文本数据处理方法及装置、文本数据检测方法及装置
本发明涉及深度学习、对比学习领域,特别涉及一种文本数据处理方法及装置、文本数据检测方法及装置。
背景技术:
1、现在,诸如可灵ai、gpt-4v等大模型工具或机器人,已经具备了处理文本、图片、视频等多种模态数据的能力,进而能够自动输出人工智能生成内容(artificialintelligence generated content,aigc);其中,最能体现大模型领域技术的高速发展的是文本模态领域上技术的持续精进,其他模态的训练策略也基本遵循文本领域技术进行微改后使用。通过收集大规模噪声数据进行文本预训练、精心设计的模版数据进行指令微调、人力打标人类偏好数据进行对齐等训练策略后,大模型已经逐步逼近真实人类的写作行文习惯,文本aigc检测难度持续精进。
2、通过人力进行检测的方法变得非常困难同时效率低下,同时,随着大模型技术精进时间线持续拉长,文本aigc已经在文本中的多个领域涌现,请对应领域的专家进行aigc鉴定会耗费大量人力。同时由于大模型对多领域文本语义分布掌握程度不同,对应的检测难度也会出现变化,传统的通过算法进行文本aigc检测的方案除了普通用户或开发者无法直接进行实施的白盒方案,通过“人造文本-aigc文本”样本对进行端到端训练的黑盒方案通常会混合多个领域的数据进行联合训练,这忽略了领域之间文本分布及大模型对对应领域文本语义掌握程度的差异,同时对当下的文本进行aigc检测的效果也相当有限。
技术实现思路
1、为了解决上述问题,本发明提出一种文本数据处理方法及装置、文本数据检测方法及装置,使用基于深度学习与对比学习技术的多领域文本aigc检测增强方法强化现有aigc检测模型的效果。
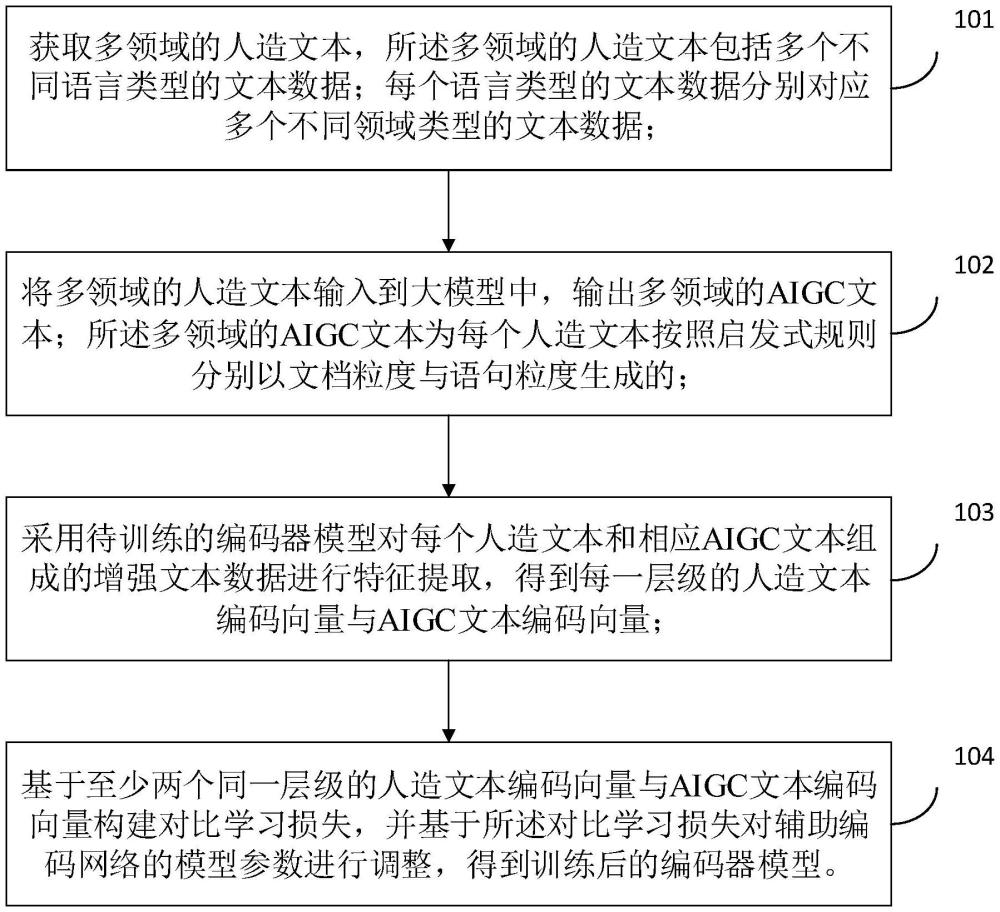
2、在本发明的第一方面,本发明提出了一种文本数据处理方法,所述方法包括:
3、获取多领域的人造文本,所述多领域的人造文本包括多个不同语言类型的文本数据;每个语言类型的文本数据分别对应多个不同领域类型的文本数据;
4、将多领域的人造文本输入到大模型中,输出多领域的aigc文本;所述多领域的aigc文本为每个人造文本按照启发式规则分别以文档粒度与语句粒度生成的;
5、采用待训练的编码器模型对每个人造文本和相应aigc文本组成的增强文本数据进行特征提取,得到每一层级的人造文本编码向量与aigc文本编码向量;所述编码器模型包括多层级的编码器网络和对应多层级的辅助编码网络;所述编码器网络包括多个层级的若干子网络层,所述辅助编码网络包括多个层级的若干辅助编码层,每一子网络层后连接有对应层级的辅助编码层;
6、基于至少两个同一层级的人造文本编码向量与aigc文本编码向量构建对比学习损失,并基于所述对比学习损失对辅助编码网络的模型参数进行调整,得到训练后的编码器模型。
7、在本发明的第二方面,本发明还提出了一种文本数据检测方法,所述方法包括:
8、获取待测文本数据;
9、对待测文本数据输入到训练后的编码器模型中,输出待测文本数据的文本编码向量;所述编码器模型为采用本发明第一方面所述文本数据处理方法中所述的训练后的编码器模型;
10、将待测文本数据的文本编码向量进行检测,得到待测文本数据的文本检测结果;
