大模型低秩自适应层权重矩阵微调方法与流程
本发明属于深度学习的大模型。
背景技术:
1、transformer作为一种使用自注意力机制的结构,被广泛应用于各类语言模型和视觉模型中,并扩展到计算机视觉等其他技术领域,基于transformer的大模型构建,具有更深的层结构和大规模的参数量,并能够在海量数据上进行训练,通常应用在问答模型和文生图模型中,表现出远超普通规模神经网络模型的性能。
2、所述大模型主要是使用通用领域数据训练的通用模型,将其迁移应用于具体下游任务时,大模型作为基座模型,使用特定领域数据进行微调,微调时会更新基座模型的全部参数,以大模型的参数规模,对计算平台有着极高的算力和内存需求,同时,如果针对多个下游任务进行全参微调,意味着每个具体任务需要学习一组新的参数,每一组参数的规模与原始基座模型参数规模一致,从而导致在训练、部署和存储方面都存在一定的困难。
3、针对大模型微调时巨大的计算量和内存开销的问题,现有技术提出了一种改进方案:低秩自适应方法,在固定预训练大模型权重的基础上,通过优化密集层的低秩分解权重矩阵达到训练的目的,在训练过程中仅调整低秩自适应层权重,部署时再合并预训练大模型权重和低秩自适应层权重。
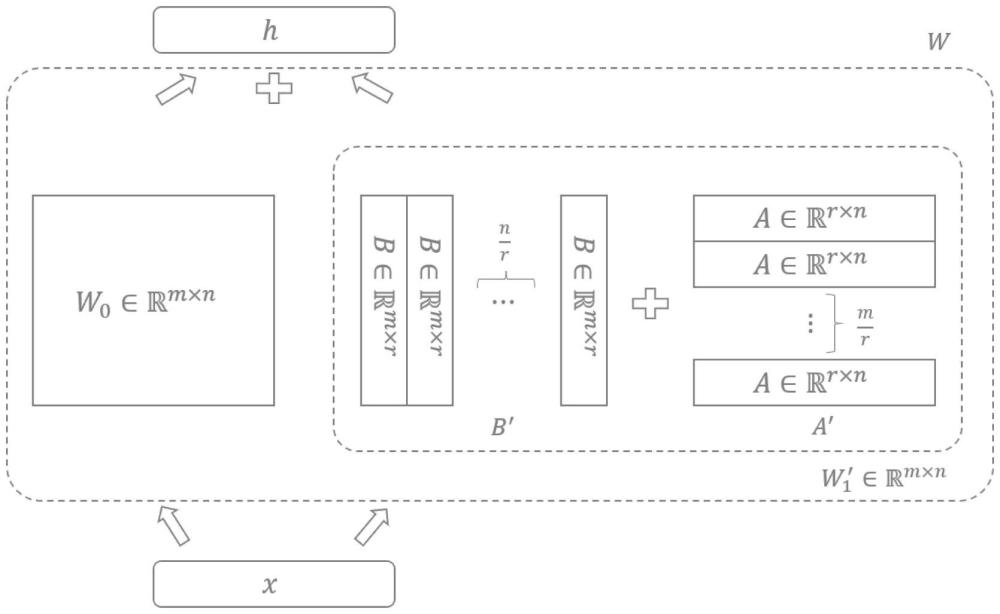
4、预训练大模型是基于transformer结构构建,具有深层网络结构,如图1所示,预训练大模型权重矩阵表示为低秩自适应层权重矩阵表示为其包含两个低秩权重矩阵a、b,其中r表示w1的秩,r<<min(m,n);低秩权重矩阵a为随机高斯初始化,低秩权重矩阵b初始化为零矩阵。
5、现有的低秩自适应方法中用2个低秩权重矩阵的乘积表示低秩自适应层权重矩阵,即w1=b×a,上述矩阵相乘的方法合并低秩权重矩阵使得计算复杂度增大,训练模型所需的算力和内存要求仍旧很高。
技术实现思路
1、为了降低低秩自适应方法中低秩权重矩阵相乘过程中的计算复杂度,优化训练模型所需的算力和内存要求,本发明提出一种“大模型低秩自适应层权重矩阵微调方法”。
2、大模型低秩自适应层权重矩阵微调方法,包括如下步骤:
3、步骤一、固定预训练大模型权重,初始化低秩自适应层权重:预训练大模型权重矩阵低秩自适应层权重矩阵其包含两个低秩权重矩阵a、b,其中矩阵矩阵m为低秩自适应层权重矩阵的行数,n为低秩自适应层权重矩阵的列数,r表示w1的秩,r<<min(m,n),所述矩阵a为随机高斯初始化,所述矩阵b初始化为零矩阵;
4、步骤二、使用特定领域数据训练更新低秩分解权重矩阵的参数;
5、步骤三、通过将步骤一中两个低秩权重矩阵a和b合并为低秩自适应层权重矩阵;
6、步骤四、合并预训练大模型权重和低秩自适应层权重,针对不同下游任务部署模型;
7、所述步骤三中两个低秩权重矩阵a的b合并包括将矩阵a和矩阵b分别复制拼接后相加或者将矩阵a和矩阵b分别划分为子矩阵后逐一相加子矩阵。
8、技术效果:
9、1.通过实施例1中复制两个低秩权重矩阵后再拼接成为低秩自适应层权重矩阵,相比于将两个低秩权重矩阵相乘的方式,能够降低矩阵低秩分解的计算复杂度,同时还能提升低秩权重矩阵的秩;
10、2.通过实施例2中将两个低秩权重矩阵划分为子矩阵、特征复用,降低矩阵低秩分解的计算复杂度的基础上进一步降低大模型训练时显存消耗大的技术问题;
