信息,可以通过随机旋转等方式合成藏文字符图像数据集,使其更接近于真实的藏文古籍文档图像。
6、s2、图像处理:将真实的藏文古籍字符图像通过二值化、行切分及字切分等步骤。对提取的字符图像进行预处理、筛选、切分和归一化,最终得到111932个尺寸为32×64的字符图像。
7、s3、样本增强:对前期构建的409类111932个藏文古籍字符图像数据集样本空间,通过旋转缩放等方式对数据集样本的不平衡情况进行样本增强。
8、s4、迁移学习模型:通过复制二值化图像扩展图像为rgb三通道图像,基于imagenet上预训练alexnet网络,通过迁移学习深度网络框架结构及浅层权重参数,获得性能最优的网络模型,对藏文字符进行迁移识别。
9、s5、网络训练:系统训练在具有较高计算能力的硬件环境下进行,包括cpu为intel(r)xeon(r)和320g内存的传统识别方法环境。通过数据增强和调整学习率,训练所得模型在不同类别的字符识别上均表现出较高的准确率。
10、与现有技术相比,本发明的有益效果是:
11、(1)针对藏文样本各类别数量不均衡且许多类别样本数量极少的问题,使用旋转方式平衡类别数量并基于imagenet数据集预训练的深度学习网络。
12、(2)将所得网络框架结构及参数使用迁移学习方式迁移到藏文古籍字符图像识别。通过随机梯度下降算法训练网络,网络收敛速度快,具有良好的可扩展性。
技术特征:
1.一种基于深度网络迁移学习的藏文古籍文档字符识别方法,其特征在于,包括以下步骤:
技术总结
本发明公开了一种基于深度网络迁移学习的藏文古籍文档字符识别方法。本发明将深度网络迁移学习应用于藏文古籍字符的识别中,首先基于ImageNet数据集训练深度神经网络,再将网络迁移至藏文古籍字符图像样本集训练。由于此样本集不同字符类别数量存在严重不平衡性,直接训练容易丢失数量较少类别的图像特征。为此,通过旋转和缩放等方式对个数较少类别进行数据增广,以平衡类别间相对数量。在此数据集上,通过迁移预训练的深度网络模型结构,并迁移网络权值作为训练初值,通过调整学习率变化策略并训练,所得模型测试集首选识别率达到96.97%。并通过计算优化迁移策略进一步提升识别率。
技术研发人员:王筱娟,王维兰,王铁君,蔡正琦,赵彦
受保护的技术使用者:西北民族大学
技术研发日:
技术公布日:2024/11/26
- 还没有人留言评论。精彩留言会获得点赞!