一种基于无监督词重构的评论主题识别方法、系统、设备及存储介质
本发明属于计算机自然语言处理领域,涉及一种基于无监督词重构的评论主题识别方法、系统、设备及存储介质。
背景技术:
1、方面级情感分析技术是自然语言处理领域的挑战性研究课题。多数深度学习方法的性能依赖于大规模人工标注数据集,但标注大量的高质量数据集是一项耗时费力的工作,因此有标注数据集的缺乏已成为制约深度情感分类算法的瓶颈问题。幸运的是,不同网络平台用户生成了大量带标签的舆情文本(如带评分的商品评论和电影评论,带表情符号的推特评论等),这些文本可以作为弱标注数据集被用于情感分类任务。然而,弱标注数据中存在着标签与文本实际情感语义不一致的噪声数据,会对训练过程产生严重的负面影响,因此无法直接当作强标注数据用于训练深度模型。此外,多数弱标注评论文本没有清晰地指明所描述的方面词,缺乏方面信息指导的模型无法有效学习到评论文本的细粒度情感特征。
技术实现思路
1、本发明的目的在于克服上述现有技术的缺点,提供一种基于无监督词重构的评论主题识别方法、系统、设备及存储介质,能够精准识别无标注输入文本中的主题词。
2、为达到上述目的,本发明采用以下技术方案予以实现:
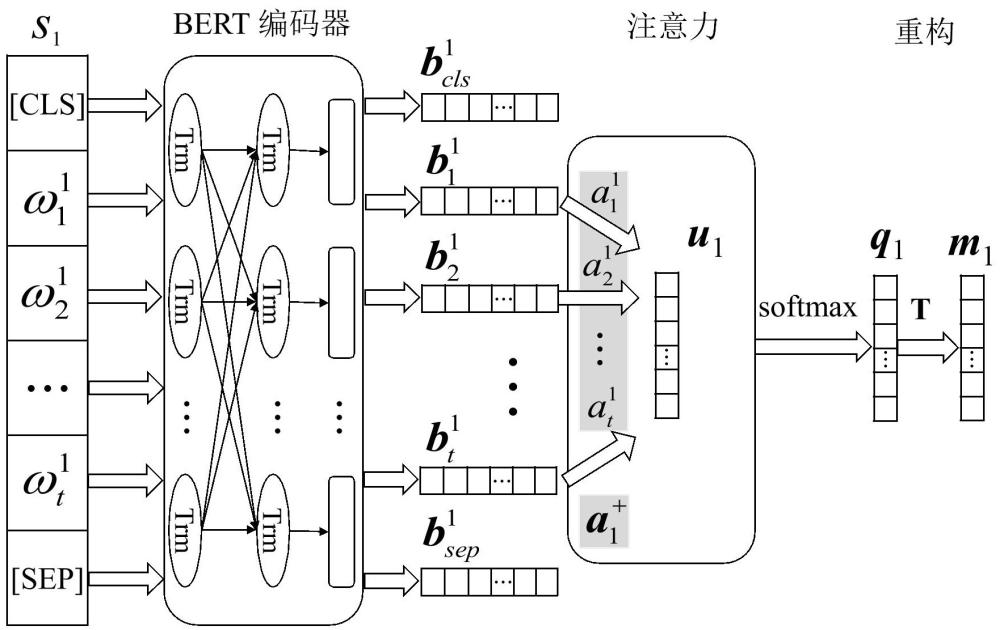
3、一种基于无监督词重构的评论主题识别方法,包括以下过程:
4、s1,获取训练文本数据,将训练文本数据编码后得到向量矩阵;
5、s2,将向量矩阵通过注意力加权运算得到训练文本数据的文本特征;
6、s3,对文本特征进行降维计算后进行重构,得到主题词向量的线性组合;
7、s4,将主题词向量的线性组合分类为相应的主题,选取可能性最高的结果为最终的主题词。
8、优选的,s1中,训练文本数据以单文本序列进行编码。
9、优选的,s1中,采用bert编码器进行编码。
10、优选的,向量矩阵中包括每个单词的词特征表示,在s2中,对所有词特征表示求和后再求平均得到全局上下文向量,获取每个单词分配的注意力权重,对各个词特征表示进行加权运算得到文本特征。
11、优选的,s3中,重构过程为:
12、
13、
14、其中,是参数矩阵,是偏置向量;是一个标量,由无监督 k-means聚类算法确定,代表数据集中所出现的主题词的数量;表示数据集中 k个候选主题词的权重向量,该向量中的每一维元素分别表示训练文本数据属于相关主题词的概率;是主题词向量矩阵,使用 k-means聚类算法得到 k个簇心的特征表示,并以此对矩阵进行初始化;表示训练文本数据的重构特征表示,为主题词向量的线性组合。
15、优选的,s3中,采用优化目标函数对重构过程进行训练,目标为将经过注意力加权运算后得到的文本特征重构为融合了主题词信息的特征表示。
16、优选的,优化目标函数为:
17、
18、
19、
20、其中,优化目标函数由两部分构成:是重构损失项,作为正则项用于保证主题词向量的多样性,是超参数用以控制正则项在整体损失中所占的权重;为重构损失项,其中表示整个训练数据集,是数据集中的第条输入文本;表示从训练集中随机采样得到的负样本数量,其中第 j条负样本的特征使用表示,详细计算过程为:,即对第 j条负样本中所有单词对应的词特征求和再求平均;与均表示内积运算;为正则项,其中是通过对主题词向量矩阵进行了行标准化后得到的;而是一个单位矩阵;表示对矩阵进行列和范数运算。
21、一种基于无监督词重构的评论主题识别系统,包括:
22、编码模块,用于获取训练文本数据,将训练文本数据编码后得到向量矩阵;
23、加权模块,用于将向量矩阵通过注意力加权运算得到训练文本数据的文本特征;