11、其中,所述文本检测结果为人造文本或者aigc文本,用于表示所述待测文本数据的文本内容来源。
12、在本发明的第三方面,本发明还提出了一种文本数据处理装置,所述装置包括:
13、第一获取单元,用于获取多领域的人造文本,所述多领域的人造文本包括多个不同语言类型的文本数据;每个语言类型的文本数据分别对应多个不同领域类型的文本数据;
14、增强处理单元,用于将多领域的人造文本输入到大模型中,输出多领域的aigc文本;所述多领域的aigc文本为每个人造文本按照启发式规则分别以文档粒度与语句粒度生成的;
15、第一提取单元,用于采用待训练的编码器模型对每个人造文本和相应aigc文本组成的增强文本数据进行特征提取,得到每一层级的人造文本编码向量与aigc文本编码向量;所述编码器模型包括多层级的编码器网络和对应多层级的辅助编码网络;
16、第一调整单元,用于基于至少两个同一层级的人造文本编码向量与aigc文本编码向量构建损失,并基于所述损失对辅助编码网络的模型参数进行调整,得到训练后的编码器模型。
17、在本发明的第四方面,本发明还提出了一种文本数据检测装置,所述装置包括:
18、第二获取单元,用于获取待测文本数据;
19、第二提取单元,用于采用编码器模型对待测文本数据进行特征提取,得到待测文本数据的文本编码向量,所述编码器模型为采用本发明第一方面所述的文本数据处理方法中所述的训练后的编码器模型;
20、检测单元,用于对每个待测文本数据的文本编码向量进行检测,得到每个待测文本数据对应的文本检测结果;所述文本检测结果为人造文本或者aigc文本,用于表示所述待测文本数据的文本内容来源。
21、本发明的有益效果:
22、1、本发明使用大模型工具生成多领域aigc文本的启发式规则能够确保覆盖各领域中的各种文本aigc的情形,除了常用的利用大模型进行文本改写、修正、润色,还有利用大模型进行续写,或翻译后在润色、续写的情况,或仅对文本部分语句进行修改,充分保证了模型的对比学习效果,提高了模型在文本aigc检测领域的鲁棒性;
23、2、本发明采用在编码器模型每一层添加多领域联合低秩适应增强网络md-lora也即辅助编码网络,在训练时冻结编码器模型只训练对应的md-lora辅助网络,一方面加快了模型的训练速度与资源负载,一方面为模型提供了插件式的文本aigc检测增强方案,能够在合适的时候使用原模型进行检测,在面对高难样本时再结合md-lora辅助网络进行相关处理。同时文本向量在通过md-lora辅助网络时,由无偏置线性层组成的辅助编码降维模块能够秉持缩放不变性助力压缩向量至抽象语义低秩空间,保持分布压缩特征空间统一,而由有偏置线性层组成的编码升维模块确保对于不同领域的文本使用不同的平移分布升维至对应的语义可分空间,动态调控领域分布差异,防止语义分布互相干扰;
24、3、本发明采用多层级知识保护对比学习损失函数同时记录多个隐藏层结果向量,并根据网络层数动态采样隐藏层向量来进行损失计算,深化人造文本与aigc文本的对比进程至编码器模型内的多个层结点,同时将作为更新角色的md-lora辅助网络编码后的文本向量与编码器文本向量合并后再与编码器文本向量拉近语义空间分布,与aigc文本拉远语义空间分布,能够保证在编码器模型先验信息不过多损失的情况下,加大人造文本与aigc文本之间的语义分布间隔,综合batch内求得的对比损失,强化对比学习效果,降低现有黑盒模型的aigc检测难度。
