一种训练端到端的自动驾驶策略的方法
本发明涉及自动驾驶训练模型,尤其涉及一种训练端到端的自动驾驶策略的方法。
背景技术:
1、端到端自动驾驶旨在建立一个单一的模型,该模型能够直接将来自车辆传感器如摄像头、激光雷达、毫米波雷达、gps的数据作为输入,并输出车辆的控制指令如方向盘转角、油门踏板力度、刹车踏板力度,而无需中间的人工干预或多个独立模块的拼接,这种方法简化了自动驾驶系统的设计和实现,提高了系统的效率和可靠性。
2、在现有技术中,虽然现有的一种训练端到端的自动驾驶策略的方法首先利用车辆自带的传感器收集数据,并利用这些数据使用合适的端到端的自动驾驶模型对这些数据进行训练,通过循环训练并评估使得模型的性能变得完善,且增加模型的安全性,但是这种方法在实际的使用过程中,端到端自动驾驶模型高度依赖大量的数据来学习输入和输出之间的复杂映射关系,因此该方法使用时会涉及到大量的数据,这会导致模型参数量大,每轮训练的计算量高,导致训练时间显著增加,训练的效率低,且大量的参数使得模型的内存占用高,限制了模型在资源受限设备上的部署,降低了模型的适用性。
3、因此,有必要提供一种新的训练端到端的自动驾驶策略的方法解决上述技术问题。
技术实现思路
1、为解决上述技术问题,本发明提供一种训练端到端的自动驾驶策略的方法。
2、本发明提供的训练端到端的自动驾驶策略的方法包括如下步骤:
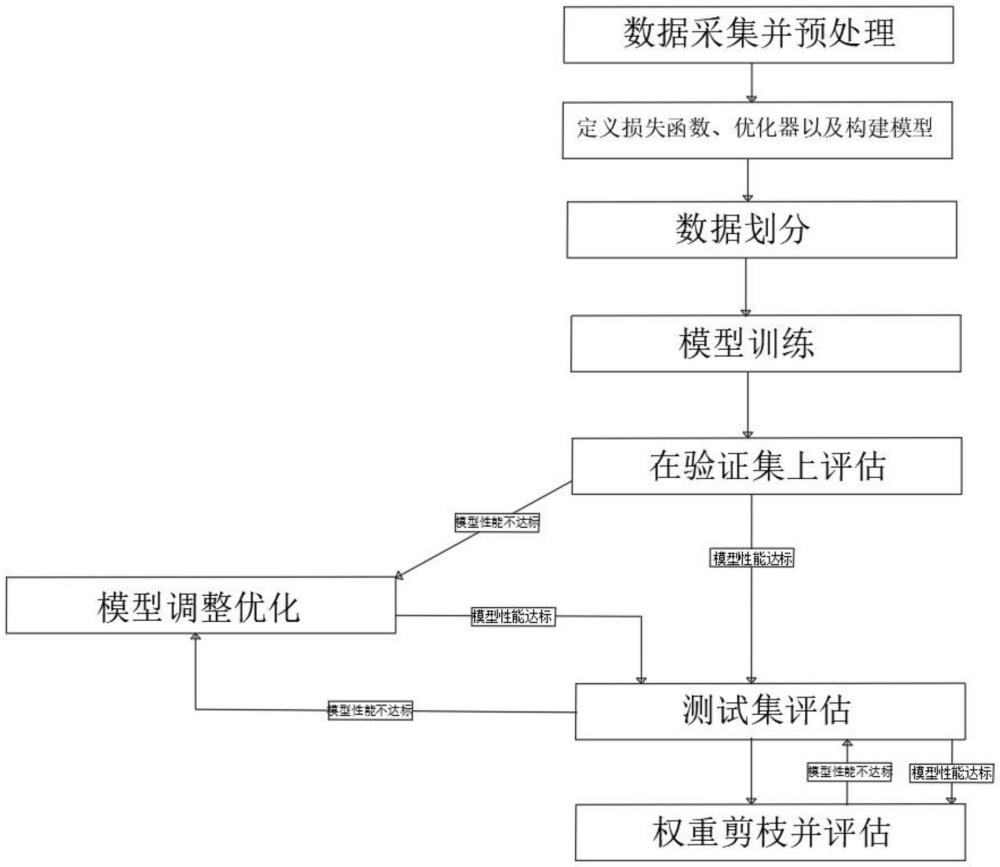
3、s1、数据采集并预处理,通过车辆自带的多种传感器采集车辆自动驾驶的数据,并通过统计滤波的方法对数据进行去噪处理;
4、s2、定义损失函数、优化器以及构建模型,采用基于卷积神经网络和循环神经网络的自动驾驶融合模型;
5、s3、数据划分,将步骤s1中经过预处理之后的数据划分为训练集、验证集以及测试集;
6、s4、模型训练,将步骤s3中训练集的数据按批次数据步骤s2中的自动驾驶融合模型内进行训练,在每个训练周期中,执行前向传播计算模型输出,然后根据损失函数计算误差,再通过反向传播算法计算梯度并通过优化器更新模型参数;
7、s5、在验证集上评估,在每个训练周期结束后,将验证集数据输入步骤s2中的自动驾驶融合模型,计算损失值和其他相关评估指标;
8、s6、模型调整优化,根据验证集的结果调整模型超参数,采用学习率衰减策略调整学习率;
9、s7、测试集评估,使用测试集数据对步骤s2中自动驾驶融合模型进行评估,计算与验证集相同的评估指标,判断是否满足实际应用的性能要求,若未达到要求则返回步骤s6中;
10、s8、权重剪枝并评估,采用梯度范数计算的方式,计算评估每个权重的重要性,根据重要性评估结果按照从较小比例开始且逐步增加,并移除不重要的权重,使用步骤s7的测试集对实现权重剪枝后的模型进行评估,若此时模型性能不达标,则采用权重恢复策略恢复部分权重并重新评估直到模型性能达标。
11、优选的,所述步骤s1中的多种传感器包括:激光雷达、车辆速度传感器、摄像头以及毫米波雷达,通过该多种传感器对车辆自动驾驶时的多种数据进行有效采集。
12、优选的,所述步骤s2中定义损失函数包括:均方误差损失函数以及交叉熵损失函数,所述均方误差损失函数用于处理车辆控制的连续值,所述交叉熵损失函数用于处理车辆自动驾驶分类任务,所述优化器选择adam优化器。
13、优选的,所述adam优化器优化模型的参数为学习率,adam优化器根据每个参数的梯度历史信息来动态调整学习率的大小。
14、优选的,所述步骤s5中计算与验证集相同的评估指标包括:回归任务的均方根误差以及平均绝对误差。
15、优选的,所述步骤s8的具体步骤如下:
16、s801、评估重要性,采用梯度范数计算的方式,计算评估步骤s4中反向传播算法计算出的损失函数关于每个权重的梯度的重要性;
17、s802、权重剪枝,根据重要性评估结果,按照从较小比例的方式并逐步增加,移除不重要的权重;
