基于图像-文本融合增强的多模态泊车检测系统的制作方法
本发明涉及自动泊车辅助技术,尤其涉及一种基于图像-文本融合增强的多模态泊车检测系统。
背景技术:
1、自动泊车辅助系统能够为用户在泊车场景中提供方便快捷的自动泊车功能,尤其在复杂场景下减少人工操作,避免因驾驶技术不佳导致的错误控制和车辆碰擦损失。基于摄像头的泊车感知检测是泊车辅助系统的重要一环,为后续的规划、定位、控制等模块提供车位/障碍物/可行驶区域等基础信息。
2、传统的泊车感知子系统基于多个鱼眼摄像头,在获取到多视角的鱼眼相机图像后,采用环视拼接的方式,生成360度环视拼接图,在环视拼接图进行相关的目标感知任务。用户需要手动在交互界面输入或点击想要泊入的车位,具有一定的不便性。
技术实现思路
1、为解决现有技术中存在的不足,本发明的目的在于,提供一种基于图像-文本融合增强的多模态泊车检测系统。
2、为实现本发明的目的,本发明所采用的技术方案是:
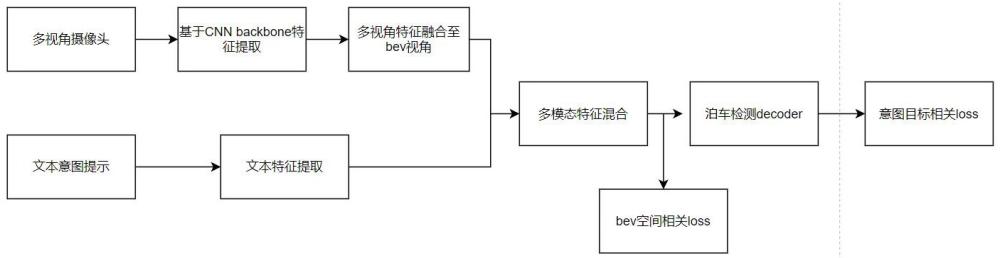
3、一种基于图像-文本融合增强的多模态泊车检测系统,包括多视角摄像头,基于cnn的摄像头特征提取模块,图像特征空间转换模块,文本模态信息,文本特征提取模块,多模态特征混合模块,多模态decoder模块;
4、多视角摄像头输入图像信息,基于cnn的摄像头特征提取模块提取多视角摄像头图像特征,图像特征空间转换模块,将多视角摄像头图像融合至bev视角,实现多视角图像特征到bev特征的转换;
5、输入文本模态信息,文本特征提取模块使用clip模型提取用户意图文本特征;
6、多模态特征融合模块,获得文本特征和bev grid特征后,多模态特征通过多通路的特征融合模块进行充分交融;多模态decoder模块,基于transformer的解码结构,最终输出带有用户特定意图的泊车车位输出。
7、进一步地,在多模态特征融合模块后引入bev空间相关loss,在多模态decoder模块后引入意图目标相关loss。
8、进一步地,基于cnn的摄像头特征提取模块,对于摄像头输入图像,使用基于cnn的backbone网络进行特征提取,并使用大规模的泊车场景开源数据集进行预训练;其中,backbone参数采用多摄像头共享的方式;最终每路摄像头输出c4和c3两种尺度的特征层用于后续的学习。
9、进一步地,图像特征空间转换模块,采用全连接层实现特征空间的隐式转换,每个bev grid特征由整个图像视图特征进行加权组合构成,对全连接层转换过后的特征值进行重新转换和对应位置相加,得到bev grid特征;
10、每个摄像头采用独立的全连接层参数实施,对每个摄像头的c3和c4特征输出,使用独立的bev grid生成通路,最终获得两种分辨率的bev特征图bf_scale0和bf_scale1。
11、进一步地,多模态特征融合模块,包括text-to-bev通路和bev-to-text通路;在text-to-bev通路中,bev grid特征用于生成k和v特征,文本特征生成q,通过混合特征模块得到新的bev grid特征,表示为new_bev_feature_scale0和new_bev_feature_scale1;
12、在bev-to-text通路中,文本特征生成k和v,bev grid特征生成q,最终获得新的文本特征,表示为new_text_feature。
13、进一步地,混合特征模块中,文本特征和bev grid特征通过交叉注意的方式进行融合。
14、进一步地,多模态decoder模块,图像特征空间转换模块中的bf_scale0和bf_scale1构成多尺度的bev grid特征;将多尺度的bev grid特征通过多模态特征融合模块后,分别获得融合后的多尺度bev grid特征和文本特征;
15、在多模态decoder模块中,设计n组query特征fq,用于在训练过程中学习拟合具有content表征的特征;decoder模块由多个transformer结构堆叠而成,在经过decoder模块后,最终获得用于意图车位输出的特征表达。
16、进一步地,基于transformer结构的目标检测框架中,使用混合引导查询位置嵌入生成器用于查询 pe 嵌入的初始化生成;该模块包含文本特征和bev grid特征的锚点框两部分引导进行生成。
17、进一步地,查询 pe 嵌入的初始化生成具体步骤:
18、在融合后获得的new_bev_feature,在bev空间上通过loss函数的引导,产生响应较高的多处位置,标识为num_npos个grid位置;根据conference值的大小,选取其中topk个grid点,获得其位置和对应的bev grid特征;
19、将topk个bev 特征对应的位置生成锚点框,将锚点框通过位置编码操作转换为pe嵌入;
20、引入文本特征作为初始化的pe嵌入的额外补充特征,具体地,使用泊车场景下的高频用户文本提示构成文本提示设置,提取对应的文本特征获得该设置的文本特征集合,记为pv;通过将topk个bev grid特征与pv集合做点积操作,为每个grid寻找相关性最高的文本特征;
