一种人车碰撞后行人落地头部朝向判定方法
本发明属于机器视觉识别,具体涉及一种人车碰撞后行人落地头部朝向判定方法。
背景技术:
1、在道路交通事故中行人处于弱势地位,在人车碰撞事故发生后,人员的损伤部位主要有头部、上肢、胸部以及脊椎等。其中,头部损伤出现的最为频繁。头部损伤的救治与时间息息相关,若救治不及时会威胁行人的生命安全。
2、现有的自动紧急呼救系统(advanced automatic crash notification system,aacn)有效保护了车内人员却忽视了车外人员的保护,这是因为人车碰撞事故发生后,行人倒地时受限于监控视频清晰度不佳,无法判定行人头部的朝向,进而影响了aacn对车外人员的保护效果。
技术实现思路
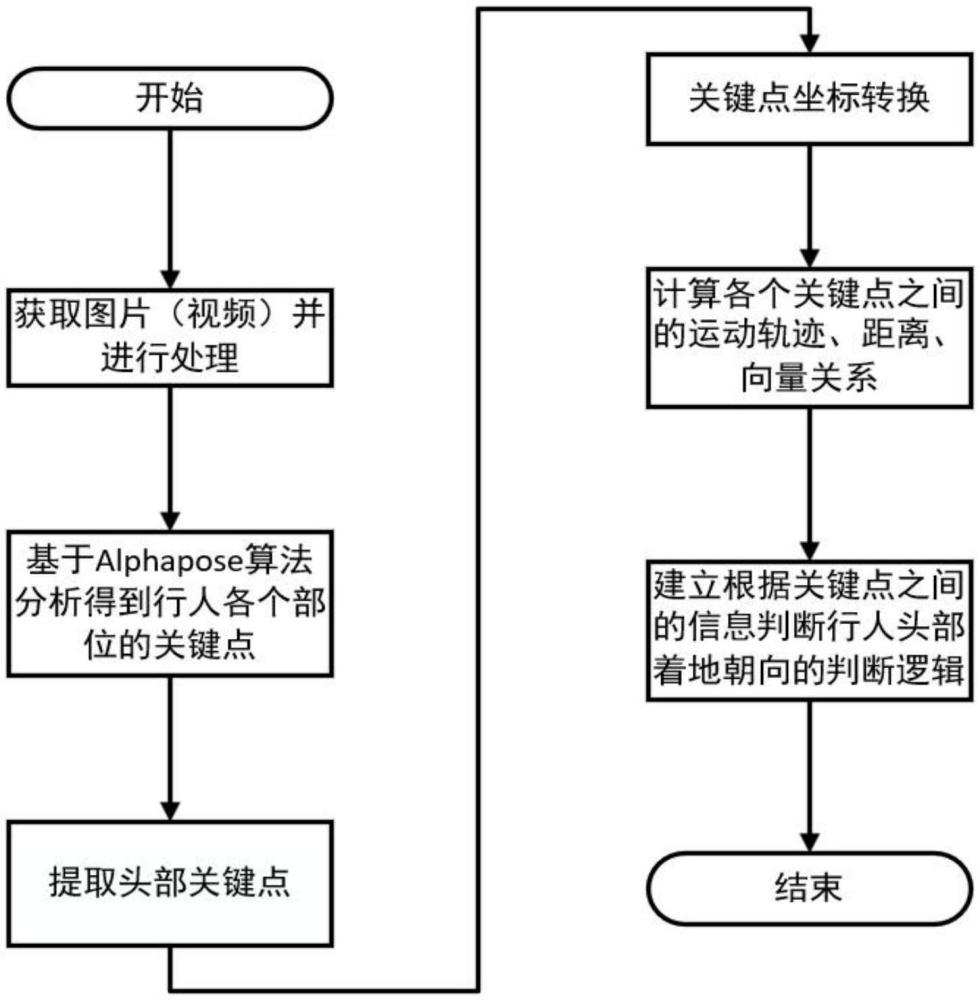
1、为了解决现有技术中存在的不足,本发明提出了一种人车碰撞后行人落地头部朝向判定方法,本方法基于alphapose的人体关键点的检测建立人体骨架结构模型,获取头部关键点,通过撞击和落地两个关键时间节点之间的图像中行人关键点坐标信息转换为头部运动信息,计算出关键点之间的向量关系,根据向量关系的变化来确定头部着地朝向。
2、本发明是通过以下技术手段来实现以上技术目的。
3、一种人车碰撞后行人落地头部朝向判定方法,包括如下步骤:
4、步骤1:获取人车碰撞发生时车外部的图像数据,通过图像分割获取包含行人信息的关键帧;
5、步骤2:对关键帧进行图像处理,提取出图像中的人体区域和候选框;
6、步骤3:使用alphapose算法从关键帧中提取出行人的姿态关键点;
7、步骤4:根据步骤3中得到的姿态关键点,构建人体骨架模型,基于人体骨架模型对行人落地过程中头部的五个关键点坐标进行分析,输出行人落地头部朝向判断结果。
8、进一步,对行人落地头部朝向进行判断的过程为:
9、步骤4.1:将关键帧中的姿态关键点的坐标信息转化为对应帧的像素点坐标信息;
10、步骤4.2:根据对应的像素点坐标信息建立不同帧下的人体骨架模型;
11、步骤4.3:根据关键帧之间的时间差与各个帧之间的人体骨架模型的姿态关键点之间的向量关系对行人落地头部朝向进行判断。
12、进一步,以关键帧图像左上角顶点作为坐标原点,分别以像素坐标系中的行索引和列索引作为x轴与y轴,建立像素坐标系,头部的五个关键点分别表示为:代表鼻子的关键点p0对应的坐标可表示为(x0、y0),代表左眼关键点p1表示为(x1、y1),代表右眼关键点p2表示为(x2、y2),代表左耳关键点p3表示为(x3、y3),代表右耳关键点p4表示为(x4、y4)。
13、进一步,行人落地头部朝向分为头部正面着地、头部后面着地、头部左侧着地和头部右侧着地。
14、进一步,根据五个头部关键点对行人落地头部朝向进行判断的依据为:
15、(1)对于头部正面着地的判断依据:提取行人落地过程中五个头部关键点的坐标信息,若五个头部关键点之间的相对位置不变,且p0和p1的横坐标均一致,即x1=x2;行人头部落地下一时刻其代表鼻子的关键点和代表左眼的关键点p0’和p1’的纵坐标之差的绝对值
