一种多样性的语义分布匹配数据压缩方法和系统
本发明属于信息,具体涉及一种多样性的语义分布匹配数据压缩方法和系统。
背景技术:
1、在大数据时代,数据量的指数级增长不仅给存储带来了巨大的压力,也增加了模型训练的显著开销。因此,如何将大规模数据压缩成一个紧凑且具有丰富信息的子集,以在促进训练程序的同时保持相似的性能,成为一个亟待解决的重要问题。为此,一个直观的方法是从原始数据集中选择具有代表性的实例作为核心集。然而,样本选择过程中直接丢弃大部分实例可能导致关键底层信息的丢失,这对于模型训练至关重要。幸运的是,数据压缩技术被提出作为一种解决方案,可以将原始大规模数据集压缩成更小的合成数据集,同时确保在合成数据集上训练的模型能表现出与在原始数据集上训练相当的性能。
2、现有的数据集压缩方法一般可分为两大类:基于优化的方法和基于分布匹配的方法。(1)基于优化的方法:该方法采用双层优化过程,其中模型首先利用原始数据集进行更新,然后通过最小化距离来优化合成的数据集,以实现原始数据和合成数据之间的良好匹配。(2)基于分布匹配的方法:该方法通过消除模型更新来提高训练效率,直接通过在合成数据集和原始数据集上使用随机初始化模型计算出的相应类中心来优化合成数据。
3、现有技术的缺点如下:
4、1)基于优化的方法:基于优化的方法在模型训练过程中将从原始数据集中学习到的信息集成到合成数据集中。为实现这一目标,需要对模型和合成数据集进行迭代的双层优化,通过元学习来模拟模型的训练过程,从而生成合成实例。在这一框架下,已有多种方法被提出以优化合成实例,这些方法包括匹配训练轨迹、利用数据幻觉网络构建样本特征,以及通过聚类选择原始样本特征。尽管这些方法在提升合成数据性能方面取得了一定的进展,但由于仍需采用双层优化范式,交替更新模型和合成数据,因此导致优化难度加大且耗时较长。
5、2)基于分布匹配的方法:基于分布匹配的方法利用合成数据集的分布与真实数据集的分布在特征空间中对齐,从而避免了模型更新,省去了双层优化的复杂性。然而,仅在特征空间中的类中心对齐会忽略原始数据集的语义多样性,可能导致合成数据的过度简化。
技术实现思路
1、本发明针对上述问题,提供一种多样性的语义分布匹配数据压缩方法和系统。本发明遵循基于分布匹配的框架,从语义信息的角度出发,充分考虑了语义信息,以增强压缩的合成实例的语义多样性。
2、本发明采用的技术方案如下:
3、一种多样性的语义分布匹配数据压缩方法,包括以下步骤:
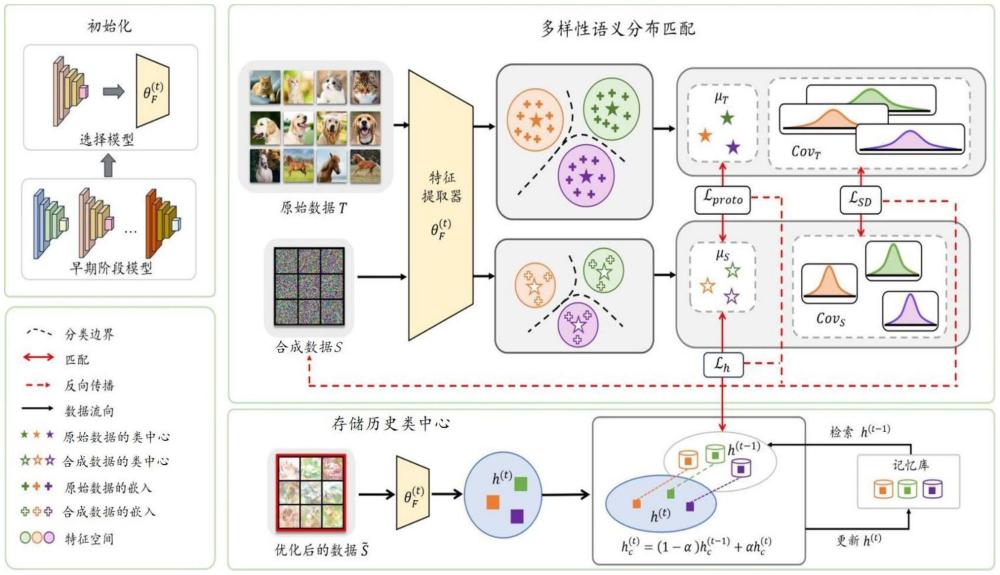
4、在原始数据集上预训练一组模型,得到预训练模型;
5、利用预训练模型提取的语义嵌入将原始数据集中的每个类别建模为高斯分布,其中类中心表示类别的固有特征,协方差矩阵表示类别中实例的语义变化;
6、将合成数据集与原始数据集进行类中心对齐和协方差矩阵对齐;
7、利用多个预训练模型对合成数据集进行优化,通过记忆库存储由先前预训练模型优化的合成数据集的类中心,即历史类中心;
8、将当前预训练模型优化的合成数据集的类中心与历史类中心进行对齐,得到语义多样化的合成数据集。