技术特征:
1.一种文本数据处理方法,其特征在于,所述方法包括:
2.根据权利要求1所述的文本数据处理方法,其特征在于,按照启发式规则分别以文档粒度与语句粒度生成所述多领域的aigc文本包括按照prompt提示,对文档数据采用翻译、润色和续写中一种或多种方式的组合,生成aigc翻译文本、润色文本和续写文本中一种或多种方式的aigc文本;对语句数据采用润色方式,生成语义粒度aigc文本;所述文档数据为每个领域的人造文本;所述语句数据是按照高斯分布对语句粒度文本簇采样得到的;所述语句粒度文本簇是将每个领域的人造文本按照标点符号分句得到的。
3.根据权利要求2所述的文本数据处理方法,其特征在于,对语句数据采用润色方式,所述对语句数据采用润色方式,生成语义粒度aigc文本包括对语句数据采用润色方式,生成采样润色文本;将采样润色文本插入到语义粒度文本簇中,生成aigc句簇;按照标点符号合并aigc句簇,生成语义粒度aigc文本。
4.根据权利要求1所述的文本数据处理方法,其特征在于,所述辅助编码网络包括一个辅助编码降维模块以及对应领域个数的辅助编码升维模块;所述辅助编码降维模块包括一个无偏置项的线性层,所述辅助编码升维模块包括一个有偏置项的线性层。
5.根据权利要求4所述的文本数据处理方法,其特征在于,得到每一层级的人造文本编码向量与aigc文本编码向量的过程包括:
6.根据权利要求5所述的文本数据处理方法,其特征在于,所述基于至少两个同一层级的人造文本编码向量与aigc文本编码向量构建损失包括:
7.根据权利要求6所述的文本数据处理方法,其特征在于,所述基于预设层级间隔选择部分同一层级的人造文本编码向量与aigc文本编码向量包括当层级为第一阈值范围内时,按照第一间隔选择部分层级;当层级为第二阈值范围内时,按照第二间隔选择部分层级;当层级为第三阈值范围内时,按照第三间隔选择部分层级;当层级为第四阈值范围内时,按照第四间隔选择部分层级。
8.一种文本数据检测方法,其特征在于,所述方法包括:
9.一种文本数据处理装置,其特征在于,所述装置包括:
10.一种文本数据检测装置,其特征在于,所述装置包括:
技术总结
本发明涉及对比学习领域,特别涉及一种文本数据处理方法及装置、文本数据检测方法及装置,所述方法包括将多个领域的人造文本输入大模型工具按照启发式规则分别得到对应的AIGC文本,组成检测增强文本对,并通过多层级的编码器网络和对应多层级的辅助编码网络分别对检测增强文本对中的文本进行编码,并使用多层级知识保护对比学习损失函数优化编码器模型。本发明使编码器模型能够同时对多个领域的文本数据进行无领域语义混淆的高精度文本AIGC检测并能在保持原始知识分布细微变化的情况下拉开人造文本与AIGC文本之间的语义分布,实现插件式的检测领域拓展与检测精度增强。
技术研发人员:钟时,王进,王世成,杨成
受保护的技术使用者:重庆邮电大学
技术研发日:
技术公布日:2025/3/16
- 还没有人留言评论。精彩留言会获得点赞!