面向社会治理知识图谱三元组构建的大模型提示模板生成方法
本发明涉及人工智能领域,具体是面向社会治理知识图谱三元组构建的大模型提示模板生成方法。
背景技术:
1、随着社会信息化的快速发展,社会治理领域积累了大量复杂数据。这些数据涵盖传统结构化信息与非结构化或半结构化数据,例如社交媒体帖子、新闻报道等。然而,这些数据常常分散在各个平台,形成“数据孤岛”,难以充分整合和利用。这一现象阻碍了社会治理效率的提升,也使得数据价值未能有效挖掘。
2、在此背景下,知识图谱作为一种高效的数据组织和表示形式,通过定义实体及其之间的关系,能够有效解决上述问题。它不仅有助于实现跨领域、跨系统的数据融合,还能够提供语义层面的理解和支持,使得机器能够更好地解析人类语言中的复杂含义,从而为决策支持、智能检索、精准服务等社会治理应用场景提供强大的支撑。然而,当前用到的知识图谱构建技术仍然面临挑战:现有数据预处理方法在大规模文本数据上耗时较长,且易受数据质量不一致的影响;同时,从文本中准确抽取实体和关系的能力仍有待提高,尤其是在社会治理领域多义性强、上下文复杂的情况下。
3、大语言模型(llm)的发展为解决这些问题提供了可能。通过提示工程技术,llm可以在模型内隐层次利用海量知识完成复杂任务。然而,提示模板的质量直接影响模型的表现。当前使用大模型方法构造知识图谱的过程多依赖人工设计的提示,既耗费大量人力,又难以适配不同任务场景,且缺乏动态优化能力,缺乏针对性的优化策略,导致在复杂场景中模型性能表现不足。
技术实现思路
1、本发明的目的在于提供面向社会治理知识图谱三元组构建的大模型提示模板生成方法,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:
3、面向社会治理知识图谱三元组构建的大模型提示模板生成方法,包括如下步骤:
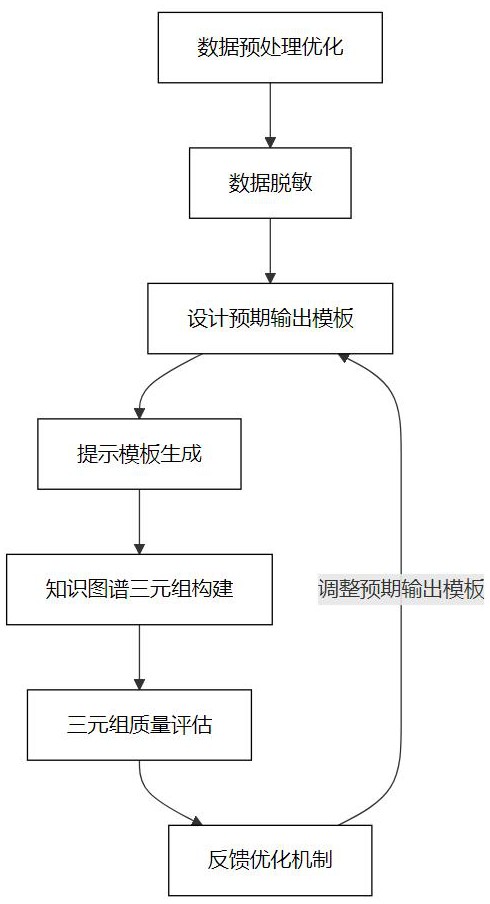
4、步骤s1、数据预处理优化:对社会治理文本数据进行清洗、去噪、格式化和结构化处理,确保数据质量和一致性。通过自然语言处理技术,去除无效、冗余、错误数据并进行标准化。
5、步骤s2、数据脱敏:对数据中的敏感信息进行脱敏处理,采用加密或匿名化技术,确保隐私保护。
6、步骤s3、设计预期输出模板:本步骤旨在构建大模型输出的知识图谱三元组格式,为模型定义一系列预期的输出模板,指导模型在处理数据时识别并提取文本中的关键实体以及实体之间的关系。
7、步骤s4、提示模板生成:在上一步的基础上,将预期输出输入给大模型,基于大语言模型自动生成大模型本身需要的、特定任务对应的提示模板,引导模型精准提取信息。生成的提示模板根据任务需求和输入文本智能调整,以适应不同场景。同时,生成的提示模板根据任务需求进一步优化,以提升模型任务执行的准确性和效率。
8、步骤s5、知识图谱三元组构建:基于提示模板,从社会治理文本中提取实体、关系和属性信息,并构建符合知识图谱标准的三元组。
9、步骤s6、三元组质量评估:通过计算相关指标,对生成的三元组进行质量评估。
10、步骤s7、反馈优化机制:根据评估结果调整提示预期输出来调整输出的提示模板,以此提升任务执行效果。
11、所述步骤s1中,数据预处理通过自动化方法实现,使用深度学习模型进行文本内容的语义分析,确保数据的一致性与准确性。
12、所述步骤s2中的数据脱敏采用哈希加密技术或通用标识符替代敏感数据,确保个人隐私信息不被泄露。
13、所述步骤s3中,预期的输出为人为的,并且根据具体任务场景构建,作为下一步提供给大模型用于生成提示的输出。
14、所述步骤s4中,提示模板生成不仅考虑任务需求,还基于上下文进行自适应调整,确保不同场景下模板的高效性和准确性。
15、所述步骤s5中,三元组构建通过高效的关系抽取和属性提取方法,确保生成的三元组符合标准格式并具备高质量。