9、进一步地,对于原始数据集其中(xi,yi)表示原始数据样本,yi∈l={l1,l2,…,lc},l是类别的集合,c表示类别的数量,表示原始数据的样本数,为每个类别压缩ipc实例lc,得到合成数据集其中(sj,yj)表示合成数据样本,表示合成数据的样本数;使用从原始数据集中随机选择的实例对合成数据集进行初始化;使用特征提取器和嵌入函数g为合成数据集和原始数据集中的每个实例提取特征,提取的特征用和表示,然后使用提取的特征计算类中心μs和μt,以及和中每个类别的协方差矩阵covs和covt。
10、进一步地,所述类中心对齐是利用欧几里得距离将的类中心μt,c与的类中心μs,c对齐,其采用的类中心对齐损失函数为:
11、
12、其中,表示在和中从同一类别lc中抽取的一批数据。
13、进一步地,所述协方差矩阵对齐用于捕获语义多样性,采用的协方差矩阵对齐损失函数为:
14、
15、其中,(m,n)表示协方差矩阵的位置,covt,c(m,n)代表每个批次原始数据的协方差矩阵的每个元素,covs,c(m,n)代表每个批次合成数据的协方差矩阵的每个元素。
16、进一步地,所述将当前预训练模型优化的合成数据集的类中心与历史类中心进行对齐,采用的历史类中心对齐损失函数为:
17、
18、其中表示历史类中心。
19、进一步地,采用以下步骤更新记忆库中的历史类中心:
20、首先使用特征提取器对合成数据在第t次优化后计算类中心
21、
22、其中表示经过t次优化后的类别lc的合成数据,表示优化后的合成数据实例;
23、然后更新记忆库中的历史类中心:
24、
25、其中α是平滑因子。
26、进一步地,将类中心对齐损失函数协方差矩阵对齐损失函数和历史类中心对齐损失函数结合起来,得到总损失函数,即多样化语义分布匹配损失函数。
27、一种多样性的语义分布匹配数据压缩系统,其包括:
28、预训练模块,用于在原始数据集上预训练一组模型,得到预训练模型;
29、特征提取模块,用于利用预训练模型提取的语义嵌入将原始数据集中的每个类别建模为高斯分布,其中类中心表示类别的固有特征,协方差矩阵表示类别中实例的语义变化;
30、类中心和协方差矩阵对齐模块,用于将合成数据集与原始数据集进行类中心对齐和协方差矩阵对齐;
31、历史类中心对齐模块,用于利用多个预训练模型对合成数据集进行优化,通过记忆库存储由先前预训练模型优化的合成数据集的类中心,即历史类中心,将当前预训练模型优化的合成数据集的类中心与历史类中心进行对齐,得到语义多样化的合成数据集。
32、本发明的有益效果是:本发明提出了一种多样化语义分布匹配数据压缩方法,该方法通过从语义分布的角度对特征进行对齐,显著增强了合成数据的语义多样性。为了确保优化合成数据过程的稳定,本发明深入分析了不同模型在特征空间分布上的差异,将当前合成数据的类中心与历史优化的合成数据进行对齐。这种对齐策略不仅提升了特征的表达能力,还有效地减少了特定模型的过拟合,从而改进了整体性能。本发明进行了一系列详尽的实验,以验证本发明在图像和语音数据集上的有效性。结果表明,通过实施本方法,模型在多种场景下展现出了最先进的性能和卓越的泛化能力。