11、3.针对不同下游任务微调时,独立训练并切换对应的权重参数,能够提高不同微调权重的训练效率、降低权重内存需求。
12、现有的低秩自适应方法中w1=b×a,微调参数量为mr+rn,计算复杂度为rmn,w1的秩为rank(w1)≤min(rank(b),rank(a))。
13、相比于现有的低秩自适应方法,本发明实施例1和实施例2中微调参数量为mr+rn,计算复杂度为r(m+n),w'1的秩rank(w'1)≤rank(b)+rank(a),w″1的秩rank(w″1)≤rank(b)+rank(a),在参数量不变的情况下,相比于现有低秩自适应方法,将计算复杂度从rmn降低为r(m+n),同时提升低秩权重矩阵的秩,使模型的特征表达具有更丰富的信息承载量。
14、本发明实施例2中通过两个低秩权重矩阵划分为子矩阵、特征复用,相比于实施例1能够缓解模型训练过程中的内存消耗过大、i/o读写过于频繁的技术问题,进而有效提升模型训练的效率,在单块显存为40gb的nvidiaa100显卡上,使用特定领域数据对60亿参数的chatglm模型进行微调,相比实施例1的训练时间效率提升10倍。
15、综上,本发明能够降低低秩自适应层权重矩阵相乘的计算复杂度,减少了训练模型所需的算力,降低内存需求,并提升模型的训练效率。
技术特征:
1.大模型低秩自适应层权重矩阵微调方法,包括如下步骤:
2.根据权利要求1所述的大模型低秩自适应层权重矩阵微调方法,其特征在于:所述步骤三中两个低秩权重矩阵a和b合并包括将矩阵a和矩阵b分别复制拼接后相加,具体为:
3.根据权利要求1所述的大模型低秩自适应层权重矩阵微调方法,其特征在于:所述步骤三中两个低秩权重矩阵a和b合并包括将矩阵a和矩阵b分别划分为子矩阵后逐一相加子矩阵,具体为:
4.根据权利要求1所述的大模型低秩自适应层权重矩阵微调方法,其特征在于:所述步骤四中合并预训练大模型权重和低秩自适应层权重,具体为:将固定的预训练大模型权重和使用特定领域训练的低秩自适应层权重合并,作为大模型的低秩矩阵微调权重,即w=w0+w1,模型推理过程表示为h=w0x+w1x,其中x表示输入数据、h表示输出数据,当针对不同下游任务部署模型时,只需要替换相应的低秩自适应层权重矩阵,针对低秩自适应层权重矩阵的低秩分解矩阵进行训练。
技术总结
本发明属于深度学习的大模型技术领域,为了降低低秩自适应方法中低秩权重矩阵相乘过程中的计算复杂度,优化训练模型所需的算力和内存要求,本发明提出一种“大模型低秩自适应层权重矩阵微调方法”,通过将两个低秩权重矩阵分别复制拼接后相加或者将两个低秩权重矩阵分别划分为子矩阵后逐一相加子矩阵,相比于将两个低秩权重矩阵相乘的方式,能够降低矩阵低秩分解的计算复杂度,同时还能提升低秩权重矩阵的秩,针对不同下游任务微调时,独立训练并切换对应的权重参数,提高不同微调权重的训练效率、降低权重内存需求。
技术研发人员:赵阳,王振鑫,刘鸿儒,贺亮,宋进,杜宛泽,张俊鹏,徐光洋
受保护的技术使用者:吉林省吉林祥云信息技术有限公司
技术研发日:
技术公布日:2025/3/16
- 还没有人留言评论。精彩留言会获得点赞!