16、所述步骤s6中步骤s6中,选择 f 1值作为评估指标来衡量三元组构建的质量, f 1值是准确率 p和召回率 r的调和平均值,综合衡量模型的整体性能,计算方式为:;准确率 p衡量模型正确识别三元组的比例,计算方式为,召回率 r衡量模型识别出所有真实三元组的比例, g p代表模型输出的三元组集合的总数, g t代表人为标注的三元组集合的总数,表示模型预测与真实标注的三元组交集大小;根据计算得到 f 1值,如果在0-1之间且接近1,则说明模型输出的三元组质量良好,反之,则说明大模型输出的提示模板需要进一步的调整。
17、所述步骤s7中,通过评估结果识别提示模板的不足,优化预期输出格式并调整模型。通过持续反馈循环,不断提升三元组生成质量,最终为社会治理和决策提供符合需求的输出。
18、与现有技术相比,本发明的有益效果是:
19、智能化提示模板生成:本发明通过大模型自动生成大模型本身需要的提示的模板,并基于输入文本和任务需求动态调整模板内容。这一过程区别于传统的人工设计模板,显著提升了社会治理任务的效率和准确性,特别是在任务的定制化和场景适配性方面具有显著优势。
20、任务适应性和定制化能力:本发明的提示模板能够根据不同的社会治理任务,如婚姻纠纷、社区管理等,自动生成和优化模板,确保模板在多种场景下的适用性和高效性。这一创新点使得本发明在处理复杂、多变的社会治理数据时具有优越性。
21、高效的数据处理和三元组构建:在生成的提示模板指导下,本发明能够精准、高效地提取社会治理文本中的关键信息,显著提高三元组构建的准确性,并通过标准化的三元组输出,为后续的数据分析和决策支持提供可靠基础。
22、可扩展性和通用性:本发明的技术方案支持跨区域、跨部门的治理需求,能够处理大规模的数据集,适应不同类型的社会治理场景,具备较强的扩展性和通用性。该技术不仅适用于当前社会治理领域,还可扩展应用到其他领域的数据处理和知识抽取任务。
技术特征:
1.面向社会治理知识图谱三元组构建的大模型提示模板生成方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的面向社会治理知识图谱三元组构建的大模型提示模板生成方法,其特征在于,步骤s1中的数据预处理中,使用深度学习模型进行文本内容的语义分析。
3.根据权利要求2所述的面向社会治理知识图谱三元组构建的大模型提示模板生成方法,其特征在于,步骤s2中的数据脱敏采用哈希加密技术或通用标识符替代敏感数据。
4.根据权利要求3所述的面向社会治理知识图谱三元组构建的大模型提示模板生成方法,其特征在于,步骤s6中,选择f1值作为评估指标来衡量三元组构建的质量,f1 值是准确率p和召回率r的调和平均值,综合衡量模型的整体性能,计算方式为:;准确率p衡量模型正确识别三元组的比例,计算方式为,召回率r衡量模型识别出所有真实三元组的比例,gp代表模型输出的三元组集合的总数,gt 代表人为标注的三元组集合的总数,表示模型预测与真实标注的三元组交集大小;根据计算得到f1值,如果在0-1之间且接近1,则说明模型输出的三元组质量良好,反之,则说明大模型输出的提示模板需要进一步的调整。
技术总结
本发明公开了面向社会治理知识图谱三元组构建的大模型提示模板生成方法,涉及人工智能领域,包括如下步骤:步骤S1、数据预处理优化;步骤S2、数据脱敏;步骤S3、设计预期输出模板;步骤S4、提示模板生成;步骤S5、知识图谱三元组构建;步骤S6、三元组质量评估;步骤S7、反馈优化机制。本发明通过大模型自动生成大模型本身需要的提示的模板,并基于输入文本和任务需求动态调整模板内容。这一过程区别于传统的人工设计模板,显著提升了社会治理任务的效率和准确性,特别是在任务的定制化和场景适配性方面具有显著优势。
技术研发人员:王博岳,吴博文,赵岚,张大宝,田甜
受保护的技术使用者:北京工业大学
技术研发日:
技术公布日:2025/1/20
- 还没有人留言评论。精彩留言会获得点赞!