一种基于映射记忆网络的低资源语种文本立场分析方法
本发明涉及自然语言理解,具体涉及一种基于映射记忆网络的低资源语种文本立场分析方法。
背景技术:
1、跨语言文本立场分析是自然语言处理领域和计算语言学领域中的一个重要研究方向,特别是在社交媒体分析和文本数据挖掘中具有广泛的应用。随着社交媒体平台的迅猛发展,互联网中的文本信息,例如观点评论等,急剧增加,而在不同国家的社交媒体平台上,存在着多种语言文本,且数量分布不一,主流语言的观点评论数量占大多数。例如,在我国的社交媒体平台上,绝大多数观点评论为中文,存在少量英文、日文、韩文等语言的观点评论。现有的立场分析方法可以在样本多(即主流语言)的情况下,取得较好的文本立场分析结果。而面对少数语言的文本分析还存在较大差距。因此,如何有效地检测和分析用户在跨语言文本中的立场,成为了一个亟待解决的问题。立场分析不仅能够反映用户的内在价值观,而且在安全领域中具有重要的现实意义。
2、当前,绝大多数立场分析研究都集中在单语言以及多样本条件场景下,利用丰富的标注语料进行模型训练,但是对于低资源语言,标注数据通常非常稀缺,这使得跨语言立场分析的推广和应用面临巨大挑战。为了解决这一问题,研究者提出了利用高资源语言的数据进行模型训练,并将其模型知识转移到低资源目标语言上的跨语言立场分析技术,忽略了目标语言的上下文信息以及目标语言与源语言的对齐信息。还有一些现有技术依赖于目标语言中的有限标注数据,但在实际应用中,当目标语言缺乏标注数据时,这些方法的表现往往难以令人满意。此外,跨语言立场分析还面临目标表达多样性的问题。传统立场分析任务通常集中在特定的公投、人物或事件上,目标通常以关键词或短语的形式出现。然而,在实际应用中,立场分析的目标通常表现为句子级别的主题(例如问题或陈述)。因此,如何在跨语言场景中有效地表示和处理这些多样化的主题表达,成为了立场分析领域中的一个关键问题。
技术实现思路
1、为解决上述技术问题,本发明提供一种基于映射记忆网络的低资源语种文本立场分析方法,主要包括以下几个方面的优势:(1)精确立场分析:通过映射记忆模块,将源语言的关键词及其关联信息有效映射到目标语言中,实现了高精度的立场分析,即使目标语言缺乏标注数据也能取得良好效果;(2)充分利用源语言知识:映射记忆模块考虑了关键词的语境权重差异,并通过计算关键词与立场之间的互信息,确保源语言的先验知识能有效转移到目标语言,显著提升检测准确性;(3)逻辑连贯性与一致性:本发明通过引入精确的关键词信息融合先验信息,确保检测结果逻辑连贯、一致。
2、为解决上述技术问题,本发明采用如下技术方案:
3、一种基于映射记忆网络的低资源语种文本立场分析方法,通过源语言的文本句子以及源语言文本句子的立场标签,分析目标语言的文本句子的立场;其中,目标语言的文本句子数量小于源语言的文本句子数量;具体包括以下步骤:
