一种基于大模型的多模态RAG、装置、设备及存储介质的制作方法
本发明涉及人工智能,尤其涉及一种基于大模型的多模态rag、装置、设备及存储介质。
背景技术:
1、在人工智能领域,大模型rag(检索增强生成技术)已成为近年来研究的热点。它结合了检索和生成两大关键技术,为自然语言处理任务带来了革命性的进步。rag利用大规模的语料库进行信息检索,为生成过程提供丰富的背景知识和上下文信息,从而提高生成结果的准确性和多样性。rag广泛应用于文本生成,对话系统、问答系统等领域。
2、rag主要工作流程包括:
3、1、预处理:首先,对大规模的语料库进行预处理,包括分词、去除停用词、构建词汇表等步骤。这些预处理操作有助于提取出文本中的有效信息,为后续的检索和生成过程奠定基础。
4、2、检索:在生成过程中,rag技术会根据当前的上下文信息,在语料库中检索相关的文本片段。这个检索过程通常基于某种相似度度量方法,如余弦相似度f等。检索结果将作为生成过程的参考和补充。
5、3、生成:在得到检索结果后,rag技术会利用生成模型(如transformer、gpt等)来生成新的文本。生成过程会综合考虑当前的上下文信息、检索结果以及生成模型自身的知识库,从而生成更加准确、多样的文本。
6、4、后处理:最后,对生成的文本进行后处理,包括去除重复、修正语法错误等步骤。这些后处理操作有助于提高生成结果的质量。
7、但在上述工作流程中,目前也存在一定的问题:(1)预处理阶段,通常是支持简单的文字解析,不能够全面精准地提取文本信息;(2)通过简单的召回,无法跨区域,精准地检索到问题相关的文本片段。综上所述,预处理阶段的局限性和检索过程的不足都会对rag的整个工作流程产生负面影响,其不仅影响检索准确性,还会使得生成效率低下。
技术实现思路
1、本发明的目的是提供一种基于大模型的多模态rag、装置、设备及存储介质,旨在解决现有rag处理流程的预处理阶段的局限性及检索过程的不足会影响整个工作流程检索的准确性,同时使得生成效率低下的技术问题。
2、为解决上述技术问题,本发明的目的是通过以下技术方案实现的:
3、本申请的第一方面提供了一种基于大模型的多模态rag,包括以下步骤:
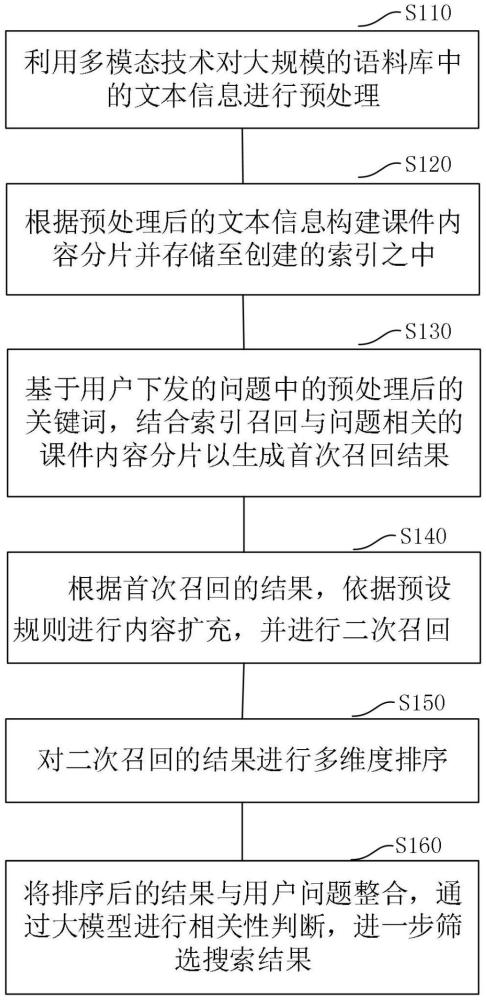
4、利用多模态技术对大规模的语料库中的文本信息进行预处理;
5、根据预处理后的文本信息构建课件内容分片并存储至创建的索引之中;
6、基于用户下发的问题中的预处理后的关键词,结合索引召回与问题相关的课件内容分片以生成首次召回结果;
7、根据首次召回的结果,依据预设规则进行内容扩充,并进行二次召回;
8、对二次召回的结果进行多维度排序;
9、将排序后的结果与用户问题整合,通过大模型进行相关性判断,进一步筛选搜索结果。
10、在一种可能的实现方式中,所述利用多模态技术对大规模的语料库中的文本信息进行预处理的步骤包括:
11、将来自不同平台的训练课件作为语料库,所述训练课件包括不同格式的文档以及音视频;
12、对语料库中的文本进行有效提取,所述提取方式包括使用多种不同的库和工具进行提取。
13、在一种可能的实现方式中,所述根据预处理后的文本信息构建课件内容分片并存储至创建的索引之中的步骤包括:
14、定义索引的映射;
15、将课件内容分片转换成向量表示。
16、在一种可能的实现方式中,所述将课件内容分片转换成向量表示的步骤包括:
17、加载一个预训练的词嵌入模型,将文本中的每个词转换成对应的向量表示;
18、使用向量字段在索引中存储所述向量表示;
19、定义向量字段的类型、维度和距离度量方式。
20、在一种可能的实现方式中,所述基于用户下发的问题中的预处理后的关键词,结合索引召回与问题相关的课件内容分片以生成首次召回结的步骤包括:
21、利用去除停用词、词干提取、意图判断、抽取关键词以及关键词加权的方式进行关键词预处理;
22、利用倒排索引对经过处理的关键词进行查询;
23、计算查询问题向量与课件内容分片向量之间的相似度;
24、根据相似度召回与问题相关的课件内容分片。
25、在一种可能的实现方式中,所述依据预设规则进行内容扩充的步骤包括:
26、设定向前扩充n页和向后扩充m页;
27、根据实际业务需求和课件内容的特点调整n和m值的大小。
28、在一种可能的实现方式中,所述对二次召回的结果进行多维度排序,其中,所述多维度包括:意图识别、字聚合密度、关键词的权重及模糊匹配度。