16、|y1’-y0’|小于前一时刻p0和p1的纵坐标之差的绝对值|y1-y0|,若满足上述条件,则认为判定为行人头部正面着地。
17、(2)头部右侧着地:提取行人落地过程中五个头部关键点的坐标信息,若落地过程中出现当前时刻的p0和p1的纵坐标之差的绝对值|y1-y0|比下一时刻的p0’和p1’纵坐标之差的绝对值|y1’-y0’|大的情况,同时po和p1组成的向量和p0’和p1’组成的向量之间的夹角逐渐变小且经计算最终在结果处于0°-45°范围内时,判定为头部右侧着地。
18、(3)头部左侧着地:提取行人落地过程中五个头部关键点的坐标信息,若出现当前时刻的p0和p1的纵坐标之差的绝对值|y1-y0|等于下一时刻的p0’和p1’纵坐标之差的绝对值|y1’-y0’|,且同一时刻由po和p1组成的向量和p0和p2组成的向量之间的夹角为0°,且p0,p1,p2横坐标一致,p0纵坐标大于p1,p2纵坐标时,判定为头部左侧着地。
19、(4)头部后部着地:提取行人落地过程中五个头部关键点的坐标信息,若出现当前时刻的p0和p1的纵坐标之差的绝对值|y1-y0|等于下一时刻的p0’和p1’纵坐标之差的绝对值|y1’-y0’|的情况,且同一时刻由p0和p1组成的向量与p0和p2组成的向量之间的夹角为0°,同时坐标点p0、p1和p3的纵坐标均相等且p0、p1重合时,判定为头部后部着地。
20、进一步,步骤3从关键帧中提取出行人的姿态关键点的过程如下:
21、步骤3.1:基于获取的候选框,使用alphapose算法中的单人姿态估计器(sppe)对候选框中的人体区域进行深度分析,得到关键人体区域;
22、步骤3.2:使用空间变换网络(stn)对关键人体区域进行分析;
23、步骤3.3:利用卷积神经网络对关键人体区域进行特征提取;
24、步骤3.4:利用sppe对提取到的特征进行处理,得到关键人体区域中的姿态关键点,使用姿态引导区域生成器(pgpg)对姿态关键点进行处理,对偏移较大的姿态关键点进行矫正;
25、步骤3.5:使用反向空间变化网络(sdtn)将姿态关键点按照身体部位映射到关键帧中。
26、进一步,步骤2中提取出图像中的人体区域和候选框的过程为:
27、步骤2.1:将步骤1获取的关键帧作为输入图像,对输入的关键帧图像进行变换,将图像中的行人定位到检测框的中心位置;
28、步骤2.2:使用区域提议网络(rpn)识别所有关键帧中的人体区域,同时区域提议网络(rpn)输出候选框;
29、步骤2.3:使用非极大抑制对候选框进行置信度检测,以消除冗余的候选框。
30、进一步,使用空间变换网络(stn)对输入的关键帧图像进行变换,
31、进一步,所述步骤2.3中使用非极大抑制(nms)对候选框进行置信度检测,非极大抑制包括置信度消除和距离消除。
32、进一步,步骤1利用yolov5-cbam算法从所获取的车外部图像数据中抽取出包含行人信息的关键帧。
33、本发明的有益效果:
