一种存算一体的硬件加速器及其指令集架构的制作方法
本发明涉及存算一体,尤其是存算一体的硬件加速器及其指令集架构。
背景技术:
1、随着人工智能和深度学习技术的快速发展,传统的硬件加速器在处理海量数据时面临着存储瓶颈和功耗瓶颈的问题。存算一体架构的提出,为解决这些问题提供了新思路。存算一体架构通过在存储单元内直接进行计算,减少了数据搬运次数,提高了计算效率并降低了功耗。然而,现有的指令集架构并不能充分发挥存算一体架构的优势,由于存内计算独特的计算方式,其指令设计、数据流调度方式与传统的存算分离计算单元存在较大差异,套用传统计算指令无法发挥存算计算单元的优势,且会使其工作效率低于传统硬件加速器。一种存算一体芯片的嵌入式处理器、指令集及数据处理方法(公开号为cn110990060a)公开了通过存算一体阵列进行矩阵乘加运算,其他运算由cpu进行,导致数据需要在存算一体芯和cpu之间反复搬运,运算效率较低,也无法真正实现存算一体。因此,需要一种存算一体架构及其指令集来解决上述问题。
技术实现思路
1、发明目的:本发明的目的是提供一种数据复用性强,运算效率高的存算一体的硬件加速器,本发明的第二目的是提供一种针对存算一体的具有规范性与易用性的指令集架构。
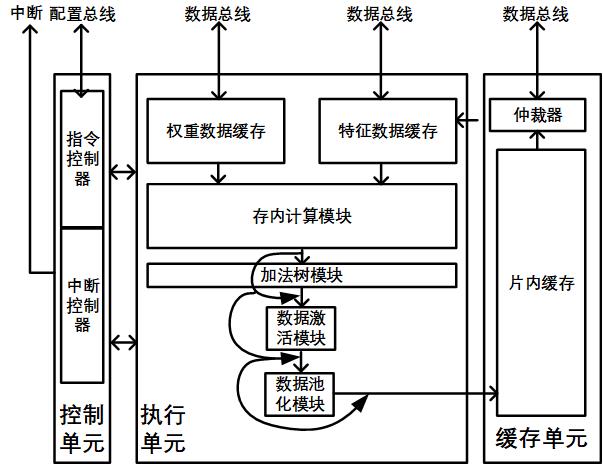
2、技术方案:本发明所述的存算一体的硬件加速器,包括控制单元、运算执行单元和缓存单元;
3、所述控制单元用于从cpu接受指令,将指令解码并发送至运算执行单元和缓存单元;还用于在任务完成后通过设置中断通知cpu;
4、所述运算执行单元包括权重数据缓存模块、特征数据缓存模块和数据处理模块,权重数据缓存模块内存储运算需要的权重数据,特征数据缓存模块内存储运算需要的特征数据,数据处理模块对权重数据和特征数据进行运算,运算结果发送至缓存单元;
5、所述缓存单元将运算结果传回cpu,或者将处理结果暂存至片内缓存模块,下一次运算时将运算结果发送至特征数据缓存模块。
6、进一步地,运算执行单元中的数据处理模块包括存内计算模块、加法树模块、数据激活模块以及数据池化模块,存内计算模块用于进行卷积和/或全连接运算。
7、进一步地,所述存内计算模块、加法树模块、数据激活模块、数据池化模块与片内缓存模块依次连接,通过指令配置存内计算模块、加法树模块、数据激活模块、数据池化模块是否启用。
8、进一步地,所述缓存单元利用仲裁器确定运算结果传回cpu或暂存至片内缓存模块。
9、本发明所述的硬件加速器的数据处理方法,包括如下步骤:
10、控制单元从cpu接受指令,将指令解码并发送至运算执行单元和缓存单元;
11、cpu将权重数据发送至运算执行单元的权重数据缓存模块,将特征数据发送至特征数据缓存模块,数据处理模块对权重数据和特征数据进行运算,运算结果发送至缓存单元;
12、缓存单元将运算结果传回cpu或者将处理结果暂存至片内缓存模块,下一次运算时将运算结果发送至特征数据缓存模块;
13、通过设置中断通知cpu。
14、本发明所述的硬件加速器的指令集架构,包括运算执行单元和缓存单元中各模块的指令,每条指令包括对应模块的启用、规模、功能及工作状态。
15、进一步地,还包括仲裁器控制指令,用于确定片内缓存模块内部数据的输出方向,如果该数据是最终结果,则输出到cpu,如果该数据用于进行下一次运算,则存入片内缓存模块,下一次运算时将该数据发送至特征数据缓存模块。
16、进一步地,运算执行单元中存内计算模块的指令包括存内计算模块的工作状态、启用的运算单元数目、功能和预留位;存内计算模块的工作状态包括完成配置待命状态、工作中和完成运算状态;存内计算模块的功能包括卷积和全连接。
17、进一步地,运算执行单元中加法树模块、数据激活模块、数据池化模块的指令包括其工作状态、启用的运算单元数目和预留位;加法树模块、数据激活模块、数据池化模块的工作状态均包括完成配置待命状态、工作中和完成运算状态。
18、进一步地,仲裁器控制指令包括数据传输方向和预留位;所述数据传输方向包括向片外数据总线传输和向特征数据缓存模块传输。
19、有益效果:与现有技术相比,本发明的优点在于:
20、(1)本发明的硬件加速器具有良好的算法兼容性,存内计算(乘累加)、激活、池化、全连接四种算子依次排列,符合大多数神经网络算法中算子前后排列关系,舍弃片内复杂的数据通路网络设计,降低硬件加速器硬件复杂度与功耗。通过指令控制的数据流配置,可实现神经网络算法中卷积、激活、池化、全连接四种算子的在线配置,从而实现更广泛的神经网络算法支持;通过配置各模块启用与否,可将神经网络单轮运算中不需要的功能模块休眠以节省功耗,同时也能满足神经网络算法不同计算层对算子不同排列组合的需求。
21、(2)本发明的硬件加速器提高了数据复用性,通过指令配置仲裁器,可实现中间运算结果的重复利用,减少了数据运算过程中与上层主机的数据交互,提高运算效率,降低功耗。
22、(3)本发明的指令集架构实现格式规范化,通过指令地址统一分配与指令集长度和格式的规定,使整体寄存器与各分模块寄存器分别分配了足够的地址空间,各指令拥有统一的指令格式,以确保每个模块都能够拥有足够的指令资源且驱动层可以方便下达特定指令。提高了系统的灵活性和可扩展性,降低了驱动层的设计复杂度。随着计算任务的不断发展和变化,用户可以通过添加新的指令和扩展寄存器的功能来适应新的计算需求。规定特有的指令格式提高了指令阅读与使用的规范性与易用性,能够方便地集成到各种计算系统中。
23、(4)本发明的指令集架构具有存算专有高效指令,通过特有指令对存内计算模块输入权重数据的存储特性的调用,使得输入权重数据一次存储多次参与计算,减少了数据搬运,打破了传统硬件加速器中内存墙的桎梏,提高运算效能与计算速度。
24、(5)本发明的的指令集架构与存内计算技术实现了深度融合。通过设定指令集格式规范、分模块精确控制、数据流调度和针对存算一体架构的优化设计,充分发挥了存内计算架构的优势,提高了系统的性能和效率。
技术特征:
1.一种存算一体的硬件加速器,其特征在于,包括控制单元、运算执行单元和缓存单元;
2.根据权利要求1所述的存算一体的硬件加速器,其特征在于,运算执行单元中的数据处理模块包括存内计算模块、加法树模块、数据激活模块以及数据池化模块,存内计算模块用于进行卷积和/或全连接运算。
3.根据权利要求2所述的存算一体的硬件加速器,其特征在于,所述存内计算模块、加法树模块、数据激活模块、数据池化模块与片内缓存模块依次连接,通过指令配置存内计算模块、加法树模块、数据激活模块、数据池化模块是否启用。
4.根据权利要求1所述的存算一体的硬件加速器,其特征在于,所述缓存单元利用仲裁器确定运算结果传回cpu或暂存至片内缓存模块。
5.一种权利要求1至4任一项所述硬件加速器的数据处理方法,其特征在于,包括如下步骤:
6.一种权利要求1至4任一项所述硬件加速器的指令集架构,其特征在于,包括运算执行单元和缓存单元中各模块的指令,每条指令包括对应模块的启用、规模、功能及工作状态。
7.根据权利要求6所述的指令集架构,其特征在于,还包括仲裁器控制指令,用于确定片内缓存模块内部数据的输出方向,如果该数据是最终结果,则输出到cpu,如果该数据用于进行下一次运算,则存入片内缓存模块,下一次运算时将该数据发送至特征数据缓存模块。
8.根据权利要求6所述的指令集架构,其特征在于,运算执行单元中存内计算模块的指令包括存内计算模块的工作状态、启用的运算单元数目、功能和预留位;
9.根据权利要求6所述的指令集架构,其特征在于,运算执行单元中加法树模块、数据激活模块、数据池化模块的指令包括其工作状态、启用的运算单元数目和预留位;
10.根据权利要求7所述的指令集架构,其特征在于,仲裁器控制指令包括数据传输方向和预留位;
技术总结
本发明公开了一种存算一体的硬件加速器及其指令集架构,该硬件加速器包括控制单元、运算执行单元和缓存单元;运算执行单元包括权重数据缓存模块、特征数据缓存模块和数据处理模块,数据处理模块对权重数据和特征数据进行卷积、激活、池化、全连接运算,运算结果发送至缓存单元;缓存单元根据仲裁器判断数据传输方向,将运算结果传回CPU,或者将处理结果暂存至片内缓存模块,下一次运算时将运算结果发送至特征数据缓存模块。本发明通过指令控制的数据流配置,可实现神经网络算法中卷积、激活、池化、全连接四种算子的在线配置,通过指令配置仲裁器,可实现中间运算结果的重复利用,减少了数据运算过程中与上层主机的数据交互。
技术研发人员:李元振,王建超,庞亮,尚德龙,周玉梅
受保护的技术使用者:中科南京智能技术研究院
技术研发日:
技术公布日:2024/11/28
- 还没有人留言评论。精彩留言会获得点赞!