18、s803、模型评估,使用步骤s7中的测试集对权重剪枝后的模型进行评估;
19、s804、调整结果,根据评估结果,若评估模型性能达标,则输出模型结果;若评估结果不达标,则采用权重回复策略恢复部分权重,并重新评估直到模型性能达标。
20、优选的,所述权重恢复策略通过随机初始化中获取初始值的方式来重新初始化部分剪枝的权重。
21、与相关技术相比较,本发明提供的训练端到端的自动驾驶策略的方法具有如下有益效果:
22、1、本发明通过采用梯度范数计算的方式,计算评估每个权重的重要性,并移除不重要的权重,减少了模型的复杂度,减少模型参数数量,使得模型在训练的过程中计算量减小,大大提升了模型的训练效率,减少模型训练的时间,且模型的参数数量减小,推理时的计算量降低,减轻计算负担,这使得模型在实际应用中能够更快地做出预测,加快系统在使用时的响应速度,增强了安全性,以及剪枝后的模型参数量减少,模型的内存占用显著降低,使得该模型适用性更广;
23、2、本发明通过设置的权重恢复策略,当进行权重剪枝后的模型在测试之后性能不达标时,此时通过权重恢复策略,恢复部分权重并重新评估直到模型性能达标,这有助于找到最合适的剪枝程度,这种迭代的过程使得模型在某些剪枝比例下,保持良好性能的同时减小系统的负担;
24、3、本发明通过选择基于卷积神经网络和循环神经网络的自动驾驶融合模型进行训练模型,为模型提供了处理复杂输入的能力,在面对新的传感器类型或数据融合需求时,模型有更好的扩展性。
技术特征:
1.一种训练端到端的自动驾驶策略的方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的训练端到端的自动驾驶策略的方法,其特征在于,所述s1步骤中的多种传感器包括:激光雷达、车辆速度传感器、摄像头以及毫米波雷达,通过该多种传感器对车辆自动驾驶时的多种数据进行有效采集。
3.根据权利要求1所述的训练端到端的自动驾驶策略的方法,其特征在于,所述s2步骤中定义损失函数包括:均方误差损失函数以及交叉熵损失函数,所述均方误差损失函数用于处理车辆控制的连续值,所述交叉熵损失函数用于处理车辆自动驾驶分类任务,所述优化器选择adam优化器。
4.根据权利要求3所述的训练端到端的自动驾驶策略的方法,其特征在于,所述adam优化器优化模型的参数为学习率,adam优化器根据每个参数的梯度历史信息来动态调整学习率的大小。
5.根据权利要求1所述的训练端到端的自动驾驶策略的方法,其特征在于,所述s5步骤中计算与验证集相同的评估指标包括:回归任务的均方根误差以及平均绝对误差。
6.根据权利要求1所述的训练端到端的自动驾驶策略的方法,其特征在于,所述s8步骤的具体步骤如下:
7.根据权利要求1所述的训练端到端的自动驾驶策略的方法,其特征在于,所述权重恢复策略通过随机初始化中获取初始值的方式来重新初始化部分剪枝的权重。
技术总结
本发明提供一种训练端到端的自动驾驶策略的方法,所述训练端到端的自动驾驶策略的方法包括一下步骤:S1、数据采集并预处理,S2、定义损失函数、优化器以及构建模型,S3、数据划分,S4、模型训练,S5、在验证集上评估,S6、模型调整优化,S7、测试集评估,S8、权重剪枝并评估,采用梯度范数计算的方式,计算评估每个权重的重要性,根据重要性评估结果按照从较小比例开始且逐步增加,并移除不重要的权重,使用步骤S7的测试集对实现权重剪枝后的模型进行评估,若此时模型性能不达标,则采用权重恢复策略恢复部分权重并重新评估直到模型性能达标,本发明通过权重剪枝使得模型系统适用性更广,系统训练效率更快。
技术研发人员:张玉新,寇洪瑞,王子煜,吕周航,郭孔辉
受保护的技术使用者:吉林大学
技术研发日:
技术公布日:2025/3/16
- 还没有人留言评论。精彩留言会获得点赞!