一种基于混合模型的客户流失预测系统
本发明涉及客户关系管理和机器学习领域,具体涉及客户关系管理中的rfm模型和机器学习领域的k-means与随机森林算法,以上三者在企业客户预测系统中的应用。
背景技术:
1、老客户的流失会给企业带来较大的损失,减少老客户的流失对企业的长远发展至关重要。企业需要预测潜在的流失客户,在客户流失之前,分析其流失的原因,找到提升客户留存率的方法,制定有效的挽留措施。
2、随着大数据技术和网络信息产业的不断发展,机器学习技术为数据分析提供了更加高效的工具。企业可以基于客户的基本信息和订单数据,构建客户流失的特征模型,提前识别可能流失的客户,并根据关键特征制定针对性的挽留策略,从而减少客户流失。
技术实现思路
1、本发明的目的是为了开发一种基于混合模型的客户流失预测系统,包括rfm模型、k-means聚类算法与随机森林分类算法。该系统通过结合无监督学习与监督学习的优势,提高预测准确性降低客户流失率。为了实现上述目的,本发明采用了如下技术方案:
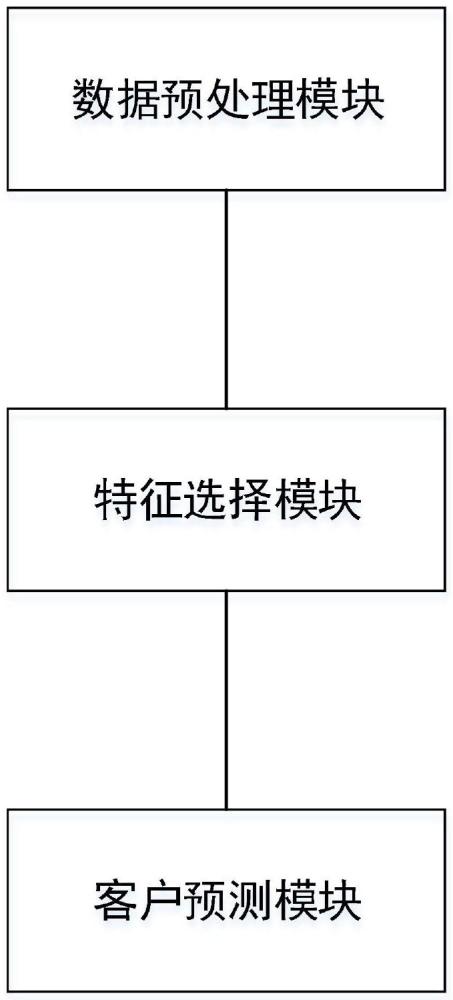
2、一种基于混合模型的客户流失预测系统,包括数据预处理模块、特征选择模块、以及客户流失预测模块。
3、所述数据预处理模块用于数据收集并预处理后反馈至特征选择模块;
4、所述特征选择模块用于在数据集中筛选出客户流失预测系统需要的特征,将筛选后的数据集反馈至客户流失预测模块。
5、所述客户流失预测模块先对客户进行聚类,将客户分类模块中鉴定为忠诚度不够的类别客户进行预测,采用随机森林算法预测出可能流失的客户。
6、数据预处理模块的数据来源于用户在店铺消费的历史数据,历史数据放入数据集中。使用pandas库的read_csv函数从csv文件中读取数据后放入数据集中。
7、对数据集进行预处理时检查数据集中是否存在重复值,数据集中包含有客户信息表,客户信息表中客户id是唯一主键,删除客户id重复的记录。数据集中包含有订单详情表,表中订单id是唯一主键,删除此表中订单id的重复记录。
8、对数据集进行预处理时检查数据集中是否存在异常值,数据集中包含有订单详情表,删除此表中已锁单和未付款的记录。
9、特征选择模块采用rfm模型来识别客户,r是客户最近一次消费距观测窗口结束的天数,f是客户在观测窗口中的总消费次数,m是客户在观测窗口中的总消费金额。
10、特征选择模块中需要对数据进行标准化处理以消除数量级数据带来的影响。标准化处理采用基于数据均值和方差的z-score标准化方法导入numpy库和pandas库,以使用pandas库的read_csv函数从csv文件中读取数据,使用numpy库的mean和std函数来计算平均值和标准差。计算z-score的值,公式是:z=(x-mean)/std,其中x是原始数据,mean是平均值,std是标准差。
11、客户流失预测模块中采用轮廓系数(silhouette coefficient index)确定聚类的簇数,确定轮廓系数(silhouette coefficient index)确定聚类的簇数步骤如下:
12、对于其中的一个点i,计算i向量到同簇内其他点不相似程度的平均值a(i)体现凝聚度,计算i向量到其他簇的平均不相似程度的最小值b(i)体现分离度
13、该样本i的轮廓系数计算公示为
14、
15、样本i轮廓系数的区间为:[-1,1]。-1代表分类效果差,1代表分类效果好。0代表聚类重叠,没有很好的划分聚类。
16、根据簇数的数量使用sklearn库中的kmeans函数对数据集进行聚类,判断出忠诚度低的客户聚类标签,步骤如下:
17、(1)首先选择k个聚类中心点,可以是随机选择或根据数据本身的特征进行选择。
18、(2)将所有数据点分别分配到距离最近的中心点所在的聚类中。
19、(3)重新计算每个聚类的中心点,即该聚类中所有点的均值。
20、(4)重复步骤(2)和(3),直到聚类中心点不再发生变化或达到指定的迭代次数。
21、采用随机森林算法对忠诚度低的客户类别进行流失预测,忠诚度高的客户聚类不进行预测。使用随机森林算法对客户进行流失预测的步骤如下:
22、导入numpy库、pandas库和matplotlib库,以使用pandas库的read_csv函数从csv文件中读取数据,然后将数据集划分为训练集和测试集,使用randomforestclassifier()函数创建一个随机森林模型实例,对训练集中的训练数据拟进行拟合训练,拟合完成后使用测试集对创建的随机森林模型进行评估,最后实现对客户数据的回归预测。