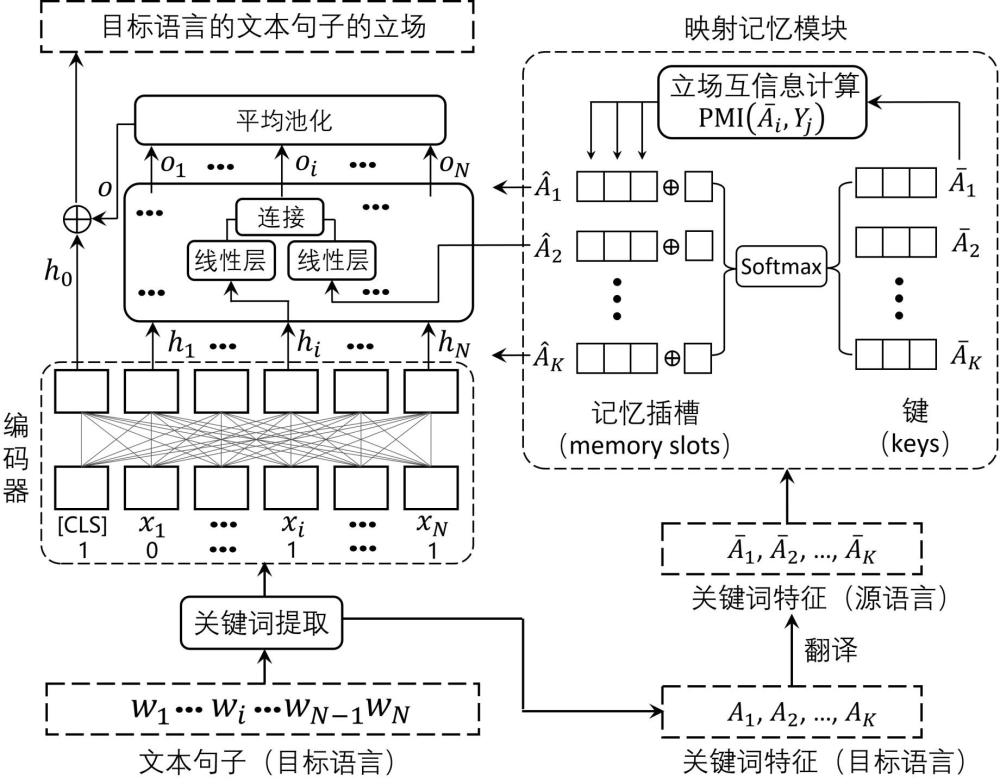
4、步骤一,特征提取:给定的目标语言的文本句子由n个词组成,为中的第i个词;对中的每个词进行编码,得到词特征,表示中的第i个词的词特征;对进行关键词提取,得到k个目标语言下的关键词,k个目标语言下的关键词的特征组成目标语言关键词特征集合,其中为中的第k个目标语言下的关键词特征;根据词特征是否属于,在词特征后连接0或者1,通过编码器对连接后的词特征进行编码,得到每个词特征对应的隐藏层表征;
5、步骤二,映射记忆:将中的每个目标语言下的关键词特征翻译为源语言下的关键词特征,得到源语言关键词特征集合,为中第k个源语言下的关键词特征;使用softmax函数对中的每个关键词特征的重要性进行评估,得到的权重;计算每个源语言下的关键词特征与每种立场之间的互信息,其中表示第j种立场的标签;将所有互信息连接到加权后的源语言下的关键词特征上,得到每个源语言下的关键词的记忆插槽特征;
6、步骤三,记忆加强的立场分析:对于,如果中的第i个词的词特征属于目标语言下的关键词特征,则将对应的源语言下的关键词的记忆插槽特征作为知识信息融合进隐藏层表征中,得到对应的输出特征,是使得的下标,;如果中的第i个词的词特征不属于目标语言下的关键词特征,对应的输出特征用隐藏层表征表示,即;对所有的输出特征进行平均池化,将得到的平均池化结果与文本句子的句子整体性特征连接,获得总体句子表征r:采用分类器对总体句子表征r进行分类,得到目标语言的文本句子的立场分析结果。
7、进一步地,步骤二中,所述使用softmax函数对中的每个关键词特征的重要性进行评估,得到的权重,具体包括:
8、第k个关键词特征的权重为:
9、;
10、,为softmax函数。
11、进一步地,步骤二中,所述计算每个源语言下的关键词特征与每种立场之间的互信息,具体包括:
12、;
13、其中,表示源语言下所有包含的文本句子中,立场标签为的样本数;表示源语言下所有包含的文本句子数。
14、进一步地,步骤二中,所述将所有互信息连接到加权后的源语言下的关键词特征上,得到每个源语言下的关键词的记忆插槽特征,具体包括:
15、;
16、其中,表示连接操作,表示立场标签的总数。
17、进一步地,步骤一中,所述根据词特征是否属于,在词特征后连接0或者1,通过编码器对连接后的词特征进行编码,得到每个词特征对应的隐藏层表征,具体包括:
18、对于中每个词的词特征,定义函数:
19、;
20、同时,在的句首添加“[cls]”位,对应的词特征记为,设为1;
21、将连接到每个词特征后,采用编码器对连接后的词特征进行编码,获得每个词对应的隐藏层表征;其中为“[cls]”位的隐藏层特征,用于表示句子整体性特征。
22、进一步地,步骤三具体包括:
23、计算对应的输出特征:
24、;