21、在分别获得grid对应锚点框pe和文本特征后,将两部分叠加在一起用于2层解码结构中各个模块查询 pe 嵌入的初始化。
22、本发明的有益效果在于,与现有技术相比,本发明采用类似于bevdet的方案,避免做显式的图像拼接,在特征空间采用快速易部署的方法进行多视角的特征融合和生成bev空间特征;能够同时给出前视图和bev图上的车位/障碍物等的检测及可行驶区域的提取。
23、本发明引入文本信息表征用户特定的泊车意图,通过文本信息和图像信息的交互融合,可以为用户搜索到带有特定用户意图的最佳推荐车位,避免了在某些场景下手动交互不便的问题。
24、本发明提供了在泊车场景下,融合文本意图和图像特征的泊车检测方案;hybridguided query generator(混合引导查询生成器)部分充分考虑文本特征和常规positionembedding(位置嵌入)的综合性,具有更有的初始化和收敛效果;文本和图像融合的模块结构,具有交叉往复的特点,能够在图像和文本的两条通路上,最终形成image-aware(图像感知)的text feature(文本特征)和text-ware(文本感知)的image feature(图像特征),是多模态模型的重要一环。
技术特征:
1.一种基于图像-文本融合增强的多模态泊车检测系统,其特征在于,包括多视角摄像头,基于cnn的摄像头特征提取模块,图像特征空间转换模块,文本模态信息,文本特征提取模块,多模态特征混合模块,多模态decoder模块;
2.根据权利要求1所述的基于图像-文本融合增强的多模态泊车检测系统,其特征在于,在多模态特征融合模块后引入bev空间相关loss,在多模态decoder模块后引入意图目标相关loss。
3.根据权利要求1所述的基于图像-文本融合增强的多模态泊车检测系统,其特征在于,基于cnn的摄像头特征提取模块,对于摄像头输入图像,使用基于cnn的backbone网络进行特征提取,并使用大规模的泊车场景开源数据集进行预训练;其中,backbone参数采用多摄像头共享的方式;最终每路摄像头输出c4和c3两种尺度的特征层用于后续的学习。
4. 根据权利要求3所述的基于图像-文本融合增强的多模态泊车检测系统,其特征在于,图像特征空间转换模块,采用全连接层实现特征空间的隐式转换,每个bev grid特征由整个图像视图特征进行加权组合构成,对全连接层转换过后的特征值进行重新转换和对应位置相加,得到bev grid特征;
5. 根据权利要求4所述的基于图像-文本融合增强的多模态泊车检测系统,其特征在于,多模态特征融合模块,包括text-to-bev通路和bev-to-text通路;在text-to-bev通路中,bev grid特征用于生成k和v特征,文本特征生成q,通过混合特征模块得到新的bevgrid特征,表示为new_bev_feature_scale0和new_bev_feature_scale1;
6. 根据权利要求5所述的基于图像-文本融合增强的多模态泊车检测系统,其特征在于,混合特征模块中,文本特征和bev grid特征通过交叉注意的方式进行融合。
7. 根据权利要求5所述的基于图像-文本融合增强的多模态泊车检测系统,其特征在于,多模态decoder模块,图像特征空间转换模块中的bf_scale0和bf_scale1构成多尺度的bev grid特征;将多尺度的bev grid特征通过多模态特征融合模块后,分别获得融合后的多尺度bev grid特征和文本特征;
8. 根据权利要求7所述的基于图像-文本融合增强的多模态泊车检测系统,其特征在于,基于transformer结构的目标检测框架中,使用混合引导查询位置嵌入生成器用于查询pe 嵌入的初始化生成;该模块包含文本特征和bev grid特征的锚点框两部分引导进行生成。
9. 根据权利要求8所述的基于图像-文本融合增强的多模态泊车检测系统,其特征在于,查询 pe 嵌入的初始化生成具体步骤:
技术总结
本发明公开了一种基于图像‑文本融合增强的多模态泊车检测系统,多视角摄像头输入图像信息,摄像头特征提取模块提取多视角摄像头图像特征,图像特征空间转换模块,将多视角摄像头图像融合至bev视角,实现多视角图像特征到bev特征的转换;输入文本模态信息,文本特征提取模块提取用户意图文本特征;多模态特征融合模块,获得文本特征和bev特征后,多模态特征通过多通路的特征融合模块进行充分交融;多模态decoder模块,基于transformer的解码结构,输出带有用户特定意图的泊车车位输出。本发明引入文本信息表征用户特定的泊车意图,通过文本信息和图像信息的交互融合,为用户搜索到带有特定用户意图的最佳推荐车位。
技术研发人员:韩晶,陈诚,张旸
受保护的技术使用者:奥特酷智能科技(南京)有限公司
技术研发日:
技术公布日:2025/3/20
- 还没有人留言评论。精彩留言会获得点赞!