一种基于大模型和知识图谱的信息处理方法及系统与流程
本发明涉及信息处理,更具体地说,涉及一种基于大模型和知识图谱的信息处理方法及系统。
背景技术:
1、随着互联网技术的飞速进步和数据量的急剧增长,信息检索(informationretrieval, ir)技术在现代社会中发挥着举足轻重的作用。传统的信息检索方法,诸如基于关键词的搜索技术和向量空间模型(vector space model, vsm),在面对海量数据时,逐渐暴露出了一系列挑战。这些方法主要依赖于关键词的字面匹配和文档索引技术,用户通过输入关键词或短语,系统会在预先构建的文档索引库中查找并返回包含这些关键词的文档。
2、尽管这种技术方案在处理简单查询时表现出较高的效率,但在面对具有复杂语义或歧义的查询时,其局限性便显露无遗。传统方法主要基于关键词的字面匹配,缺乏对查询语义的深入理解。由于自然语言中存在大量的多义词和同义词,同一个关键词在不同上下文中可能具有截然不同的含义。然而,传统检索方法难以有效区分这些不同的语义,导致在面对复杂或歧义的查询时,难以返回准确且相关的结果。另外,传统信息检索通常只关注查询关键词和文档之间的直接匹配程度,而忽略了查询和文档之间的上下文关系。这种忽视上下文的处理方式限制了系统对查询意图的准确理解,进而影响了检索效果。在实际应用中,用户查询往往带有特定的上下文背景,而传统方法无法有效捕捉和利用这些信息。
3、相关技术中,如中国专利cn115730083a提供了一种基于文本内容知识图谱的推荐方法,对文本内容进行信息加工形成三元组,构建对应文本的知识图谱;计算知识图谱向量,采用多向量融合的方式获取文本的知识表示向量;针对查询文本与候选文本的知识表示向量使用注意力机制对向量进行加权处理;通过神经网络模型计算查询文本与候选文本之间的点击概率,并基于点击概率进行推荐。该方案不足之处在于仍旧依赖于关键词匹配和文档索引技术,且未能有效解决了传统信息检索中的语义鸿沟问题。
技术实现思路
1、1.要解决的技术问题
2、针对现有技术中存在的如何提高信息检索中的搜索结果的准确性的问题,本发明提供了一种基于大模型和知识图谱的信息处理方法及系统,它可以实现通过在信息检索时结合大语言模型的生成能力,生成更多样化和更全面的检索结果,返回更精确的检索结果。
3、2.技术方案
4、本发明的目的通过以下技术方案实现。
5、本申请的内容部分用于以简要的形式介绍构思,这些构思将在后面的具体实施方式部分被详细描述。本申请的内容部分并不旨在标识要求保护的技术方案的关键特征或必要特征,也不旨在用于限制所要求的保护的技术方案的范围。
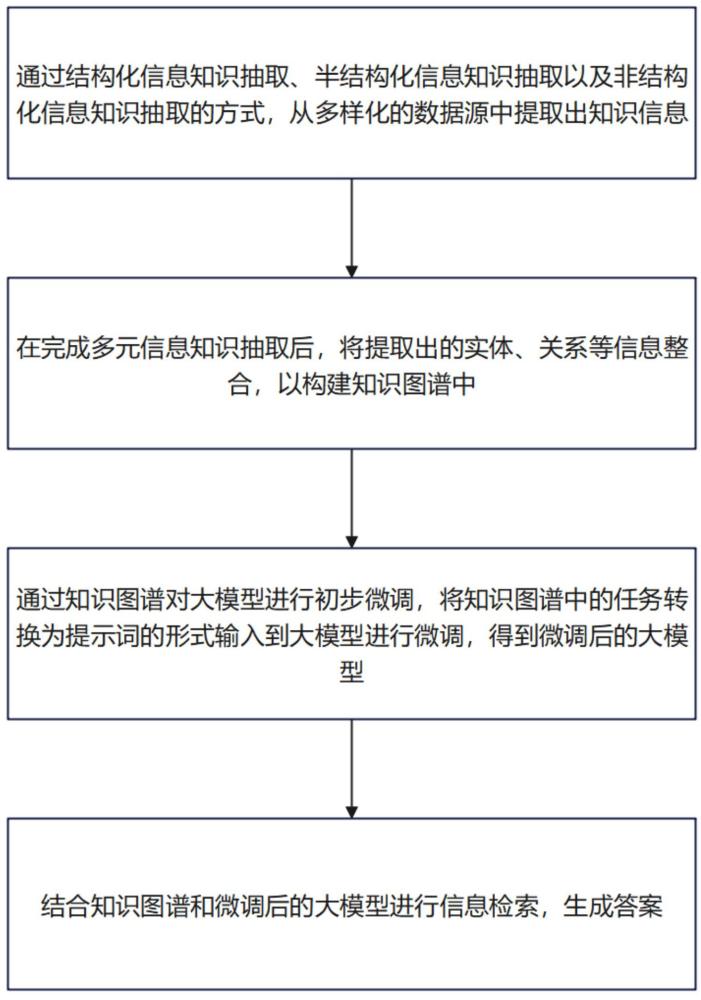
6、本申请的一些实施例提出了一种基于大模型和知识图谱的信息处理方法及系统,来解决以上背景技术部分提到的技术问题。作为本申请的第一方面,本申请的一些实施例提供了一种基于大模型和知识图谱的信息处理方法,包括以下步骤:通过结构化信息知识抽取、半结构化信息知识抽取以及非结构化信息知识抽取,从数据源中抽取知识信息;将抽取出知识信息中的实体信息及关系信息整合,构建知识图谱;将知识图谱中的任务转换为提示词的形式输入到大模型进行微调,得到微调后的大模型;结合知识图谱和微调后的大模型进行信息检索并生成结果。
7、更进一步的,结构化信息知识抽取的过程是:针对结构化信息,通过sql查询将数据表中的记录映射为知识图谱中的实体与关系。
8、更进一步的,半结构化信息知识抽取的过程是:针对半结构化信息,利用正则表达式,通过匹配半结构化数据中的特定模式,提取信息。
9、更进一步的,非结构化信息知识抽取的过程是:针对非结构化信息,通过构建bi-gru+crf神经网络模型进行知识抽取;bi-gru+crf 神经网络模型包括词嵌入层、bi-gru层以及crf层。
10、更进一步的,构建知识图谱的过程包括:定义图谱的节点与边、图谱存储以及微调大模型。
11、更进一步的,在图谱存储过程中,采用neo4j图数据库存储知识图谱。