34、本申请提出一种人车碰撞后行人落地头部朝向的判定方法,基于alphapose算法建立人体关键点示意图提取头部关键点坐标,最后根据关键点之间随着时间变化得到的关键点间坐标差值与向量关系来判断头部的具体朝向,可以在能见度不佳的情况下判断行人头部的具体朝向,有助于帮助医疗机构在行人发生车祸后对行人损伤进行初步诊断。
技术特征:
1.一种人车碰撞后行人落地头部朝向判定方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的一种人车碰撞后行人落地头部朝向判定方法,其特征在于,对行人落地头部朝向进行判断的过程为:
3.根据权利要求2所述的一种人车碰撞后行人落地头部朝向判定方法,其特征在于,以关键帧图像左上角顶点作为坐标原点,分别以像素坐标系中的行索引和列索引作为x轴与y轴,建立像素坐标系,头部的五个关键点分别表示为:代表鼻子的关键点p0对应的坐标可表示为(x0、y0),代表左眼关键点p1表示为(x1、y1),代表右眼关键点p2表示为(x2、y2),代表左耳关键点p3表示为(x3、y3),代表右耳关键点p4表示为(x4、y4)。
4.根据权利要求3所述的一种人车碰撞后行人落地头部朝向判定方法,其特征在于,行人落地头部朝向分为头部正面着地、头部后面着地、头部左侧着地和头部右侧着地。
5.根据权利要求4所述的一种人车碰撞后行人落地头部朝向判定方法,其特征在于,根据五个头部关键点对行人落地头部朝向进行判断的依据为:
6.根据权利要求1所述的一种人车碰撞后行人落地头部朝向判定方法,其特征在于,步骤3从关键帧中提取出行人的姿态关键点的过程如下:
7.根据权利要求1所述的一种人车碰撞后行人落地头部朝向判定方法,其特征在于,步骤2中提取出图像中的人体区域和候选框的过程为:
8.根据权利要求7所述的一种人车碰撞后行人落地头部朝向判定方法,其特征在于,使用空间变换网络stn对输入的关键帧图像进行变换。
9.根据权利要求7所述的一种人车碰撞后行人落地头部朝向判定方法,其特征在于,所述步骤2.3中使用非极大抑制nms对候选框进行置信度检测,非极大抑制包括置信度消除和距离消除。
10.根据权利要求1所述的一种人车碰撞后行人落地头部朝向判定方法,其特征在于,步骤1利用yolov5-cbam算法从所获取的车外部图像数据中抽取出包含行人信息的关键帧。
技术总结
本发明公开了一种人车碰撞后行人落地头部朝向判定方法,获取人车碰撞发生时车外部的图像数据,通过图像分割获取包含行人信息的关键帧;对关键帧进行图像处理,提取出图像中的人体区域和候选框;使用Alphapose算法从关键帧中提取出行人的姿态关键点;根据姿态关键点,构建人体骨架模型,基于人体骨架模型对行人落地过程中头部的五个关键点坐标进行分析,通过撞击和落地两个关键时间节点之间的图像中行人关键点坐标信息转换为头部运动信息,计算出关键点之间的向量关系,根据向量关系的变化来确定头部着地朝向;本发明可以在能见度不佳的情况下判断行人头部的具体朝向,有助于帮助医疗机构在行人发生车祸后对行人损伤进行初步诊断。
技术研发人员:陆颖,柏军,匡荣
受保护的技术使用者:江苏大学
技术研发日:
技术公布日:2025/1/13
- 还没有人留言评论。精彩留言会获得点赞!