25、其中,表示使的下标,用来找到对应的关键词特征,;表示线性层,,w、b为可学习的参数,表示线性层输入,表示线性层输出;
26、之后,对所有的采用平均池化操作,即求和平均,再连接到句子整体性表示上,获得总体句子表征r:
27、;
28、表示连接操作;
29、最后,采用分类器对总体句子表征r进行分类,得到目标语言的文本句子的立场分析结果。
30、与现有技术相比,本发明的有益技术效果是:
31、(1)充分利用了源语言域下的知识信息,使得目标语言下的文本立场分析更加精确;(2)设计了映射记忆网络,充分集成了其所属句子中的权重信息和源语言下的关键词对应每种立场的样本先验信息,以更好的利用源语言下的知识信息;(3)能够在跨语言环境下更准确的分析文本立场。
技术特征:
1.一种基于映射记忆网络的低资源语种文本立场分析方法,其特征在于,通过源语言的文本句子以及源语言文本句子的立场标签,分析目标语言的文本句子的立场;其中,目标语言的文本句子数量小于源语言的文本句子数量;具体包括以下步骤:
2.根据权利要求1所述的基于映射记忆网络的低资源语种文本立场分析方法,其特征在于,步骤二中,所述使用softmax函数对中的每个关键词特征的重要性进行评估,得到的权重,具体包括:
3.根据权利要求1所述的基于映射记忆网络的低资源语种文本立场分析方法,其特征在于,步骤二中,所述计算每个源语言下的关键词特征与每种立场之间的互信息,具体包括:
4.根据权利要求1所述的基于映射记忆网络的低资源语种文本立场分析方法,其特征在于,步骤二中,所述将所有互信息连接到加权后的源语言下的关键词特征上,得到每个源语言下的关键词的记忆插槽特征,具体包括:
5.根据权利要求1所述的基于映射记忆网络的低资源语种文本立场分析方法,其特征在于,步骤一中,所述根据词特征是否属于,在词特征后连接0或者1,通过编码器对连接后的词特征进行编码,得到每个词特征对应的隐藏层表征,具体包括:
6.根据权利要求5所述的基于映射记忆网络的低资源语种文本立场分析方法,其特征在于,步骤三具体包括:
技术总结
本发明涉及自然语言理解技术领域,公开了一种基于映射记忆网络的低资源语种文本立场分析方法,基于源语言的文本句子以及源语言的文本句子的立场标签,分析目标语言的文本句子的立场;具体包括:获取目标语言的文本句子的每个词的词特征、关键词特征、隐藏层表征;将目标语言下的关键词特征翻译为源语言下的关键词特征,计算源语言下关键词特征的权重和记忆插槽特征;计算目标语言的文本句子的每个词的词特征所对应的输出特征,经过平均池化和分类器后,得到目标语言的文本句子的立场分析结果。本发明充分利用了源语言域下的知识信息,使得目标语言下的文本立场分析更加精确,能够在跨语言环境下更准确的分析文本立场。
技术研发人员:周秋利,陈伟东,唐军,唐宇香
受保护的技术使用者:合肥工业大学
技术研发日:
技术公布日:2024/10/31
- 还没有人留言评论。精彩留言会获得点赞!