29、本申请的第二方面提供了一种基于大模型的多模态rag装置,所述装置包括:
30、预处理单元,用于利用多模态技术对大规模的语料库中的文本信息进行预处理;
31、索引构建单元,用于根据预处理后的文本信息构建课件内容分片并存储至创建的索引之中;
32、首次召回单元,用于基于用户下发的问题中的预处理后的关键词,结合索引召回与问题相关的课件内容分片以生成首次召回结果;
33、二次召回单元,用于根据首次召回的结果,依据预设规则进行内容扩充,并进行二次召回;
34、排序单元,用于对二次召回的结果进行多维度排序;
35、文本生成单元,用于将排序后的结果与用户问题整合,通过大模型进行相关性判断,进一步筛选搜索结果。
36、本申请的第三方面提供了一种计算机设备,其特征在于,所述计算机设备包括存储器及处理器,所述存储器上存储有计算机程序,所述处理器执行所述计算机程序时实现如上述第一方面中所述的方法。
37、本申请的第四方面提供了计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序包括程序指令,所述程序指令当被处理器执行时可实现如上述第一方面所述的方法。
38、本发明与现有技术相比的有益效果是:本发明提供了一种基于大模型的多模态rag、装置、设备及存储介质,包括以下步骤:利用多模态技术对大规模的语料库中的文本信息进行预处理;根据预处理后的文本信息构建课件内容分片并存储至创建的索引之中;基于用户下发的问题中的预处理后的关键词,结合索引召回与问题相关的课件内容分片以生成首次召回结果;根据首次召回的结果,依据预设规则进行内容扩充,并进行二次召回;对二次召回的结果进行多维度排序;将排序后的结果与用户问题整合,通过大模型进行相关性判断,进一步筛选搜索结果。相比于现有技术,本发明通过引入多模态技术、二次召回策略以及大模型的使用大大增加了召回内容的准确度,并且提高了生成效率。
技术特征:
1.一种基于大模型的多模态rag,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于大模型的多模态rag,其特征在于,所述利用多模态技术对大规模的语料库中的文本信息进行预处理的步骤包括:
3.根据权利要求1所述的一种基于大模型的多模态rag,其特征在于,所述根据预处理后的文本信息构建课件内容分片并存储至创建的索引之中的步骤包括:
4.根据权利要求3所述的一种基于大模型的多模态rag,其特征在于,所述将课件内容分片转换成向量表示的步骤包括:
5.根据权利要求1所述的一种基于大模型的多模态rag,其特征在于,所述基于用户下发的问题中的预处理后的关键词,结合索引召回与问题相关的课件内容分片以生成首次召回结果的步骤包括:
6.根据权利要求1所述的一种基于大模型的多模态rag,其特征在于,所述依据预设规则进行内容扩充,包括:
7.根据权利要求1所述的一种基于大模型的多模态rag,其特征在于,所述对二次召回的结果进行多维度排序,其中,所述多维度包括:意图识别、字聚合密度、关键词的权重及模糊匹配度。
8.一种基于大模型的多模态rag装置,其特征在于,所述装置包括:
9.一种计算机设备,其特征在于,所述计算机设备包括存储器及处理器,所述存储器上存储有计算机程序,所述处理器执行所述计算机程序时实现如权利要求1-7中任一项所述的方法。
10.一种计算机可读存储介质,其特征在于,所述存储介质存储有计算机程序,所述计算机程序包括程序指令,所述程序指令当被处理器执行时可实现如权利要求1-7中任一项所述的方法。
技术总结
本发明公开了一种基于大模型的多模态RAG、装置、设备及存储介质,包括以下步骤:利用多模态技术对大规模的语料库中的文本信息进行预处理;根据预处理后的文本信息构建课件内容分片并存储至创建的索引之中;基于用户下发的问题中的预处理后的关键词,结合索引召回与问题相关的课件内容分片以生成首次召回结果;根据首次召回的结果,依据预设规则进行内容扩充,并进行二次召回;对二次召回的结果进行多维度排序;将排序后的结果与用户问题整合,通过大模型进行相关性判断,进一步筛选搜索结果。相比于现有技术,本发明通过引入多模态技术、二次召回策略以及大模型的使用大大增加了召回内容的准确度,并且提高了生成效率。
技术研发人员:杨修远
受保护的技术使用者:深圳城智通信息技术有限公司
技术研发日:
技术公布日:2025/2/5
- 还没有人留言评论。精彩留言会获得点赞!