技术特征:
1.一种多样性的语义分布匹配数据压缩方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的方法,其特征在于,对于原始数据集其中(xi,yi)表示原始数据样本,yi∈l={l1,l2,…,lc},l是类别的集合,c表示类别的数量,表示原始数据的样本数,为每个类别压缩ipc实例lc,得到合成数据集其中(sj,yj)表示合成数据样本,表示合成数据的样本数;使用从原始数据集中随机选择的实例对合成数据集进行初始化;使用特征提取器和嵌入函数g为合成数据集和原始数据集中的每个实例提取特征,提取的特征用和表示,然后使用提取的特征计算类中心μs和μt,以及和中每个类别的协方差矩阵covs和covt。
3.根据权利要求2所述的方法,其特征在于,所述类中心对齐是利用欧几里得距离将的类中心μt,c与的类中心μs,c对齐,其采用的类中心对齐损失函数为:
4.根据权利要求3所述的方法,其特征在于,所述协方差矩阵对齐用于捕获语义多样性,采用的协方差矩阵对齐损失函数为:
5.根据权利要求4所述的方法,其特征在于,所述将当前预训练模型优化的合成数据集的类中心与历史类中心进行对齐,采用的历史类中心对齐损失函数为:
6.根据权利要求5所述的方法,其特征在于,采用以下步骤更新记忆库中的历史类中心:
7.根据权利要求1所述的方法,其特征在于,将类中心对齐损失函数协方差矩阵对齐损失函数和历史类中心对齐损失函数结合起来,得到总损失函数,即多样化语义分布匹配损失函数。
8.一种多样性的语义分布匹配数据压缩系统,其特征在于,包括:
9.一种计算机设备,其特征在于,包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行权利要求1~7中任一项所述方法的指令。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储计算机程序,所述计算机程序被计算机执行时,实现权利要求1~7中任一项所述的方法。
技术总结
本发明涉及一种多样性的语义分布匹配数据压缩方法和系统。该方法包括:在原始数据集上预训练一组模型,得到预训练模型;利用预训练模型提取的语义嵌入将原始数据集中的每个类别建模为高斯分布,其中类中心表示类别的固有特征,协方差矩阵表示类别中实例的语义变化;将合成数据集与原始数据集进行类中心对齐和协方差矩阵对齐;利用多个预训练模型对合成数据集进行优化,通过记忆库存储由先前预训练模型优化的合成数据集的历史类中心;将当前预训练模型优化的合成数据集的类中心与历史类中心进行对齐,得到语义多样化的合成数据集。本发明遵循基于分布匹配的框架,从语义信息的角度出发,充分考虑了语义信息,以增强压缩的合成实例的语义多样性。
技术研发人员:周玉灿,李洪成,古晓艳,李波,王伟平
受保护的技术使用者:中国科学院信息工程研究所
技术研发日:
技术公布日:2025/2/5
- 还没有人留言评论。精彩留言会获得点赞!