12、更进一步的,微调大模型的步骤包括:将知识图谱信息转换为提示词;将知识图谱信息转换为提示词以及采用lora微调大模型。
13、更进一步的,微调大模型的计算过程具体包括:将知识图谱信息转换为提示词,表达式如下:
14、;
15、其中,t表示知识图谱信息,表示转换得到的提示词,表示将知识图谱信息转换为提示词的过程;
16、构建包含输入为以及输出为的训练数据集d,使用数据集d和损失函数l微调大模型lm,微调大模型的表达式如下:
17、;
18、;
19、其中,表示输入,表示输出,表示模型参数,表示大模型在模型参数下的输出,表示微调后的参数;表示微调后的大模型,即微调大模型的结果。
20、更进一步的,信息检索的步骤包括:将知识图谱结构转换为大模型的提示词;大模型分析输入问题和图谱结构对应的提示词,生成cypher检索语句以及大模型根据知识图谱的检索结果,生成答案。
21、作为本申请的第二方面,本申请的一些实施例提供了一种基于大模型和知识图谱的信息处理方法的系统,包括多元信息知识抽取模块:通过结构化信息知识抽取、半结构化信息知识抽取以及非结构化信息知识抽取,从数据源中抽取知识信息;构建知识图谱模块:将抽取出知识信息中的实体信息及关系信息整合,构建知识图谱;微调模块:将知识图谱中的任务转换为提示词的形式输入到大模型进行微调,得到微调后的大模型;信息检索模块:结合知识图谱和微调后的大模型进行信息检索并生成结果。
22、3.有益效果
23、相比于现有技术,本发明的优点在于:本发明的基于大模型和知识图谱的信息处理方法及系统通过知识图谱构建实体、关系和属性的结构化数据,能够准确表达和理解查询中的语义信息;结合大语言模型对自然语言文本的深度理解能力,更准确地理解用户查询意图,从而返回更加精确的检索结果。另外,由于知识图谱包含丰富的实体和关系信息,本发明通过结合包含丰富的实体和关系信息的知识图谱,使得处理过程中能够覆盖更广泛的知识领域,结合大语言模型的生成能力,实现生成更加多样化和更加全面的更准确的检索结果。
技术特征:
1.一种基于大模型和知识图谱的信息处理方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于大模型和知识图谱的信息处理方法,其特征在于:
3.根据权利要求1所述的基于大模型和知识图谱的信息处理方法,其特征在于:
4.根据权利要求1所述的基于大模型和知识图谱的信息处理方法,其特征在于:
5.根据权利要求1所述的基于大模型和知识图谱的信息处理方法,其特征在于:
6.根据权利要求5所述的基于大模型和知识图谱的信息处理方法,其特征在于:
7.根据权利要求5所述的基于大模型和知识图谱的信息处理方法,其特征在于:
8.根据权利要求5所述的基于大模型和知识图谱的信息处理方法,其特征在于:
9.根据权利要求1所述的基于大模型和知识图谱的信息处理方法,其特征在于:
10.基于权利要求1-9任一所述的基于大模型和知识图谱的信息处理方法的系统,其特征在于:
技术总结
本发明公开了一种基于大模型和知识图谱的信息处理方法及系统,属于信息处理技术领域。包括以下步骤:通过结构化信息知识抽取、半结构化信息知识抽取以及非结构化信息知识抽取,从数据源中抽取知识信息;将抽取出知识信息中的实体信息及关系信息整合,构建知识图谱;将知识图谱中的任务转换为提示词的形式输入到大模型进行微调,得到微调后的大模型;结合知识图谱和微调后的大模型进行信息检索并生成结果。相较于现有技术,本发明的有益之处在于,结合包含丰富的实体和关系信息的知识图谱,使得处理过程中能够覆盖更广泛的知识领域,结合大语言模型的生成能力,实现生成更加多样化和更加全面的更准确的检索结果。
技术研发人员:单海峰,杨垠彬,罗前春,余晓龙,孙井花,范沐阳,束永丽,陈美,丁闯
受保护的技术使用者:中电信无人科技(江苏)有限公司
技术研发日:
技术公布日:2025/1/2
- 还没有人留言评论。精彩留言会获得点赞!