23、本发明的有益效果
24、该系统通过结合rfm模型与k-means聚类和随机森林分类的优势,能够有效处理企业的客户流失问题。k-means提供了客户的初步聚类信息,使得随机森林模型能够在不同的客户群体中进行针对性的流失预测。随机森林的集成学习机制增强了对复杂客户行为的预测能力,同时减少了对单一数据点的依赖,提高了模型的鲁棒性和泛化能力。最终,系统能够为餐饮企业提供准确的客户流失预测,并帮助企业制定有效的挽留策略,从而提高客户留存率和企业的整体经济效益。
技术特征:
1.一种基于混合模型的客户流失预测系统,其特征在于,包括数据预处理模块、特征选择模块、以及客户流失预测模块;
2.根据权利要求1所述的一种基于混合模型的客户流失预测系统,其特征在于,数据来源于用户在店铺消费的历史数据,使用pandas库的read_csv函数从csv文件中读取数据后放入数据集中。
3.根据权利1所述的一种基于混合模型的客户流失预测系统,其特征在于,对数据集进行预处理时检查数据集中是否存在重复值,数据集中包含有客户信息表,客户信息表中客户id是唯一主键,删除客户id重复的记录。数据集中包含有订单详情表,表中订单id是唯一主键,删除此表中订单id的重复记录。
4.根据权利要求1所述的一种基于混合模型的客户流失预测系统,其特征在于,对数据集进行预处理时检查数据集中是否存在异常值,数据集中包含有订单详情表,删除此表中已锁单和未付款的记录。
5.根据权利要求1所述的一种基于混合模型的客户流失预测系统,其特征在于,特征选择模块采用rfm模型来识别客户,r是客户最近一次消费距观测窗口结束的天数,f是客户在观测窗口中的总消费次数,m是客户在观测窗口中的总消费金额。
6.根据权利要求1所述的一种基于混合模型的客户流失预测系统,其特征在于,特征选择模块中需要对数据进行标准化处理以消除数量级数据带来的影响。标准化处理采用基于数据均值和方差的z-score标准化方法。
7.根据权利要求6所述的一种基于混合模型的客户流失预测系统,其特征在于,基于数据均值和方差的z-score标准化方法步骤如下:导入numpy库和pandas库,以使用pandas库的read_csv函数从csv文件中读取数据,使用numpy库的mean和std函数来计算平均值和标准差。计算z-score的值,公示是:z=(x-mean)/std,其中x是原始数据,mean是平均值,std是标准差。
8.根据权利要求1所述的一种基于混合模型的客户流失预测系统,其特征在于,客户预测模块采用轮廓系数(silhouette coefficient index)确定聚类的簇数后,使用sklearn库中的kmeans函数对数据集进行聚类,判断出忠诚度低的客户聚类标签。
9.根据权利要求8所述的一种基于混合模型的客户流失预测系统,其特征在于,轮廓系数(silhouette coefficient index)确定聚类的簇数步骤如下:
10.根据权利要求8所述的一种基于混合模型的客户流失预测系统,其特征在于,使用sklearn库中的kmeans函数对数据集进行聚类,步骤如下:
11.根据权利要求1所述的一种基于混合模型的客户流失预测系统,其特征在于,客户预测模块用随机森林算法对忠诚度低的客户类别进行流失预测,忠诚度高的客户聚类不进行预测。
12.根据权利要求11所述的一种基于混合模型的客户流失预测系统,其特征在于,使用随机森林算法对客户进行流失预测的步骤如下:
技术总结
针对目前企业客户流失预测数据样本不均、特征复杂导致检测精度低等问题,提出了一种基于混合模型的客户流失预测模型。对原始数据进行预处理后根据RFM模型构建特征,对数据进行标准化处理后采用K‑means算法将客户聚类,聚类后对忠诚度低的类别进行流失预测,使用随机森林算法对忠诚度低的用户进行精确分类。实验结果表明,该方法检测精度提高检测工作量降低,综合分析,该方法可为企业预测客户流失提供一定的指导,具有较好的应用前景。
技术研发人员:江进
受保护的技术使用者:江苏农林职业技术学院
技术研发日:
技术公布日:2025/2/24
- 还没有人留言评论。精彩留言会获得点赞!