24、重构模块,用于对文本特征进行降维计算后进行重构,得到主题词向量的线性组合;
25、分类模块,用于将主题词向量的线性组合分类为相应的主题,选取可能性最高的结果为最终的主题词。
26、一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现所述基于无监督词重构的评论主题识别方法的步骤。
27、一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现所述基于无监督词重构的评论主题识别方法的步骤。
28、与现有技术相比,本发明具有以下有益效果:
29、本发明利用了注意力机制对文本中的单词进行加权,强调了文本中最为相关的单词,忽略了其他不相关的单词,从而提高了主题词的提取精度。引入了特征重构思想,通过无监督的方式融合了数据集中主题词的特征信息,促使模型在训练过程中专注于挖掘与输入文本主题语义一致性最高的主题词,从而进一步提高了主题提取的准确性,实现了利用无监督学习的方式从无标注输入文本中准确提取主题词。
30、进一步,采用了基于bert模型的表征学习方法,能够充分提取输入文本中每个单词的高级词特征表示。
技术特征:
1.一种基于无监督词重构的评论主题识别方法,其特征在于,包括以下过程:
2.根据权利要求1所述的基于无监督词重构的评论主题识别方法,其特征在于,s1中,训练文本数据以单文本序列进行编码。
3.根据权利要求1所述的基于无监督词重构的评论主题识别方法,其特征在于,s1中,采用bert编码器进行编码。
4.根据权利要求1所述的基于无监督词重构的评论主题识别方法,其特征在于,向量矩阵中包括每个单词的词特征表示,在s2中,对所有词特征表示求和后再求平均得到全局上下文向量,获取每个单词分配的注意力权重,对各个词特征表示进行加权运算得到文本特征。
5.根据权利要求1所述的基于无监督词重构的评论主题识别方法,其特征在于,s3中,重构过程为:
6.根据权利要求1所述的基于无监督词重构的评论主题识别方法,其特征在于,s3中,采用优化目标函数对重构过程进行训练,目标为将经过注意力加权运算后得到的文本特征重构为融合了主题词信息的特征表示。
7.根据权利要求1所述的基于无监督词重构的评论主题识别方法,其特征在于,优化目标函数为:
8.一种基于无监督词重构的评论主题识别系统,其特征在于,包括:
9.一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至7任意一项所述基于无监督词重构的评论主题识别方法的步骤。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7任意一项所述基于无监督词重构的评论主题识别方法的步骤。
技术总结
本发明公开了一种基于无监督词重构的评论主题识别方法、系统、设备及存储介质,包括以下过程:S1,获取训练文本数据,将训练文本数据编码后得到向量矩阵;S2,将向量矩阵通过注意力加权运算得到训练文本数据的文本特征;S3,对文本特征进行降维计算后进行重构,得到主题词向量的线性组合;S4,将主题词向量的线性组合分类为相应的主题,选取可能性最高的结果为最终的主题词。促使模型在训练过程中专注于挖掘与输入文本主题语义一致性最高的主题词,从而进一步提高了主题提取的准确性,实现了利用无监督学习的方式从无标注输入文本中准确提取主题词。
技术研发人员:陈龙,卢绍帅,熊立伟,黄晓华,关烁宇,王文静,杜怡,徐偲,管子玉,赵伟
受保护的技术使用者:西安邮电大学
技术研发日:
技术公布日:2025/3/18
- 还没有人留言评论。精彩留言会获得点赞!